Sunday, October 14th 2018

AMD "Zen" Does Support FMA4, Just Not Exposed
With its "Zen" CPU microarchitecture, AMD removed support for the FMA4 instruction-set, on paper. This, while retaining FMA3. Level1Techs discovered that "Zen" CPUs do support FMA4 instructions, even through the instruction-set is not exposed to the operating system. FMA, or fused multiply add, is an efficient way to compute linear algebra. FMA3 and FMA4 are not generations of the instruction-set (unlike SSE3 and SSE4), but rather the digit denotes the number of operands per instruction. Support for both were introduced by AMD in 2012 with its FX-series processors, while Intel added FMA3 support in 2013 with "Haswell."
The exact reasons why AMD deprecated FMA4 with "Zen" are unknown, but some developers speculate it's because AMD's implementation of FMA4 is buggy, even though it's more efficient (33% more throughput). Intel's adoption of FMA3 made it more popular, and hence more stable over the years. Level1Techs used an OpenBLAS FMA4 test-program to confirm that feeding "Zen" processors with FMA4 instructions won't just return a "illegal instruction" error, but also the processor will go ahead and complete the operation. This is interesting because FMA4 isn't exposed as a CPUID bit, and the operating system has no idea the processor even supports the instruction. For linear algebra, FMA4 has proven more efficient than AVX in both single- and double-precision.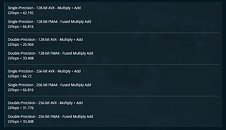
Sources:
Level1Techs (YouTube), Agner's CPU Blog
The exact reasons why AMD deprecated FMA4 with "Zen" are unknown, but some developers speculate it's because AMD's implementation of FMA4 is buggy, even though it's more efficient (33% more throughput). Intel's adoption of FMA3 made it more popular, and hence more stable over the years. Level1Techs used an OpenBLAS FMA4 test-program to confirm that feeding "Zen" processors with FMA4 instructions won't just return a "illegal instruction" error, but also the processor will go ahead and complete the operation. This is interesting because FMA4 isn't exposed as a CPUID bit, and the operating system has no idea the processor even supports the instruction. For linear algebra, FMA4 has proven more efficient than AVX in both single- and double-precision.

10 Comments on AMD "Zen" Does Support FMA4, Just Not Exposed
I took it as being 33% faster than Intel's version. My bad.Sorry bud, I had a comprehension error 101 lol.
There's wiki out there that explains the difference between 4 operand and 3 operand. FMA4 and FMA3 they all just do one job, compute 'd=a*b+c'. The only difference is that FMA4 stores result 'd' in a new register which is specified in the instruction, while FMA3 stores it by overwriting one of the three input registers. THEY DID THE SAME THING, just different ways of handling the result.
FMA4 has the advantage of programming flexibility, meaning there's more room for optimization, since the output and input do not interfere. But the room will never be anywhere near 33%. If you write x86 assembly code, you will understand. However FMA3 uses less transistors, easier to implement (means you can design it with less latency on silicon), so Intel jumped ship of FMA4 and chose FMA3.
I don't write BLAS code, to be honest. But I do think well-optimized FMA3 doesn't have much disadvantage. Because if the flexibility is not well utilized, then the FMA4 processors will be troubled by its chunkier and slower units.
Edit:
I just come up with a great analogy of this. We can call x86's ADD as 'ADD2', ARM's ADD as 'ADD3'. If you write 'ADD A,B' in x86, then it stores the result in A, meaning A=A+B. If you write 'ADD A,B,C' in ARM, then it is good old 'A=B+C'.
Sure ADD3 is more flexible, but I don't think ARM has 50% more throughput than x86.