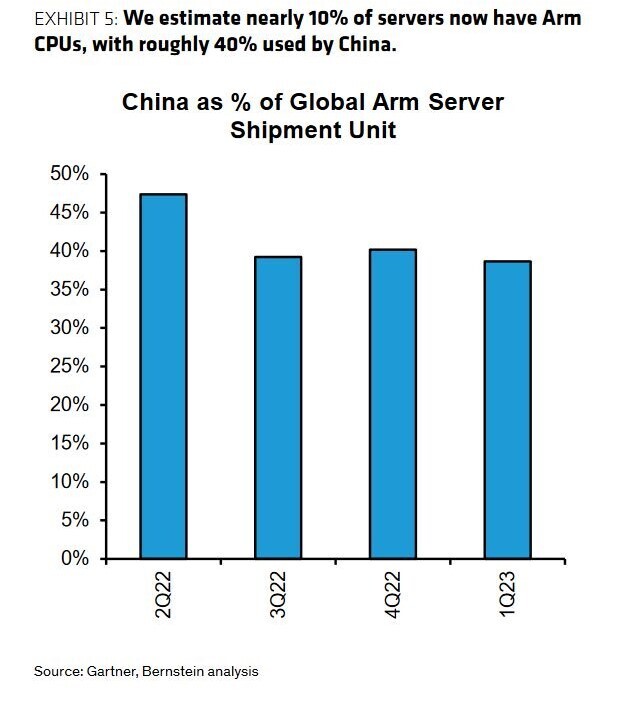
AIO Workstation Combines 128-Core Arm Processor and Four NVIDIA GPUs Totaling 28,416 CUDA Cores
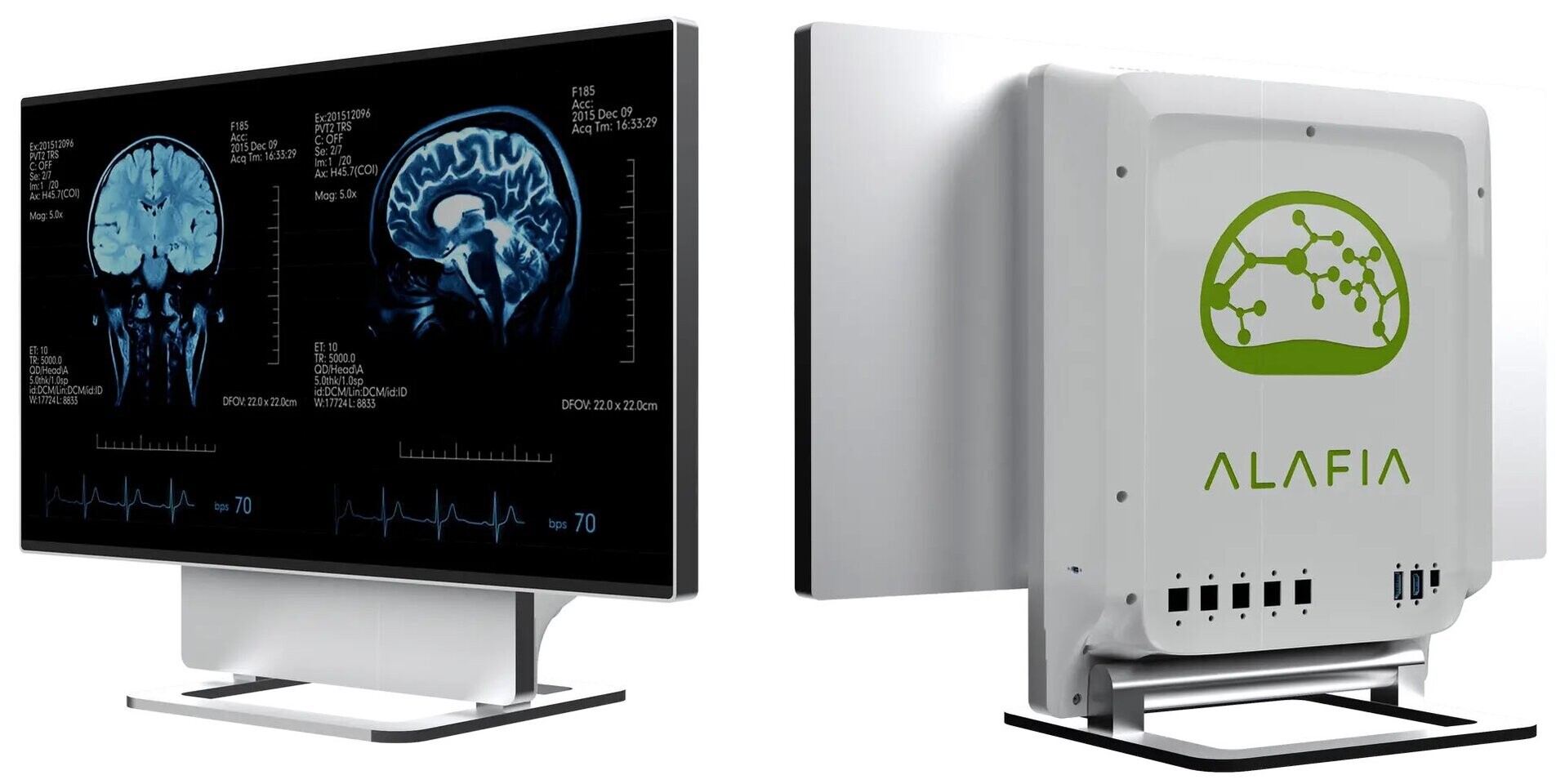
All-in-one computers are often traditionally seen as lower-powered alternatives to traditional desktop workstations. However, a new offering from Alafia AI, a startup focused on medical imaging appliances, aims to shatter that perception. The company's upcoming Alafia Aivas SuperWorkstation packs serious hardware muscle, demonstrating that all-in-one systems can match the performance of their more modular counterparts. At the heart of the Aivas SuperWorkstation lies a 128-core Ampere Altra processor, running at 3.0 GHz clock speed. This CPU is complemented by not one but three NVIDIA L4 GPUs for compute, and a single NVIDIA RTX 4000 Ada GPU for video output, delivering a combined 28,416 CUDA cores for accelerated parallel computing tasks. The system doesn't skimp on other components, either. It features a 4K touch display with up to 360 nits of brightness, an extensive 2 TB of DDR4 RAM, and storage options up to an 8 TB solid-state drive. This combination of cutting-edge CPU, GPU, memory, and storage is squarely aimed at the demands of medical imaging and AI development workloads.
The all-in-one form factor packs this incredible hardware into a sleek, purposefully designed clinical research appliance. While initially targeting software developers, Alafia AI hopes that institutions that can optimize their applications for the Arm architecture can eventually deploy the Aivas SuperWorkstation for production medical imaging workloads. The company is aiming for application integration in Q3 2024 and full ecosystem device integration by Q4 2024. With this powerful new offering, Alafia AI is challenging long-held assumptions about the performance limitations of all-in-one systems. The Aivas SuperWorkstation demonstrates that the right hardware choices can transform these compact form factors into true powerhouse workstations. Especially with a combined total output of three NVIDIA L4 compute units, alongside RTX 4000 Ada graphics card, the AIO is more powerful than some of the high-end desktop workstations.


The all-in-one form factor packs this incredible hardware into a sleek, purposefully designed clinical research appliance. While initially targeting software developers, Alafia AI hopes that institutions that can optimize their applications for the Arm architecture can eventually deploy the Aivas SuperWorkstation for production medical imaging workloads. The company is aiming for application integration in Q3 2024 and full ecosystem device integration by Q4 2024. With this powerful new offering, Alafia AI is challenging long-held assumptions about the performance limitations of all-in-one systems. The Aivas SuperWorkstation demonstrates that the right hardware choices can transform these compact form factors into true powerhouse workstations. Especially with a combined total output of three NVIDIA L4 compute units, alongside RTX 4000 Ada graphics card, the AIO is more powerful than some of the high-end desktop workstations.