- Joined
- Aug 19, 2017
- Messages
- 2,229 (0.91/day)
When NVIDIA announced its Grace CPU Superchip, the company officially showed its efforts of creating an HPC-oriented processor to compete with Intel and AMD. The Grace CPU Superchip combines two Grace CPU modules that use the NVLink-C2C technology to deliver 144 Arm v9 cores and 1 TB/s of memory bandwidth. Each core is Arm Neoverse N2 Perseus design, configured to achieve the highest throughput and bandwidth. As far as performance is concerned, the only detail NVIDIA provides on its website is the estimated SPECrate 2017_int_base score of over 740. Thanks to the colleges over at Tom's Hardware, we have another performance figure to look at.
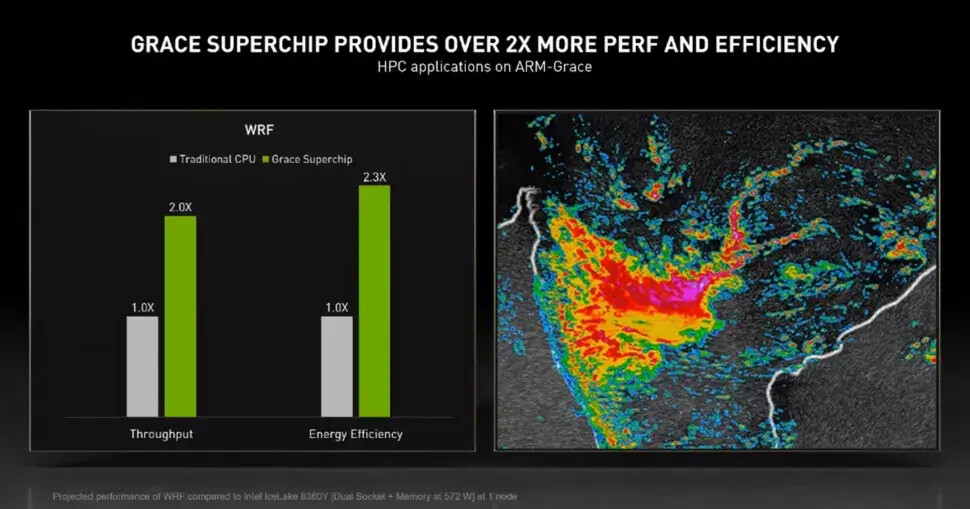
NVIDIA has made a slide about comparison with Intel's Ice Lake server processors. One Grace CPU Superchip was compared to two Xeon Platinum 8360Y Ice Lake CPUs configured in a dual-socket server node. The Grace CPU Superchip outperformed the Ice Lake configuration by two times and provided 2.3 times the efficiency in WRF simulation. This HPC application is CPU-bound, allowing the new Grace CPU to show off. This is all thanks to the Arm v9 Neoverse N2 cores pairing efficiently with outstanding performance. NVIDIA made a graph showcasing all HPC applications running on Arm today, with many more to come, which you can see below. Remember that NVIDIA provides this information, so we have to wait for the 2023 launch to see it in action.


View at TechPowerUp Main Site | Source
NVIDIA has made a slide about comparison with Intel's Ice Lake server processors. One Grace CPU Superchip was compared to two Xeon Platinum 8360Y Ice Lake CPUs configured in a dual-socket server node. The Grace CPU Superchip outperformed the Ice Lake configuration by two times and provided 2.3 times the efficiency in WRF simulation. This HPC application is CPU-bound, allowing the new Grace CPU to show off. This is all thanks to the Arm v9 Neoverse N2 cores pairing efficiently with outstanding performance. NVIDIA made a graph showcasing all HPC applications running on Arm today, with many more to come, which you can see below. Remember that NVIDIA provides this information, so we have to wait for the 2023 launch to see it in action.


View at TechPowerUp Main Site | Source



 )
) It'll turn out to be in one specific benchmark that's be re-optimized for these specific chips and in no way reflects real world performance.
It'll turn out to be in one specific benchmark that's be re-optimized for these specific chips and in no way reflects real world performance.
