- Joined
- Oct 9, 2007
- Messages
- 47,855 (7.38/day)
- Location
- Dublin, Ireland
| System Name | RBMK-1000 |
|---|---|
| Processor | AMD Ryzen 7 5700G |
| Motherboard | Gigabyte B550 AORUS Elite V2 |
| Cooling | DeepCool Gammax L240 V2 |
| Memory | 2x 16GB DDR4-3200 |
| Video Card(s) | Galax RTX 4070 Ti EX |
| Storage | Samsung 990 1TB |
| Display(s) | BenQ 1440p 60 Hz 27-inch |
| Case | Corsair Carbide 100R |
| Audio Device(s) | ASUS SupremeFX S1220A |
| Power Supply | Cooler Master MWE Gold 650W |
| Mouse | ASUS ROG Strix Impact |
| Keyboard | Gamdias Hermes E2 |
| Software | Windows 11 Pro |
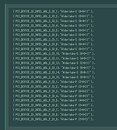
Intel's 12th Gen Core EVO "Alder Lake" processors in the LGA1700 package could introduce the company's hybrid core technology to the desktop platform. Coreboot code leaked to the web by Coelacanth's Dream sheds fascinating insights to the way Intel is segmenting these chips. The 10 nm chip will see Intel combine high-performance "Golden Cove" CPU cores with energy-efficient "Gracemont" CPU cores, and up to three tiers of the company's Gen12 Xe integrated graphics. The "Alder Lake" desktop processor has up to eight big cores, up to eight small ones, and up to three tiers of the iGPU (GT0 being disabled iGPU, GT1 being the lower tier, and GT2 being the higher tier).
Segmentation between the various brand extensions appears to be primarily determined by the number of big cores. The topmost SKU has all 8 big and 8 small cores enabled, along with GT1 (lower) tier of the iGPU (possibly to free up power headroom for those many cores). The slightly lower SKU has 8 big cores, 6 small cores, and GT1 graphics. Next up, is 8 big cores, 4 small cores, and GT1 graphics. Then 8+2+GT1, and lastly, 8+0+GT1. The next brand extension is based around 6 big cores, being led by 6+8+GT2, and progressively lower number of small cores and their various iGPU tiers. The lower brand extension is based around 4 big cores with similar segmentation of small cores, and the entry-level parts have 2 big cores, and up to 8 small cores.
View at TechPowerUp Main Site
Segmentation between the various brand extensions appears to be primarily determined by the number of big cores. The topmost SKU has all 8 big and 8 small cores enabled, along with GT1 (lower) tier of the iGPU (possibly to free up power headroom for those many cores). The slightly lower SKU has 8 big cores, 6 small cores, and GT1 graphics. Next up, is 8 big cores, 4 small cores, and GT1 graphics. Then 8+2+GT1, and lastly, 8+0+GT1. The next brand extension is based around 6 big cores, being led by 6+8+GT2, and progressively lower number of small cores and their various iGPU tiers. The lower brand extension is based around 4 big cores with similar segmentation of small cores, and the entry-level parts have 2 big cores, and up to 8 small cores.

View at TechPowerUp Main Site




