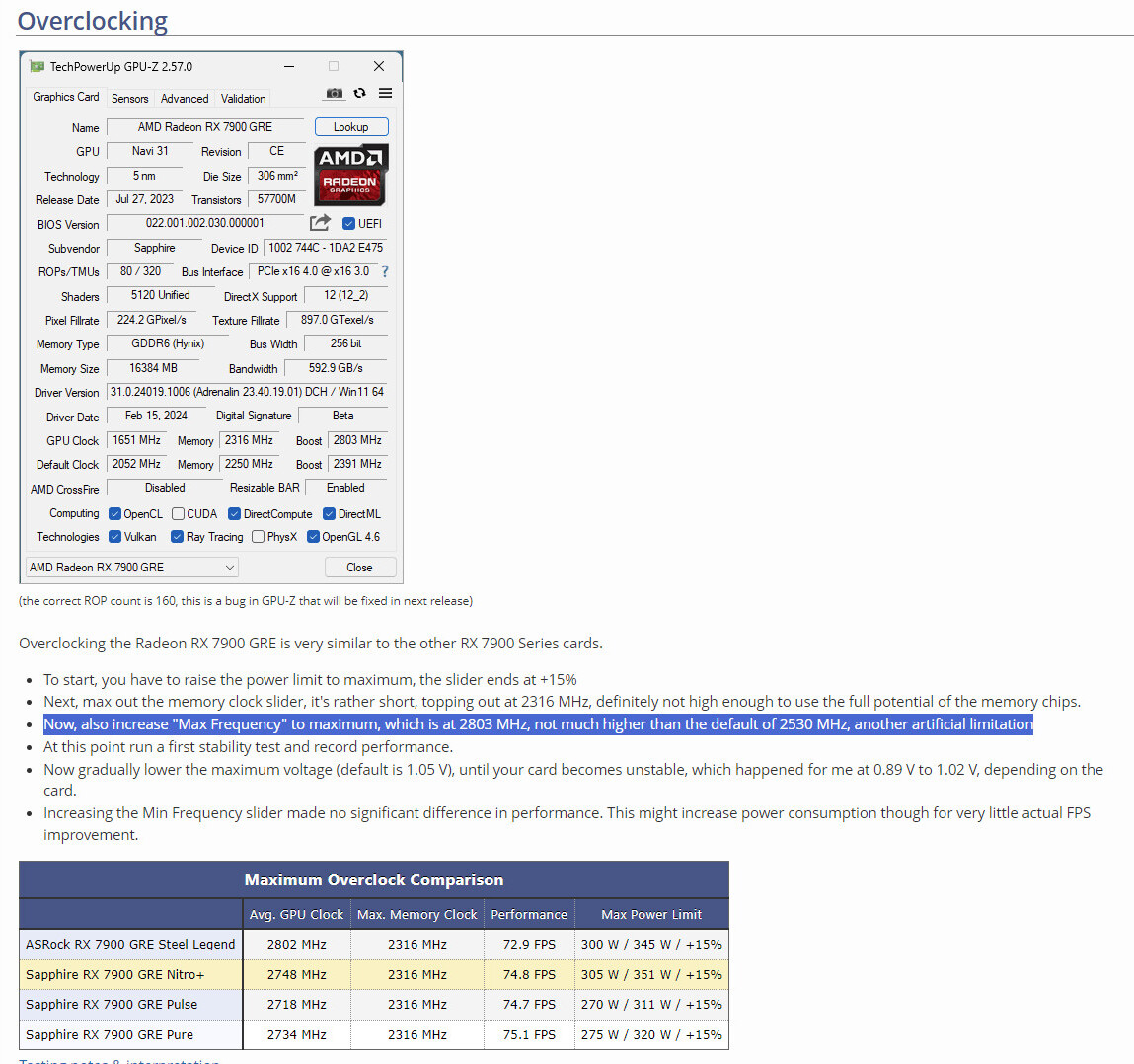
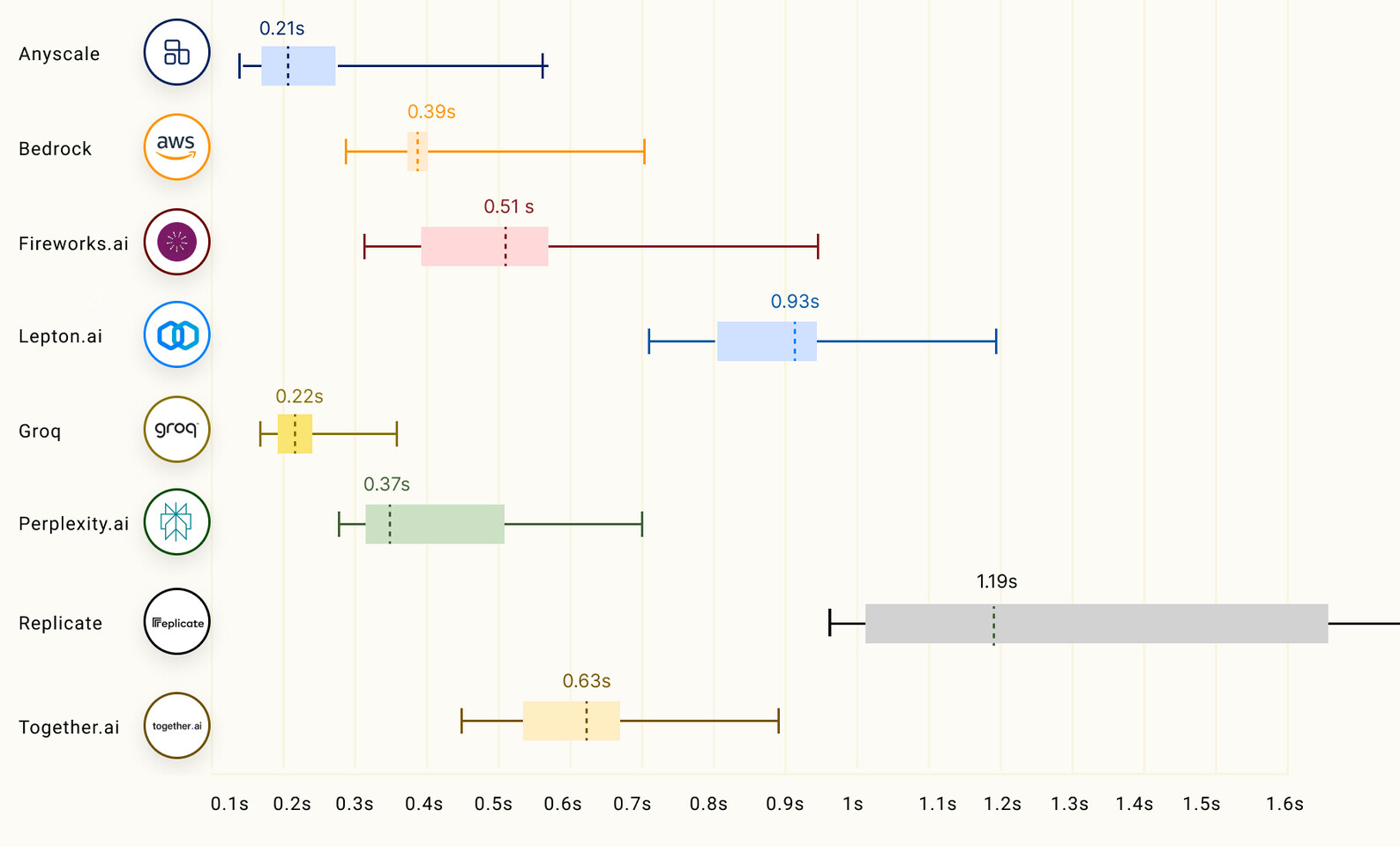
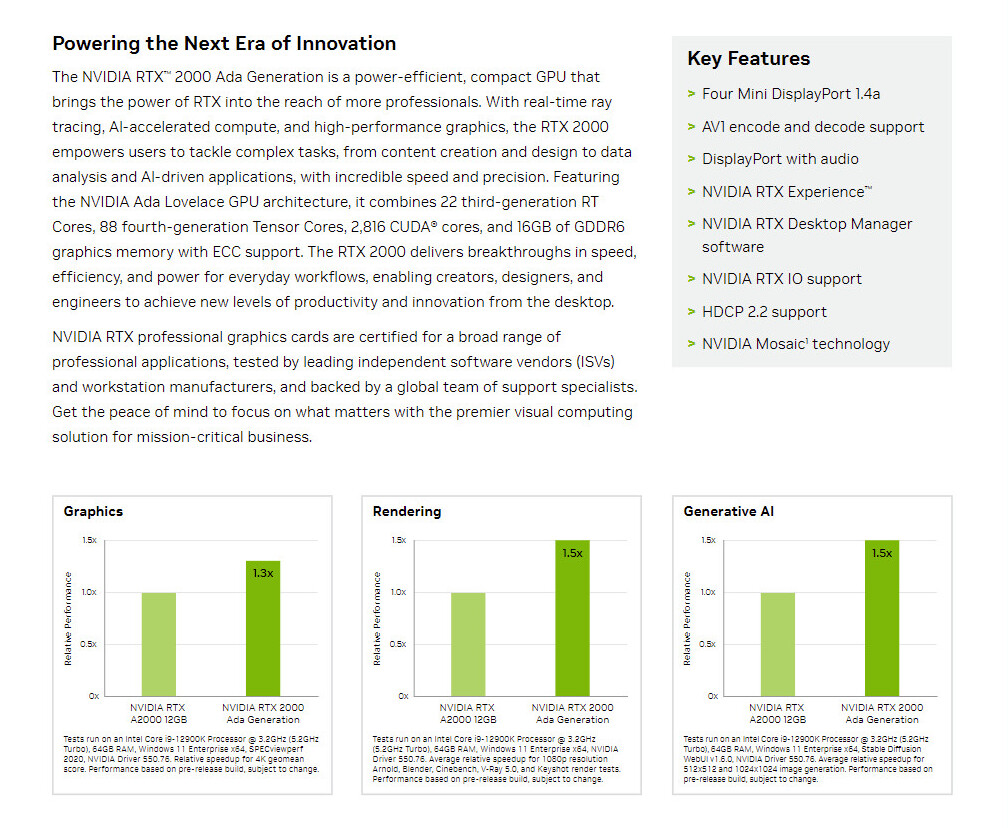
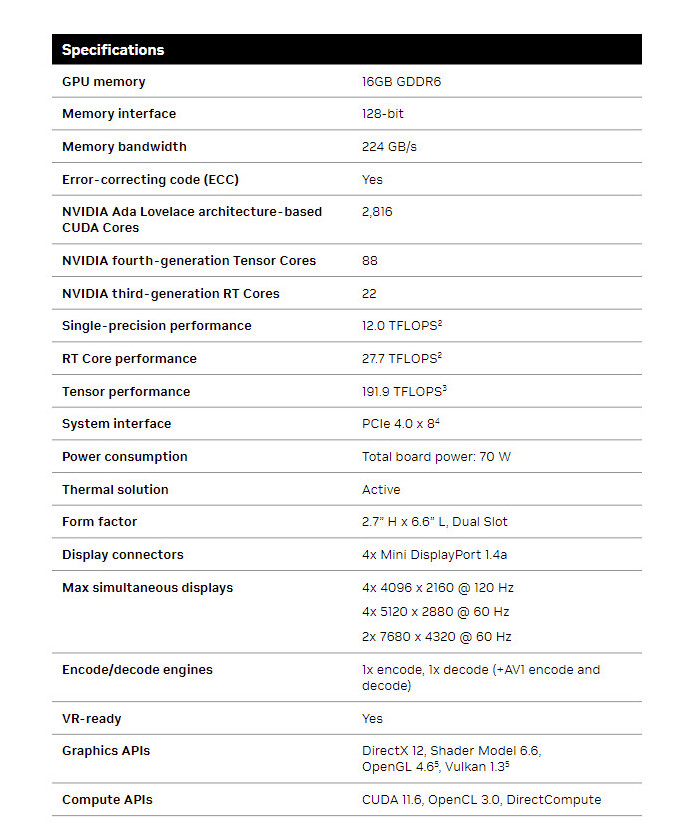
Google: CPUs are Leading AI Inference Workloads, Not GPUs
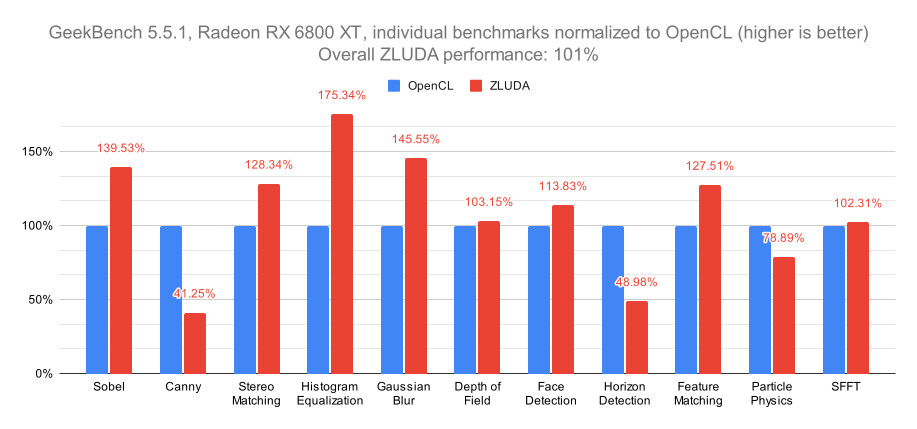
The AI infrastructure of today is mostly fueled by the expansion that relies on GPU-accelerated servers. Google, one of the world's largest hyperscalers, has noted that CPUs are still a leading compute for AI/ML workloads, recorded on their Google Cloud Services cloud internal analysis. During the TechFieldDay event, a speech by Brandon Royal, product manager at Google Cloud, explained the position of CPUs in today's AI game. The AI lifecycle is divided into two parts: training and inference. During training, massive compute capacity is needed, along with enormous memory capacity, to fit ever-expanding AI models into memory. The latest models, like GPT-4 and Gemini, contain billions of parameters and require thousands of GPUs or other accelerators working in parallel to train efficiently.
On the other hand, inference requires less compute intensity but still benefits from acceleration. The pre-trained model is optimized and deployed during inference to make predictions on new data. While less compute is needed than training, latency and throughput are essential for real-time inference. Google found out that, while GPUs are ideal for the training phase, models are often optimized and run inference on CPUs. This means that there are customers who choose CPUs as their medium of AI inference for a wide variety of reasons.

On the other hand, inference requires less compute intensity but still benefits from acceleration. The pre-trained model is optimized and deployed during inference to make predictions on new data. While less compute is needed than training, latency and throughput are essential for real-time inference. Google found out that, while GPUs are ideal for the training phase, models are often optimized and run inference on CPUs. This means that there are customers who choose CPUs as their medium of AI inference for a wide variety of reasons.