MSI Announces the SPATIUM M580 FROZR: A Groundbreaking PCIe Gen 5 SSD Redefining Speed and Reliability
MSI, a global leader in gaming PC hardware, is thrilled to announce the release of its highly anticipated SSD powerhouse, the SPATIUM M580 FROZR, ushering in a new era of storage performance. With cutting-edge technology and innovative thermal solutions, this SSD is set to redefine the standards of speed and reliability in storage solutions.
SPATIUM M580 FROZR, Reaching New Heights with Crowned Speeds
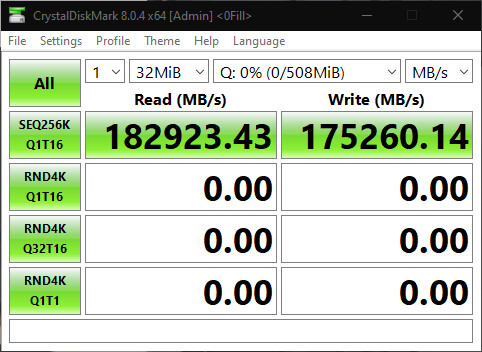
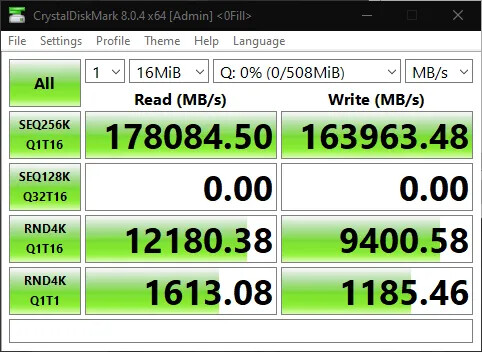
The SPATIUM M580 FROZR sets a new benchmark in storage performance with its revolutionary features. Powered by the state-of-the-art PHISON E26 PCIe Gen 5 controller and equipped with advanced 3D NAND flash modules boasting 232 layers, this SSD achieves mind-blowing read speeds of up to 14.6 GB/s and write speeds of up to 12.7 GB/s, up to 2 times faster transfer rates compared to current PCIe 4.0 SSDs. This represents a significant leap in speeds, boosted by a DRAM cache buffer and a SLC Cache, providing users with lightning-fast data access and gaining valuable milliseconds in latency for gaming, content creation, and professional applications. Additionally, the M580 FROZR is fortified with LPDC ECC and E2E Data Protection, ensuring data integrity and reliability. With a high TBW (Terabytes Written) value and backed by a comprehensive 5-year warranty, users can trust in the durability and longevity of the SPATIUM M580 FROZR in 1 TB, 2 TB and 4 TB variants after an easy installation.


SPATIUM M580 FROZR, Reaching New Heights with Crowned Speeds
The SPATIUM M580 FROZR sets a new benchmark in storage performance with its revolutionary features. Powered by the state-of-the-art PHISON E26 PCIe Gen 5 controller and equipped with advanced 3D NAND flash modules boasting 232 layers, this SSD achieves mind-blowing read speeds of up to 14.6 GB/s and write speeds of up to 12.7 GB/s, up to 2 times faster transfer rates compared to current PCIe 4.0 SSDs. This represents a significant leap in speeds, boosted by a DRAM cache buffer and a SLC Cache, providing users with lightning-fast data access and gaining valuable milliseconds in latency for gaming, content creation, and professional applications. Additionally, the M580 FROZR is fortified with LPDC ECC and E2E Data Protection, ensuring data integrity and reliability. With a high TBW (Terabytes Written) value and backed by a comprehensive 5-year warranty, users can trust in the durability and longevity of the SPATIUM M580 FROZR in 1 TB, 2 TB and 4 TB variants after an easy installation.