Monday, July 11th 2011

AMD FX-8130P Processor Benchmarks Surface
Here is a tasty scoop of benchmark results purported to be those of the AMD FX-8130P, the next high-end processor from the green team. The FX-8130P was paired with Gigabyte 990FXA-UD5 motherboard and 4 GB of dual-channel Kingston HyperX DDR3-2000 MHz memory running at DDR3-1866 MHz. A GeForce GTX 580 handled the graphics department. The chip was clocked at 3.20 GHz (16 x 200 MHz). Testing began with benchmarks that aren't very multi-core intensive, such as Super Pi 1M, where the chip clocked in at 19.5 seconds; AIDA64 Cache and Memory benchmark, where L1 cache seems to be extremely fast, while L2, L3, and memory performance is a slight improvement over the last generation of Phenom II processors.


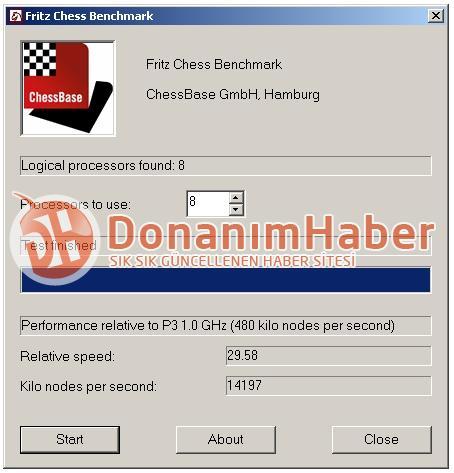
 Moving on to multi-threaded tests, Fritz Chess yielded a speed-up of over 29.5X over the set standard, with 14,197 kilonodes per second. x264 benchmark encoded first pass at roughly 136 fps, with roughly 45 fps in the second pass. The system scored 3045 points in PCMark7, and P6265 in 3DMark11 (performance preset). The results show that this chip will be highly competitive with Intel's LGA1155 Sandy Bridge quad-core chips, but as usual, we ask you to take the data with a pinch of salt.
Moving on to multi-threaded tests, Fritz Chess yielded a speed-up of over 29.5X over the set standard, with 14,197 kilonodes per second. x264 benchmark encoded first pass at roughly 136 fps, with roughly 45 fps in the second pass. The system scored 3045 points in PCMark7, and P6265 in 3DMark11 (performance preset). The results show that this chip will be highly competitive with Intel's LGA1155 Sandy Bridge quad-core chips, but as usual, we ask you to take the data with a pinch of salt.




Source:
DonanimHaber








317 Comments on AMD FX-8130P Processor Benchmarks Surface
The line is blurred definately, but you can call BD module an 1 core as easily as you can call it a 2 core. Because of the single fetch unit I'm more inclined to call it 1 core.
www.xbitlabs.com/news/cpu/display/20110313113629_Four_AMD_Bulldozer_Chips_Incoming_Details_Revealed.htmlIt's an 8 core
It has 4 fetch/decode/store units not one per module
Phenom II could only do 3 fetch/decodes per clock or 3 stores per clock
Note the DDR3 on phenom only gives it a .2 latency boost on L2. It would win either way.
Biggest difference I see is the read and copy are switched. Overall it appears AMD is faster on cache as well. Yet super pi still does better on 775 despite all that. So really what purpose does super pi have here in comparing AMD and Intel chips if the architecture is making a bigger impact than the memory speeds?
x87 vs SSE
SSE wins
Name applications that came out this year that uses x87
So of course there is no x87 programs. Why would anyone do that.
support.amd.com/us/Processor_TechDocs/47414.pdf*goes away to get more popcorn*
Anyway, the point was that SuperPi can directly relate to SOME APPs and how they can perform, and is in no way meant to be used as a comparison for all performance scenarios.
And I do have screenshots from that platform. I'll not fall for the obvious problems in your compare; your troll failed, sry.:laugh:
@cadaveca
isn't it the cache on Amd chips that is significantly lower performing and not Memory (ram) bandwidth, somuch. from what i've seen memory bandwidth isn't that far behind Intel on Amd. Also Super pi tests at or below chip cache should be only limited by cache bandwidth/latency. the larger tests should show combined effects from cache and memory.
From my understanding if Amd were to go out of bussiness then Intel would get carved up into bite sized chunks that would have to compete with eachother. Anyway why wuld you want the competion to fold, it just leads to higher prices. ideally you want at least 3 major players in a market each controlling roughly equal market share. that way you get lots of competition and good prices.
I got confused with this picture
You were right but my mind remembered something else
64KB L1I is divided by 2 for each core 32KB L1I per core just like Intel
SuperPI only utilizes x87 for its codebase, therefore thats whats run on both processors in that benchmark.
It makes no sense for any modern uarch strive for x87 prowess ... so, Im pretty sure superPI is the last thing on AMD's mind...if it ever was to begin with =P
It just so happens SB is better at x87 stuff ... who cares!
I wish people would drop superpi all together its meaningless nowadays...yet people use it to leave a good or bad taste in their mouth about an upcoming uarch....freakin retarded way to make first impressions of a new uarch!!!
All FX Chips are overclockable
95 Watts FX-X110, 125 Watts FX-8130Pexactly
It's ok to have some confidence in your assumptions but you take it too far. Thinking I'm trolling you? Wth man.
You started of saying AMD had better ram performance, but it does not; it only looks that way in your screenshots because you've got DDR2 VS DDR3. That's using skewed results that emulate what you want, rather than the truth. Start with factual comments, and I'll not call you a troll.
I've been doing cache speed compares since SKT754. if you search other forums for my posts, you'll find I even comapred 1MB vs 2MB CPUs. You're not informing me(or anyone else) of anything.
The thing is, for me it would be 4 cores with 8 integer clusters but not 8 cores, because for me a 2 core is CMP, 2 identical cores who share at most L3 cache for data sharing between cores, hyper-transport and Integrated Memory Controller and in some case IGP like in Llano or SB.
Thats why I think they would be better of calling it 4 cores with AMD-threading or something like that and not 8 cores just because some small part of core die, just 12% is doubled what is not a core but an integer unit(cluster) just a part of it. Intel SB with HT also has an increase in die size thanks to HT meaning something was doubled but not as much as in an AMD modul, yet no one calls it that way even if it can virtually work with 8 threads. Why doubling integer units means double amount of cores but doubling registers and some other things means just 4 cores?
(sorry i couldn't find what was actually doubled except some registers in P4 but from that time HT did a big improvement even if I still think modul is the right choice and not HT)
devguy you wrote L3 Cache, the Integrated Memory Controller, and the HyperTransport link are shared and thanks to that Deneb should be just one core if BD isn't an 8 core or something in this sense. Thats a bad comparison in my opinion.
L3 cache is there specifically just so each core can access data from the other, what other reason would be there if L2 cache is faster, so making it larger would be better for the performance than creating a new slower cache.
IMC is for a CPU to communicate with the memory modules, so why should each core have their own IMC?
Hyper-transport or intel equivalent is the same as IMC just a communication between cpu and northbridge, southbridge or other cpu.
Not one of them was ever included in a core as I can recall at least IMC and HTt.
Its enough if you just look at the BD modul and deneb core and you can see the difference is just twice the amount of integer clusters, but just integer clusters were never called cores so why should be now.
2 x 128bits SSE(1x256 bit AVX Add+Multiply)
2 x 16KB L1D
1 x 64KB L1I instead of 1 x 32KB L1I
64+64 and 32+32+32+32 registers instead of 64 and 32+32 registers
512KB(Phenom II) to 1MB L2(Regor/Llano) to 2MB L2(Zambezi)
To lazy to look up more that was doubled
The formula has changed a bit
Two Identical cores now use L2(For Zambezi)
Several Modules now use L3(For Zambezi)
Rather old dissection
ok, can u clear something up for me. Doesn't super pi mostly stress cache bandwidth/latency esp at lower tests like below 8mb. I thought it was Amd's cache that was slower than intels and not so much the Imc or does Qpi significantly outpace it.just curious, you were discussing phenom mem perf vs sandy or something earlier. i thought it might have some relevance to this. also below 8m the cache is whats being tested and after that both cache and the rest or the mem sub-system. i'm not sure what im saying anymore.. too tired.
games.. look at my rig. I spent $70 on the cpu and $180 on the Gfx. :D
I raised this point earlier..I care about game perforamcne, so until I get game perforamcne compares, none of this really matters to me. Bulldozer could be the slowest CPU ever, but if in some magical way it makes my games play better, then it's a win, for me. So, what's really improtant for you? Games, or something else?
The Aida cache and memory benchmark is a disaster for BD, SuperPi the same and the other benchmarks are done at unknown clocks therefore we don’t have a true comparison with SB.
We’ll have to wait a little longer to realy compare BD and SB.