Wednesday, September 23rd 2009

LucidLogix Fires up Multi-GPU Computing With Faster, More Flexible HYDRA 200 Chip
LucidLogix (Lucid) today introduced the HYDRA 200 real time distributed processing engine designed to bring multi-GPU computing to the masses.
For the first time ever, motherboard, graphics card manufacturers and users can have the flexibility to use different combinations of GPUs from AMD (ATI) and NVIDIA in notebooks and PCs. The solution delivers faster 3D graphics at consumer price points.
The new HYDRA 200 SoC is Lucid's second generation parallel graphics processor that works with any GPU, CPU or chipset to provide scalable 3D graphics performance in a multi-GPU computing environment. On display for the first time at IDF 2009 (booth 213) HYDRA 200 is faster, more flexible, smaller and more power-efficient than its predecessor silicon, the HYDRA 100. "We've further refined our HYDRA engine and made it faster and more flexible, allowing for a near limitless combination of GPU's," said Lucid vice president of research and development, David Belz. "HYDRA 200 allows the consumer to get more 'bang for their GPU buck' by extending the life of their current GPU investment, providing even faster graphics performance and later upgrading their system with whatever card they choose." Until now, multi-GPU systems have been graphics vendor specific and generally require the consumer to be fairly technically savvy. With Lucid HYDRA 200, OEMs can offer custom configurations at different price/performance targets, and consumers will be able to easily add graphics hardware to achieve an overall performance boost without the worry of compatibility.
"We've further refined our HYDRA engine and made it faster and more flexible, allowing for a near limitless combination of GPU's," said Lucid vice president of research and development, David Belz. "HYDRA 200 allows the consumer to get more 'bang for their GPU buck' by extending the life of their current GPU investment, providing even faster graphics performance and later upgrading their system with whatever card they choose." Until now, multi-GPU systems have been graphics vendor specific and generally require the consumer to be fairly technically savvy. With Lucid HYDRA 200, OEMs can offer custom configurations at different price/performance targets, and consumers will be able to easily add graphics hardware to achieve an overall performance boost without the worry of compatibility.
Gamers with a need for speed now have a solution that's optimized for their performance requirements by allowing them to choose the right chip for the job, or simply upgrade without throwing away the old one. HYDRA 200 currently supports Windows Vista and Windows 7 operating systems as well as DirectX 9.0c and 10.1 standard APIs and is DirectX 11 ready.
HYDRA 200 Tech Specs
The adaptive and dynamic parallel graphics load-balancing scheme of HYDRA 200 resolves bottlenecks in the system and optimizes the usage of GPU resources with minimal power consumption. HYDRA 200 is a 65nm PCIe compatible SoC that also features:
HYDRA 200 Availability
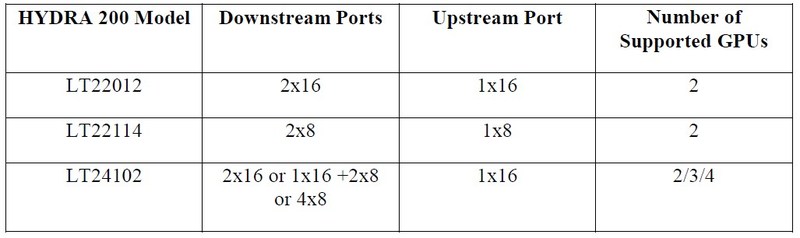
With universal GPU support and a variety of configurations, the HYDRA 200 makes system integration swift and worry-free. HYDRA 200 is available now for reference designs in three models: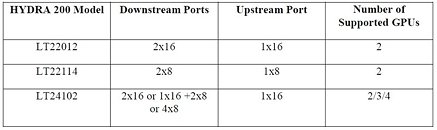
Source:
LucidLogix
For the first time ever, motherboard, graphics card manufacturers and users can have the flexibility to use different combinations of GPUs from AMD (ATI) and NVIDIA in notebooks and PCs. The solution delivers faster 3D graphics at consumer price points.
The new HYDRA 200 SoC is Lucid's second generation parallel graphics processor that works with any GPU, CPU or chipset to provide scalable 3D graphics performance in a multi-GPU computing environment. On display for the first time at IDF 2009 (booth 213) HYDRA 200 is faster, more flexible, smaller and more power-efficient than its predecessor silicon, the HYDRA 100.

Gamers with a need for speed now have a solution that's optimized for their performance requirements by allowing them to choose the right chip for the job, or simply upgrade without throwing away the old one. HYDRA 200 currently supports Windows Vista and Windows 7 operating systems as well as DirectX 9.0c and 10.1 standard APIs and is DirectX 11 ready.
HYDRA 200 Tech Specs
The adaptive and dynamic parallel graphics load-balancing scheme of HYDRA 200 resolves bottlenecks in the system and optimizes the usage of GPU resources with minimal power consumption. HYDRA 200 is a 65nm PCIe compatible SoC that also features:
- Low power use of under 6W, making it ideal for graphic cards, notebooks or desktops as there is no need for a special heatsink
- A small footprint (18-22mm) that allows for a compact design
- GPU connector free, making it easy to integrate into systems
- Supports multiple display configurations
- Universal GPU, CPU and chipset support
- For systems using dual, tri or quad GPU combinations
HYDRA 200 Availability
With universal GPU support and a variety of configurations, the HYDRA 200 makes system integration swift and worry-free. HYDRA 200 is available now for reference designs in three models:
38 Comments on LucidLogix Fires up Multi-GPU Computing With Faster, More Flexible HYDRA 200 Chip
Also, NF200 does not do the same thing.
1. Get draw commands
2. Split commands to both cards (if not doing AFR then dissect the image for the gpus to render their part).
3. Send data to both cards
4. Both cards render their part
5. Card 2 sends its data to card one for combining before sending to VDU.
Hydra:
1. Get draw commands
2. Detect different load capabilities on cards
3. Split commands to both cards (this will use a similar part to AFR i believe, so each card does a whole frame instead of tiled/split frames like super AA can do).
4. Send data to both cards
5. Both cards render their part
6. Card 2 sends its data to hydra which rediects it to card 1 (simple connection, not any latency) and the frame is interjected between frames generated by card 1 to the VDU (again very simple, no real latency).
With both of these setups the overall latency is going to be so close i'd say it will be indistinguishable. The hydra chip is meant to split the directX commands between the cards which are allowed to render the image using their own methods (if different). The image is then simply sent to be interjected between frames by card 1 - due to the hydra splitting the workload properly then you don't have to worry about rejoining parts of the same frame from different cards, or having to assume the cards run at a similar/same speed and having to sync the frames between the two properly (which is the cause of a lot of the overhead in current setups).
To split the data the hydra chip doesn't have to do too much work - once it knows the relative capabilities of each card it can simply direct the directx commands between them with no extra work needed - i.e. if card 1 is twice as fast as card 2 you just do:
Draw 1 -> card 1
Draw 2 -> card 1
Draw 3 -> card 2
Draw 4 -> card 1
Draw 5 -> card 1
Draw 6 -> card 2
Which isn't too expensive as you just direct the command down the apropriate pci-e connection.
I may be understanding their implementation wrong of course but from what i've read this is how it will be working.
In action.
Showing output of one GPU on the right, completed frame on the left.
Instead of a brute method of splitting work, the scene is intelligently broken down. Different amounts of RAM per card will work because textures don't need to be in memory on all cards.
you cant mix a DX11 and a DX10 card and expect to run DX11 games, for example.
as for the rest of it, it gives performance boosts (each card can use all its ram, hence its 'additive' - poor word, but you get the meaning) and it lets you say, crossfire a 3870 with a 4870