- Joined
- Aug 19, 2017
- Messages
- 2,978 (1.06/day)
Meta has prepared a leap-forward update for its Llama model series with the v4 release, entering an era of native multimodality within the company's AI models. At the forefront is Llama 4 Scout, a model boasting 17 billion active parameters distributed across 16 experts in a mixture-of-experts (MoE) configuration. With FP4 precision, this model is engineered to run entirely on a single NVIDIA H100 GPU. Scout now supports an industry-leading input context window of up to 10 million tokens, a substantial leap from previous limits like Google's old Gemini 1.5 Pro, which came with 2 million token input content. Llama 4 Scout is built using a hybrid dense and MoE architecture, which selectively activates only a subset of each token's total parameters, optimizing training and inference efficiency. This architecture not only accelerates computation but also reduces associated costs.
Meanwhile, Llama 4 Maverick, another model in the series, also features 17 billion active parameters but incorporates 128 experts, scaling to 400 billion total parameters. Maverick has demonstrated superior performance in coding, image understanding, multilingual processing, and logical reasoning, even outperforming several leading models in its class. Both models embrace native multimodality by integrating text and image data early in the processing pipeline. Utilizing a custom MetaCLIP-based vision encoder, these models can simultaneously process multiple images and text, combining tokens into a single backend processor. This ensures robust visual comprehension and precise object anchoring, powering applications such as detailed image description, visual question-answering, and analysis of temporal image sequences.


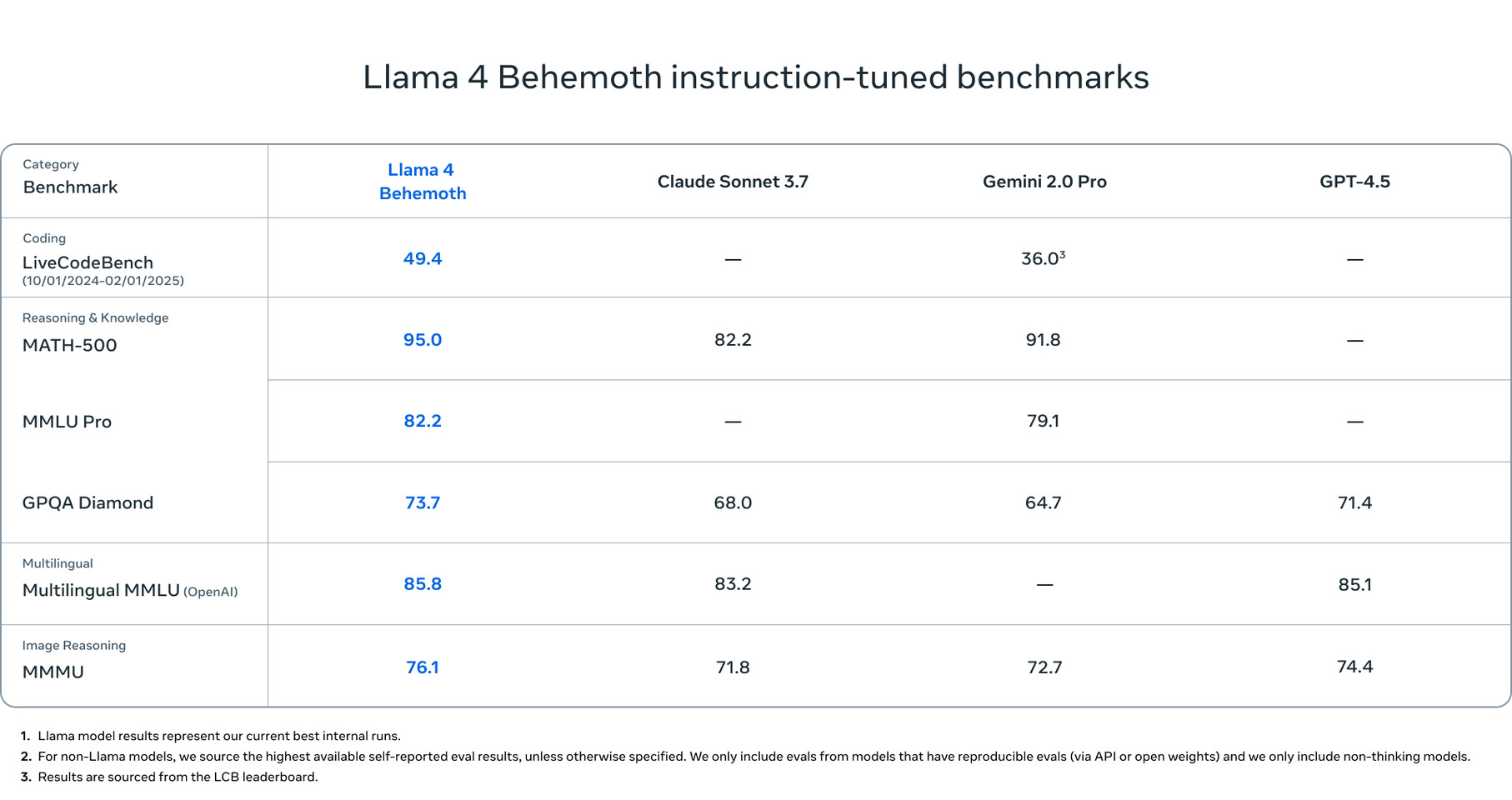
Central to the Llama 4 ecosystem is the teacher model, Llama 4 Behemoth, which scales to 288 billion active parameters and nearly two trillion total parameters. It serves as a critical co-distillation source, enhancing both Scout and Maverick through advanced reinforcement learning techniques. While the Llama 4 Behemoth is still in the training process, it will be placed among the top performers in its class. Interestingly, Meta's Llama 4 models are trained using FP8 precision, which is significant given its Llama 3 models uses FP16 and FP8. By using lower precisions more effectively, Meta achieves higher GPU FLOPS utilization while maintaining precision. Below are some benchmarks comparing Meta's models with other competing labs like Google, Anthropic, and OpenAI.



View at TechPowerUp Main Site | Source
Meanwhile, Llama 4 Maverick, another model in the series, also features 17 billion active parameters but incorporates 128 experts, scaling to 400 billion total parameters. Maverick has demonstrated superior performance in coding, image understanding, multilingual processing, and logical reasoning, even outperforming several leading models in its class. Both models embrace native multimodality by integrating text and image data early in the processing pipeline. Utilizing a custom MetaCLIP-based vision encoder, these models can simultaneously process multiple images and text, combining tokens into a single backend processor. This ensures robust visual comprehension and precise object anchoring, powering applications such as detailed image description, visual question-answering, and analysis of temporal image sequences.


Central to the Llama 4 ecosystem is the teacher model, Llama 4 Behemoth, which scales to 288 billion active parameters and nearly two trillion total parameters. It serves as a critical co-distillation source, enhancing both Scout and Maverick through advanced reinforcement learning techniques. While the Llama 4 Behemoth is still in the training process, it will be placed among the top performers in its class. Interestingly, Meta's Llama 4 models are trained using FP8 precision, which is significant given its Llama 3 models uses FP16 and FP8. By using lower precisions more effectively, Meta achieves higher GPU FLOPS utilization while maintaining precision. Below are some benchmarks comparing Meta's models with other competing labs like Google, Anthropic, and OpenAI.


View at TechPowerUp Main Site | Source

