- Joined
- Oct 9, 2007
- Messages
- 47,890 (7.38/day)
- Location
- Dublin, Ireland
| System Name | RBMK-1000 |
|---|---|
| Processor | AMD Ryzen 7 5700G |
| Motherboard | Gigabyte B550 AORUS Elite V2 |
| Cooling | DeepCool Gammax L240 V2 |
| Memory | 2x 16GB DDR4-3200 |
| Video Card(s) | Galax RTX 4070 Ti EX |
| Storage | Samsung 990 1TB |
| Display(s) | BenQ 1440p 60 Hz 27-inch |
| Case | Corsair Carbide 100R |
| Audio Device(s) | ASUS SupremeFX S1220A |
| Power Supply | Cooler Master MWE Gold 650W |
| Mouse | ASUS ROG Strix Impact |
| Keyboard | Gamdias Hermes E2 |
| Software | Windows 11 Pro |
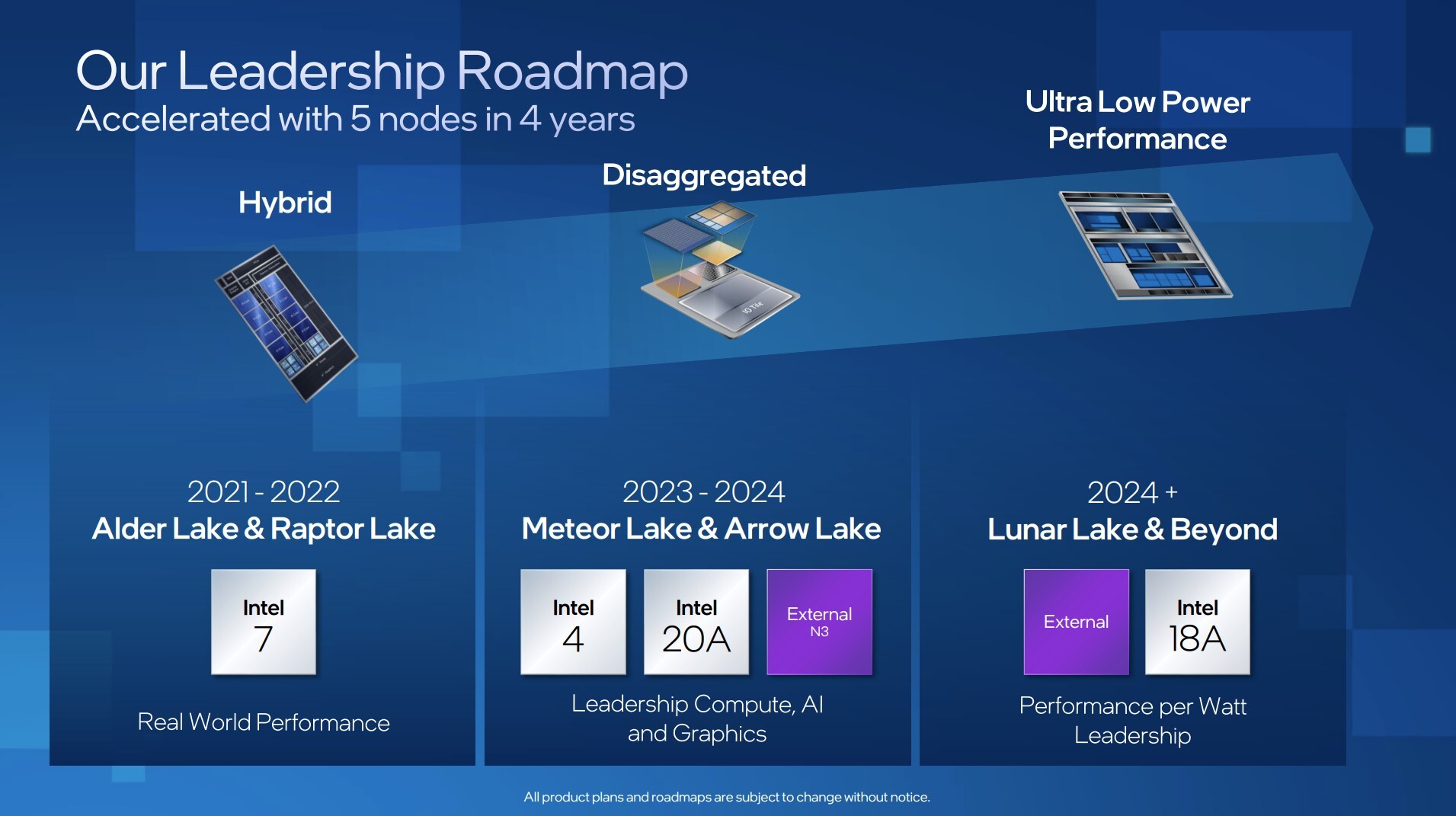
Intel's upcoming "Meteor Lake" and "Arrow Lake" client mobile processors introduce an interesting twist to the chiplet concept. Earlier represented in vague-looking IP blocks, new artistic impressions of the chip put out by Intel shed light on a 3-die approach not unlike the Ryzen "Vermeer" MCM that has up to two CPU core dies (CCDs) talking to a cIOD (client IO die), which handles all the SoC connectivity; Intel's design has one major difference, and that's integrated graphics. Apparently, Intel's MCM uses a GPU die sitting next to the CPU core die, and the I/O (SoC) die. Intel likes to call its chiplets "tiles," and so we'll go with that.
The Graphics tile, CPU tile, and the SoC or I/O tile, are built on three different silicon fabrication process nodes based on the degree of need for the newer process node. The nodes used are Intel 4 (optically 7 nm EUV, but with characteristics of a 5 nm-class node); Intel 20A (characteristics of 2 nm), and external TSMC N3 (3 nm) node. At this point we don't know which tile gets what. From the looks of it, the CPU tile has a hybrid CPU core architecture made up of "Redwood Cove" P-cores, and "Crestmont" E-core clusters.


The Graphics tile packs an iGPU based on the Xe LP graphics architecture, but leverages an advanced node to significantly increase the execution unit (EU) count to 352, and possible increase graphics clocks. The SoC and I/O tile packs the platform security processor, integrated northbridge, memory controllers, PCI-Express root-complex, and the various platform I/O.
Intel is preparing "Meteor Lake" for a 2023 launch, with development completing within 2022, although mass-production might still commence next year.
View at TechPowerUp Main Site
The Graphics tile, CPU tile, and the SoC or I/O tile, are built on three different silicon fabrication process nodes based on the degree of need for the newer process node. The nodes used are Intel 4 (optically 7 nm EUV, but with characteristics of a 5 nm-class node); Intel 20A (characteristics of 2 nm), and external TSMC N3 (3 nm) node. At this point we don't know which tile gets what. From the looks of it, the CPU tile has a hybrid CPU core architecture made up of "Redwood Cove" P-cores, and "Crestmont" E-core clusters.

The Graphics tile packs an iGPU based on the Xe LP graphics architecture, but leverages an advanced node to significantly increase the execution unit (EU) count to 352, and possible increase graphics clocks. The SoC and I/O tile packs the platform security processor, integrated northbridge, memory controllers, PCI-Express root-complex, and the various platform I/O.
Intel is preparing "Meteor Lake" for a 2023 launch, with development completing within 2022, although mass-production might still commence next year.
View at TechPowerUp Main Site

 )
)





