- Joined
- Oct 9, 2007
- Messages
- 46,387 (7.67/day)
- Location
- Hyderabad, India
| System Name | RBMK-1000 |
|---|---|
| Processor | AMD Ryzen 7 5700G |
| Motherboard | ASUS ROG Strix B450-E Gaming |
| Cooling | DeepCool Gammax L240 V2 |
| Memory | 2x 8GB G.Skill Sniper X |
| Video Card(s) | Palit GeForce RTX 2080 SUPER GameRock |
| Storage | Western Digital Black NVMe 512GB |
| Display(s) | BenQ 1440p 60 Hz 27-inch |
| Case | Corsair Carbide 100R |
| Audio Device(s) | ASUS SupremeFX S1220A |
| Power Supply | Cooler Master MWE Gold 650W |
| Mouse | ASUS ROG Strix Impact |
| Keyboard | Gamdias Hermes E2 |
| Software | Windows 11 Pro |
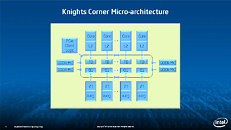
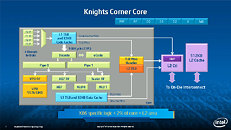
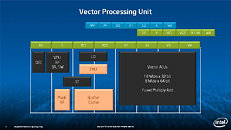
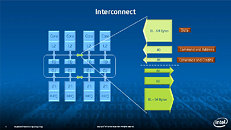
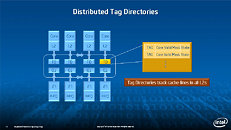
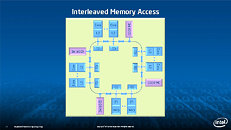
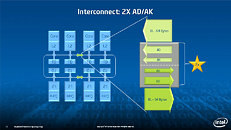
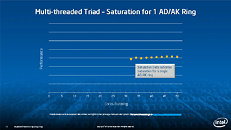
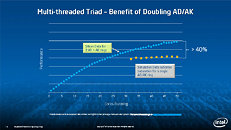
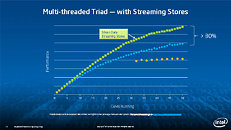
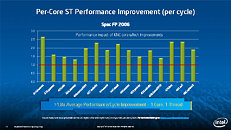
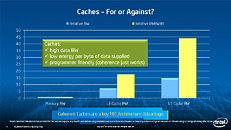
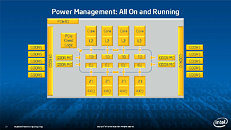
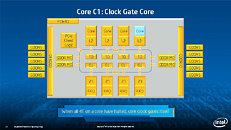
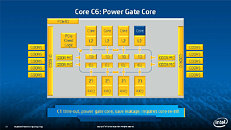
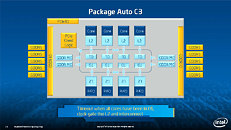
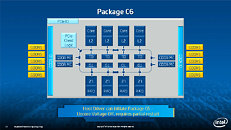
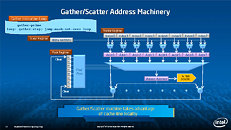
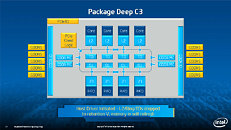
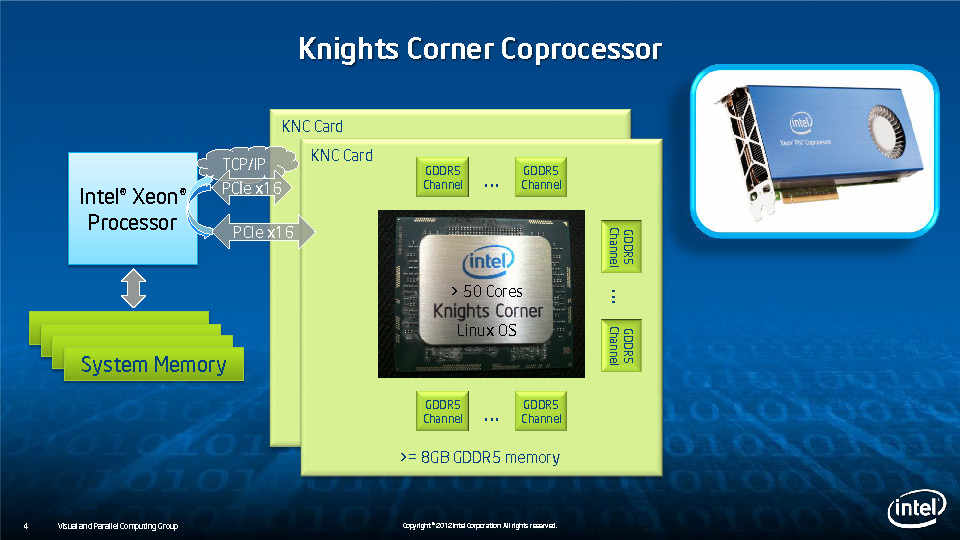
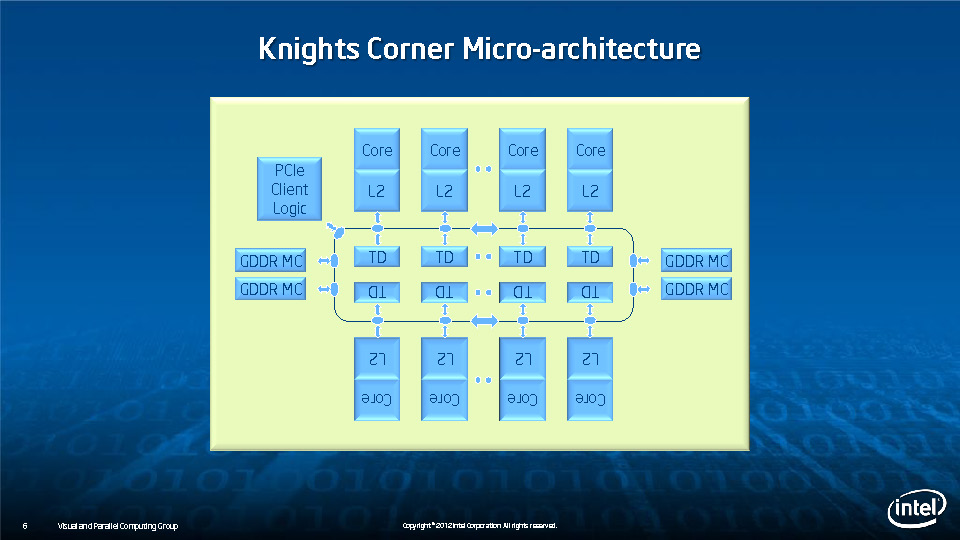
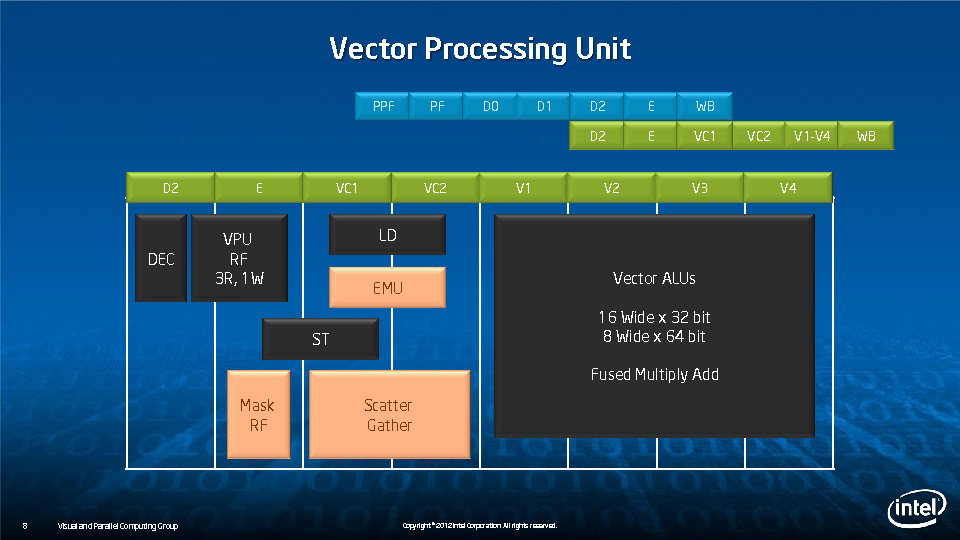
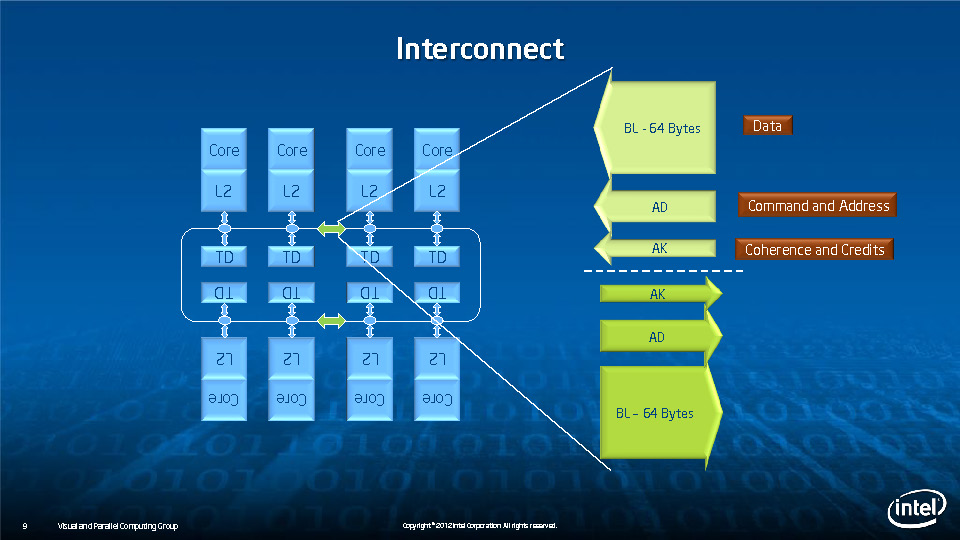
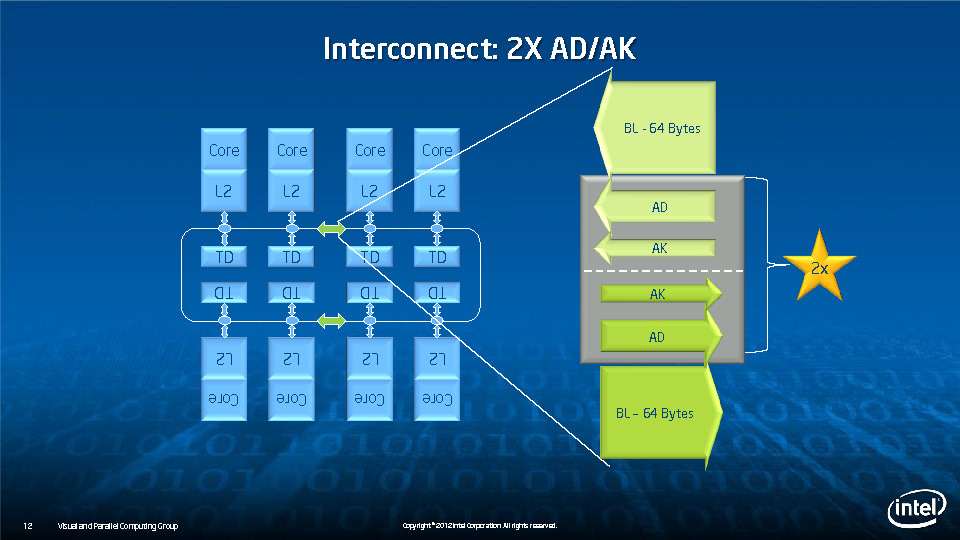
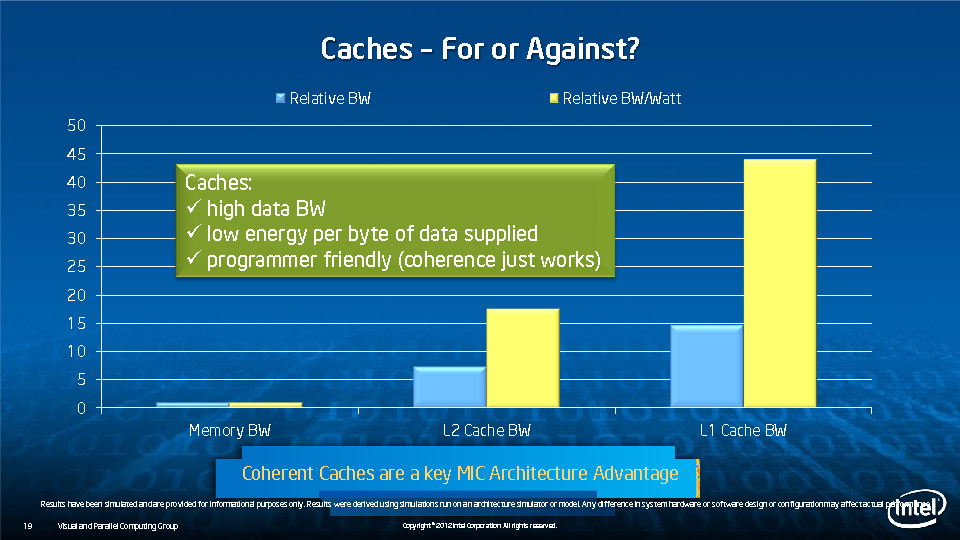
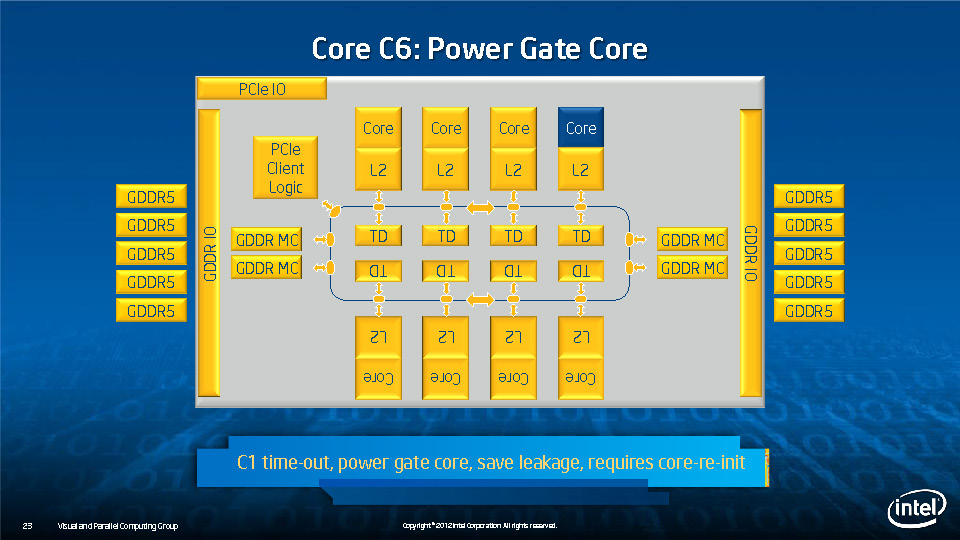
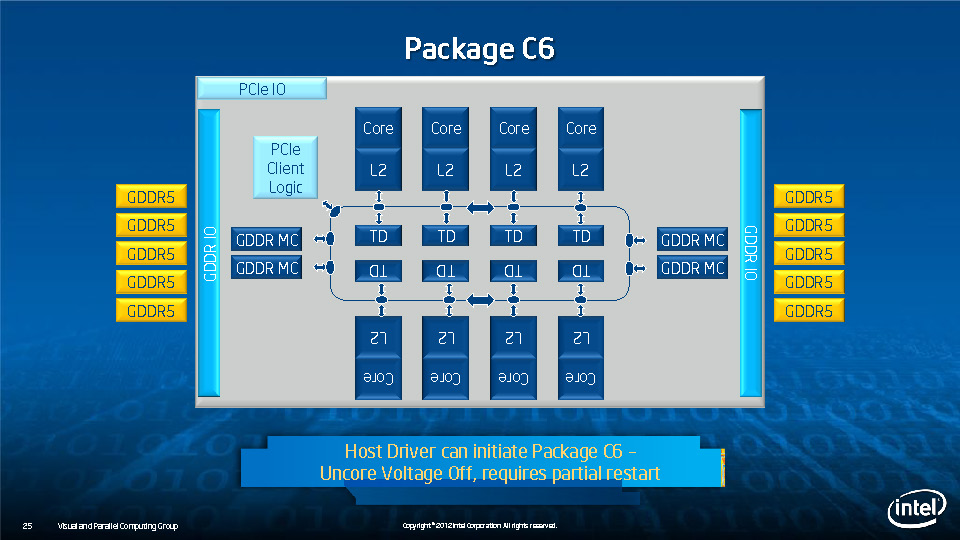
During HotChips symposium, George Chrysos, the leading architect of Intel Xeon Phi co-processor shared the new architecture details of upcoming Intel's HPC powerhouse. Designed for highly-parallel applications, Intel Xeon Phi co-processor based on Intel Mani Integrated Core architecture will deliver the combination of industry leading performance per watt with the ability to re-use the existing code and applications without necessity of re-writing them.
Equipped with more than 50 cores and built using Intel's latest 22nm 3D Tri-gate transistor technology, new co-processors will be in production this year with first supercomputers from top500 list already taking advantage of this technology. In his blog here, George shares his aspirations and goals during designing the co-processor and summarizes all new disclosed information. The HotChips presentation is also available below.











View at TechPowerUp Main Site
Equipped with more than 50 cores and built using Intel's latest 22nm 3D Tri-gate transistor technology, new co-processors will be in production this year with first supercomputers from top500 list already taking advantage of this technology. In his blog here, George shares his aspirations and goals during designing the co-processor and summarizes all new disclosed information. The HotChips presentation is also available below.






















View at TechPowerUp Main Site


")







