Up front: I have an Inno3D GeForce GTX 1080Ti iChill X3 with an ASUS P9X79 Pro motherboard, running Windows 10. I know Inno3D doesn't have the best reputation, but I'm keeping my fingers crossed I don't need to replace the GPU just yet ")
I've noticed this issue mainly while running neural network training on the GPU, but I think this is affecting games as well - recently, the card has started running slower.
More precisely, what happens is that I'll start up the computer, begin training, and for a few hours it will run at top capacity without any issues. But all of a sudden, it'll drop in productivity and subsequent work done takes almost exactly twice as long as before. Other times, CUDA will error out or the entire computer will crash and reboot. The thing is that this has only started happening recently - I ran the same training algorithm (StyleGAN) with the same image sizes, exact same load on GPU and VRAM, and I never had any of these problems. Something has started messing it up.
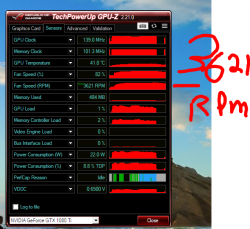
Trying to figure out what could be causing this - I ended up running a GPU-Z capture over the course of a day, which I've attached.
The switch over from one mode of operation to the other is really obvious, looking at the capture, but I'm having trouble figuring out what could cause this. As far as I can tell, there's nothing in the software that would cause it to switch operation, and I can't see anything going on in terms of background processes. If I kill the process and then start again, it continues running slow. Only way to reset it is to restart the computer, at which point the cycle continues.
To summarise the sensor log:
* GPU Clock spikes up and down around 1600, until around the 2h40 mark, at which point it caps out at 2000.
* GPU Temperature starts out close to 90'C, but after the breaking point at 2h40, drops down to about 64'C.
* Accordingly Fan Speed % is at 100 at first, but then drops to 70.
* GPU Load is between 90% and 100%, but after 2h40 it rises up to being 95% to 100%.
* Memory Controller Load goes from averaging 55% to 25%.
* Power Consumption drops from average 240W to 160W.
* PerfCap Reason oscillates between 2 and 16 in the first part, but is consistently 4 in the second part. I.e. it goes from power and thermal caps to voltage reliability cap super consistently.
* VDDC switches up from wiggling around ~0.81V to flat 1.04V
* CPU Temp drops from ~56'C to ~52'C
* Memory usage doesn't change.
I can't make heads or tails of this, personally. My initial guess was that the problem was maybe overheating, or some other process kicking in and using up GPU (maybe I've acquired BitCoin mining malware). But these figures make no sense to me. GPU Clock Speed goes up, but GPU Temperature goes down. VDDC goes up, Power Consumption goes down. GPU Load rises, but the GPU seems to be doing less work.
Maybe another process kicks in that's demanding GPU time, but with less occupancy? Even that, I'm not sure that it makes sense.
Please let me know if you have any idea what this might be a symptom of!")
I've noticed this issue mainly while running neural network training on the GPU, but I think this is affecting games as well - recently, the card has started running slower.
More precisely, what happens is that I'll start up the computer, begin training, and for a few hours it will run at top capacity without any issues. But all of a sudden, it'll drop in productivity and subsequent work done takes almost exactly twice as long as before. Other times, CUDA will error out or the entire computer will crash and reboot. The thing is that this has only started happening recently - I ran the same training algorithm (StyleGAN) with the same image sizes, exact same load on GPU and VRAM, and I never had any of these problems. Something has started messing it up.
Trying to figure out what could be causing this - I ended up running a GPU-Z capture over the course of a day, which I've attached.
The switch over from one mode of operation to the other is really obvious, looking at the capture, but I'm having trouble figuring out what could cause this. As far as I can tell, there's nothing in the software that would cause it to switch operation, and I can't see anything going on in terms of background processes. If I kill the process and then start again, it continues running slow. Only way to reset it is to restart the computer, at which point the cycle continues.
To summarise the sensor log:
* GPU Clock spikes up and down around 1600, until around the 2h40 mark, at which point it caps out at 2000.
* GPU Temperature starts out close to 90'C, but after the breaking point at 2h40, drops down to about 64'C.
* Accordingly Fan Speed % is at 100 at first, but then drops to 70.
* GPU Load is between 90% and 100%, but after 2h40 it rises up to being 95% to 100%.
* Memory Controller Load goes from averaging 55% to 25%.
* Power Consumption drops from average 240W to 160W.
* PerfCap Reason oscillates between 2 and 16 in the first part, but is consistently 4 in the second part. I.e. it goes from power and thermal caps to voltage reliability cap super consistently.
* VDDC switches up from wiggling around ~0.81V to flat 1.04V
* CPU Temp drops from ~56'C to ~52'C
* Memory usage doesn't change.
I can't make heads or tails of this, personally. My initial guess was that the problem was maybe overheating, or some other process kicking in and using up GPU (maybe I've acquired BitCoin mining malware). But these figures make no sense to me. GPU Clock Speed goes up, but GPU Temperature goes down. VDDC goes up, Power Consumption goes down. GPU Load rises, but the GPU seems to be doing less work.
Maybe another process kicks in that's demanding GPU time, but with less occupancy? Even that, I'm not sure that it makes sense.
Please let me know if you have any idea what this might be a symptom of!

 poor ventilation, what is your room temp .
poor ventilation, what is your room temp .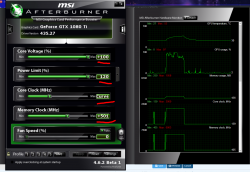



 Will have to have a fiddle with it.
Will have to have a fiddle with it.