- Joined
- Aug 19, 2017
- Messages
- 2,241 (0.91/day)
IBM Research has published information about the company's latest development of processors for accelerating Artificial Intelligence (AI). The latest IBM processor, called the Artificial Intelligence Unit (AIU), embraces the problem of creating an enterprise solution for AI deployment that fits in a PCIe slot. The IBM AIU is a half-height PCIe card with a processor powered by 23 Billion transistors manufactured on a 5 nm node (assuming TSMC's). While IBM has not provided many details initially, we know that the AIU uses an AI processor found in the Telum chip, a core of the IBM Z16 mainframe. The AIU uses Telum's AI engine and scales it up to 32 cores and achieve high efficiency.
The company has highlighted two main paths for enterprise AI adoption. The first one is to embrace lower precision and use approximate computing to drop from 32-bit formats to some odd-bit structures that hold a quarter as much precision and still deliver similar result. The other one is, as IBM touts, that "AI chip should be laid out to streamline AI workflows. Because most AI calculations involve matrix and vector multiplication, our chip architecture features a simpler layout than a multi-purpose CPU. The IBM AIU has also been designed to send data directly from one compute engine to the next, creating enormous energy savings."

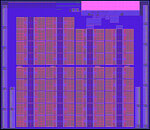
In the sea of AI accelerators, IBM hopes to differentiate its offerings by having an enterprise chip to solve more complex problems than current AI chips target. "Deploying AI to classify cats and dogs in photos is a fun academic exercise. But it won't solve the pressing problems we face today. For AI to tackle the complexities of the real world—things like predicting the next Hurricane Ian, or whether we're heading into a recession—we need enterprise-quality, industrial-scale hardware. Our AIU takes us one step closer. We hope to soon share news about its release," says the official IBM release.
View at TechPowerUp Main Site | Source
The company has highlighted two main paths for enterprise AI adoption. The first one is to embrace lower precision and use approximate computing to drop from 32-bit formats to some odd-bit structures that hold a quarter as much precision and still deliver similar result. The other one is, as IBM touts, that "AI chip should be laid out to streamline AI workflows. Because most AI calculations involve matrix and vector multiplication, our chip architecture features a simpler layout than a multi-purpose CPU. The IBM AIU has also been designed to send data directly from one compute engine to the next, creating enormous energy savings."


In the sea of AI accelerators, IBM hopes to differentiate its offerings by having an enterprise chip to solve more complex problems than current AI chips target. "Deploying AI to classify cats and dogs in photos is a fun academic exercise. But it won't solve the pressing problems we face today. For AI to tackle the complexities of the real world—things like predicting the next Hurricane Ian, or whether we're heading into a recession—we need enterprise-quality, industrial-scale hardware. Our AIU takes us one step closer. We hope to soon share news about its release," says the official IBM release.
View at TechPowerUp Main Site | Source




")
