You do know that any data coming out of an ALU or FPU needs to finish the pipeline before it can be fed again?
It actually doesn't, though that used to be the case. Today, fetch and decode chunks of instructions and then determine dependencies. We tag instructions as dependent upon others and try to reroute non-dependent instructions around them before then processing the dependent instruction.
For most instructions, the core knows (within reason) how long it should take to execute and get the result back, so we don't wait for the result - we schedule the instruction so that it is already ready to be fed into a pipeline when the result is available... we want the decoded instruction tagged and sitting in the scheduler - and we want the instruction whose result we need to carry a matching tag.
An add instruction takes a single cycle, but it takes time to get the result. Intel uses a bus they call, unimaginatively, but accurately, the "result bus." This bus is fed by the store pipelines and each execution pipeline. The load and execution pipelines can read results directly off this bus if the timing works out correctly.
So, A + B + C + D would execute as mov A, result; add B, result; add C, result; add D, result;.
One trick here, which is by no means obvious or necessarily done, would be to keep the instructions in two places. You keep a copy in the scheduler, tagged, as you send the dependent instruction down the pipelines one after the other, so the next instruction can get its result from the previous instruction from the result bus.
The way Intel describes what they do (despite admitting that the execution pipelines can read from the result bus) is to send the result back to the scheduler, where the dependent instruction is waiting for the data. I genuinely suspect they do both (otherwise there's no need for an execution pipeline to read from the result bus..)... it just depends on how dependably the execution while occur within a given time frame.
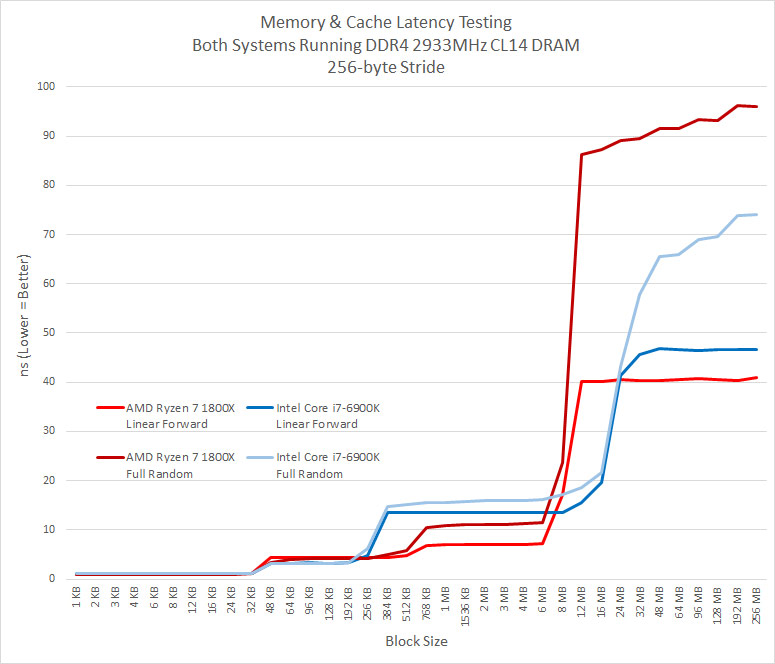
Judging by that image, there is no issue with L3 cache at all.
That image is using a 256-byte stride which hides the full effect of the random-access issue until it exceeds about the cache size as Ryzen can predict the access pattern well enough.
You can see the (unsurprising) excellent sequential performance (which is only 2.8ns on my 2700X) ... and them the abysmal random access performance.
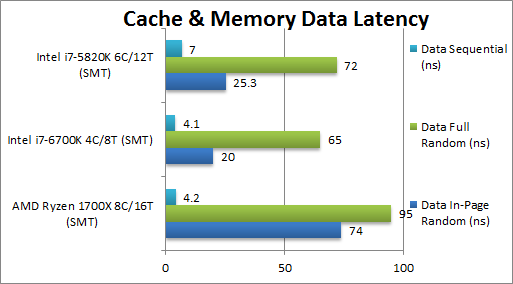
Intel's in-page random access performance is several times better. This is the cache performance issue that is hurting Ryzen - and it relates to how often the L3 prefetch ends up hitting the IMC instead of being able to stay within the L3. This happens increasingly more after a single core uses more than 4MiB of data. By 6MiB you have a ~50% miss rate that result in hitting memory latency.
My 2700X results are better - because my IMC latency is only 61.9ns with 3600MT/s memory.
If Zen 2 can bring that down by another 20ns while increasing how much L3 each core can access, it's going to be a big deal. My 2700X only has 9.5ns latency to the L3 - if I had 40ns latency to main memory and 16MiB of cache to access, in-page random access should fall to the 20~30ns region (depending on page size).
Intel is much better at utilizing their cache through a better front-end.
Zen's front end is extremely good. As is Intel's.
Zen's has higher throughput potential (8 uops vs 4 uops), but Intel has fusion - so that 4 uops is sometimes 7 uops... and Zen's 8 uops is sometimes 4 uops...
Intel's branch predictor seems to be better, but that's about it.
The first Zen bottleneck (if you want to call it that) is when Intel can dispatch 7 uops and Zen can only dispatch 6. Intel isn't always able to dispatch 7 uops, but Zen can never exceed 6. That's a potential 16.7% advantage to Intel.
The next Intel advantage is in their unified scheduler - which allows accessing results without going back to the scheduler. Zen, AFAICT, needs to send results back to the forwarding muxes or the PRF. This is only a couple cycles - and AMD makes up for it by having four ALU full featured pipelines and 6 independent schedulers. Being only 14 deep keeps things simple to manage, but it may mean results could need to be fetched from the L1D (3 cycle penalty) more often.
Data sharing between L3 caches, which was what we were talking about, is very rare. The lifecycle of any piece of data in cache is in microseconds or less. Cache is just a streaming-buffer for RAM, it's not like the "most important stuff" stays there. Cache is usually completely overwritten thousands of times per second.
If you mean between L3 caches to mean between each CCX or die - yes, that's true. Everything is always referenced as a memory address, the LLC acts as the insulator to main memory. However, cross communication does occur for certain volatile memory. This seems to happen via the command bus, but it also happens via the data fabric. This is probably magic that happens through the IMC without going to system memory, which would explain the latency results with core to core communication (simple test - fixed affinity, each core accessing the same memory addresses, just reading and updating a simple struct - time, accessing core, and a mutex... each core that gains the mutex records the time difference between the last access, which core made that access, updates the struct, and moves on). This showed that handling the mutex could, PEAK, take only 10ns between the CCXes (this could even be a timing mechanism inaccuracy, since this all reanalysis), but usually took way more... strong clusters at 20ns, 40~50ns, and a good half at 100ns or more (which means out to main memory).
Multi-threaded apps share data across cores, it's as simple as that, and mutexes and volatile memory are all something the CPU can figure out with ease, so optimizing for those, in very least, has been done.
Zen is however penalized when having to access a different memory controller through the Infinity Fabric, which of course is common in multithreaded workloads.
Yes, it will be extremely interesting to see how the newly unified IMC that's spread far across the IO die will work to solve some of these issues.



")