Intel's Next-Gen Falcon Shores GPU to Consume 1500 W, No Air-Cooled Variant Planned
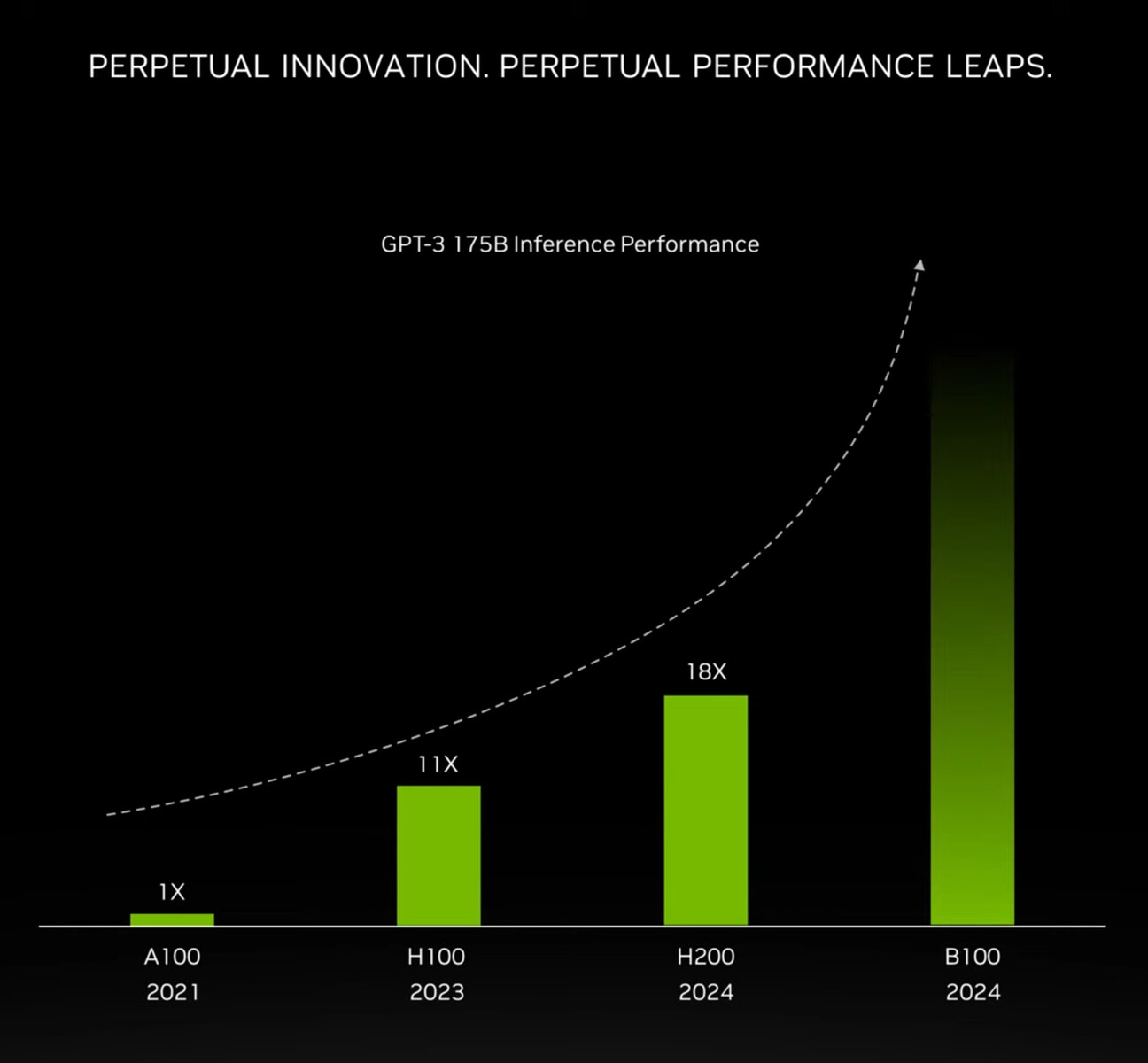
Intel's upcoming Falcon Shores GPU is shaping up to be a powerhouse for AI and high-performance computing (HPC) workloads, but it will also be an extreme power hog. The processor, combining Gaudi and Ponte Vecchio successors into a single GPU, is expected to consume an astonishing 1500 W of power - more than even Nvidia's beefy B200 accelerator, which draws 1000 W. This immense power consumption will require advanced cooling solutions to ensure the Falcon Shores GPU operates efficiently and safely. Intel's partners may turn to liquid cooling or even full immersion liquid cooling, a technology Intel has been promoting for power-hungry data center hardware. The high power draw is the cost of the Falcon Shores GPU's formidable performance promises. Intel claims it will deliver 5x higher performance per watt and 5x more memory capacity and bandwidth compared to its Ponte Vecchio products.
Intel may need to develop proprietary hardware modules or a new Open Accelerator Module (OAM) spec to support such extreme power levels, as the current OAM 2.0 tops out around 1000 W. Slated for release in 2025, the Falcon Shores GPU will be Intel's GPU IP based on its next-gen Xe graphics architecture. It aims to be a major player in the AI accelerator market, backed by Intel's robust oneAPI software development ecosystem. While the 1500 W power consumption is sure to raise eyebrows, Intel is betting that the Falcon Shores GPU's supposedly impressive performance will make it an enticing option for AI and HPC customers willing to invest in robust cooling infrastructure. The ultra-high-end accelerator market is heating up, and the HPC accelerator market needs a Ponte Vecchio successor.
Intel may need to develop proprietary hardware modules or a new Open Accelerator Module (OAM) spec to support such extreme power levels, as the current OAM 2.0 tops out around 1000 W. Slated for release in 2025, the Falcon Shores GPU will be Intel's GPU IP based on its next-gen Xe graphics architecture. It aims to be a major player in the AI accelerator market, backed by Intel's robust oneAPI software development ecosystem. While the 1500 W power consumption is sure to raise eyebrows, Intel is betting that the Falcon Shores GPU's supposedly impressive performance will make it an enticing option for AI and HPC customers willing to invest in robust cooling infrastructure. The ultra-high-end accelerator market is heating up, and the HPC accelerator market needs a Ponte Vecchio successor.