Monday, November 22nd 2010

AMD Cayman, Antilles Specifications Surface
At last, specifications of AMD's elusive Radeon HD 6970 and Radeon HD 6990 graphics accelerators made it to the internet, with slides exposing details such as stream processor count. The Radeon HD 6970 is based on a new 40 nm GPU by AMD, codenamed "Cayman". The dual-GPU accelerator being designed using two Cayman GPUs is codenamed "Antilles", and carries the product name Radeon HD 6990.
Cayman packs 1920 stream processors, spread across 30 SIMD engines, indicating the 4D stream processor architecture, generating single-precision computational power of 3 TFLOPs. It packs 96 TMUs, 128 Z/Stencil ROPs, and 32 color ROPs. Its memory bandwidth of 160 GB/s indicates that it uses a 256-bit wide GDDR5 memory interface. The memory amount, however, seems to have been doubled to 2 GB on the Radeon HD 6970. Antilles uses two of these Cayman GPUs, combined computational power of 6 TFLOPs, a total of 3840 stream processors, total memory bandwidth of 307.2 GB/s, a total of 4 GB of memory, load and idle board power ratings at 300W and 30W, respectively.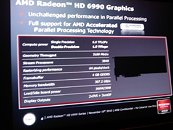
Source:
3DCenter Forum
Cayman packs 1920 stream processors, spread across 30 SIMD engines, indicating the 4D stream processor architecture, generating single-precision computational power of 3 TFLOPs. It packs 96 TMUs, 128 Z/Stencil ROPs, and 32 color ROPs. Its memory bandwidth of 160 GB/s indicates that it uses a 256-bit wide GDDR5 memory interface. The memory amount, however, seems to have been doubled to 2 GB on the Radeon HD 6970. Antilles uses two of these Cayman GPUs, combined computational power of 6 TFLOPs, a total of 3840 stream processors, total memory bandwidth of 307.2 GB/s, a total of 4 GB of memory, load and idle board power ratings at 300W and 30W, respectively.

134 Comments on AMD Cayman, Antilles Specifications Surface
2x850Mhz
2x4800Mhz
2x800 shaders
2xtmus
2xrops
??
Especially it doesn't need 2x850Mhz if it has 2xthe shaders. As long as it has 2x the Gflops (shaders x mhz x 2) it "should" be twice as fast. It all depends on the architecture tho. Fermi is like that, twice the flops, exactly twice the performance. It also usually means 2x the die area. With AMD 2x shaders does not equal 2x the performance, but usually they have also managed to not double up the die area.
AMD= efficient at manufacturing time
Nvidia= efficient at execution time
Cayman is MORE than twice the theoretical math power of Barts, due to the 4-D switch.
How is the set-up engine that can barely feed Barts work on Cayman? Does it not have to have twice the output as the Barts set-up, in order to be able to feed Cayman?
Of course the previous incarnation sucked! Explain why they were unable to fully utilize vertex setup, and you have your answer? It's all very obvious!
But, what the kicker here is that although Barts is far more efficient that Cypress, this efficiency increase is almost 100% in the setup engine. In fact, we all know that this is really the only change from Cypress to Barts...besides memory control.
So, the tidbit if info you may be missing is that although Barts is 1120 shaders, AMD also had a design with 1280 shaders(another two SIMD clusters), but limitation in the set-up engine limited the performance increase to just 2%...2%, from a 12.5% increase in math power!
Also of note is that Bart's memory controller is 50% of the functionality of Cypress(literally takes up hallf the die space), and this led to the reduction of memory speeds in the Barts chips(the smaller controller cannot maitain high speeds very well)....but even so, performance is barely impacted...unless you run high resolutions(and hence Barts being the new "mainstream"). So while the lack of 7Gbps memory may concern some, it should only really affect a small part of the marketplace.
Cayman Confirmed To Be Using VLIW4 SP Arrangement...
Don't you have a tweaker to design?
You want another chip like TWKR, tell JF_AMD to give me a job.:laugh: Seems AMD might need some new blood in marketing anyway.
EDIT: And I think that the answer to my question is precisely in those buffers on the set-up output. After reading the scarce info on those buffers in Techreport and Anandtech, it looks like they are just a few series of FIFO registers and that's probaby the info I was missing. The vertex/raster engine can generate many polys a second, but has apparently not enough place to store them until other units finish their work on previous ones. Hence it stays stalled for long periods of time. Doubling the engine doubled the buffers and with them the performance. Maybe I'm wrong on that, but it IS something I thought was different and could explain why. For the record, previously I thought the buffer between setup and the rest of the chip was an actual cache, biderectional to be more precise.It was also 128 bit and 16 ROPs, that's where the limitation was most probaby, not the setup engine. Based on the relation of performance per clock between HD6870 vs HD5850 vs HD5870 I would say that the set-up limit was somewhere between 1120 and 1440 SPs. Probably closer to 1440, because the HD5850 is significantly faster than HD6870 whn @900 Mhz.
You could be right in it the limit being cache, but also maybe an increase in set-up registers also allows for doubling of polygons per clock. In fact, I trust AMD wouldn't have added anything they did not need, purely based onthem being so limited by the process...Cayman is a HUGE-ASS chip.
:roll:
:shadedshu
*edit* actually looking at the crossfire review, even has the performance powercolor hinted too. 20-50% better than 5870 ( depending on resolution and game of course)
The potential is there for Cayman to do far more than just +50% of Cypress...it truly depends on how many of those shaders they can keep fed all the time. 5870 is rarely more than 60% loaded, even when it indicates that gpu laod is 100%...you can tell this by power consumption.
And yeah I know what you mean about guessing, if it was just up-scaled barts with the power to feed the shader it's simply the thing I was being silly about earlier :laugh: (or 70% improvement over 6870 if it scaled nicely, which thus far the 5d architecture has not as far as I'm aware )
It has to scale over 5870 by 60% in order to beat 580 in everything and 50% to win more then loose but not a straight up win .
This is one of the more interesting new gpu times IMO :cool:
Sorry for rambly post. I ramble when posting : ]
Assuming all shaders are fed 100% etc, can we work anything out from that? Like what it's optimal theoretical performance could be? :laugh:
So if the 6970 has around 3 TFLOPS of single-precision compute performance, it should be faster than the 4870x2?
?????
why would the 6970 be slower?