- Joined
- Aug 19, 2017
- Messages
- 3,066 (1.08/day)
With growing revenues coming from strong sales of Ryzen and Radeon products, AMD is more focused on innovation than ever. It is important for any company to re-invest its capital into R&D, to stay ahead. And that is exactly what AMD is doing by focusing on future technologies, while constantly improving existing solutions.
On June 13th, AMD published a new method for instruction scheduling of shader programs for a GPU. The method operates on fixed number of registers. It works in five stages:
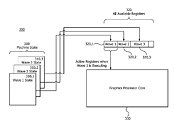
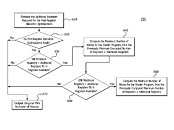
It is important to note that the "liveness" of registers is most probably a reference to register utilization, while the term "wave" refers to the machine states, like for example EOP (End Of Pipe) and DRAW which draws the shader. There are of course many more states but these are just few examples from AMD's "GPU Open" documentation. The new method is supposed to bring additional performance improvements and reduce latency by making data (machine states in this case) like a wave that is stored in a register.
You can find out more about it here.
View at TechPowerUp Main Site
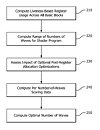
On June 13th, AMD published a new method for instruction scheduling of shader programs for a GPU. The method operates on fixed number of registers. It works in five stages:
- Compute liveness-based register usage across all basic blocks
- Computer range of numbers of waves for shader program
- Assess the impact of available post-register allocation optimizations
- Compute the scoring data based on number of waves of the plurality of registers
- Compute optimal number of waves


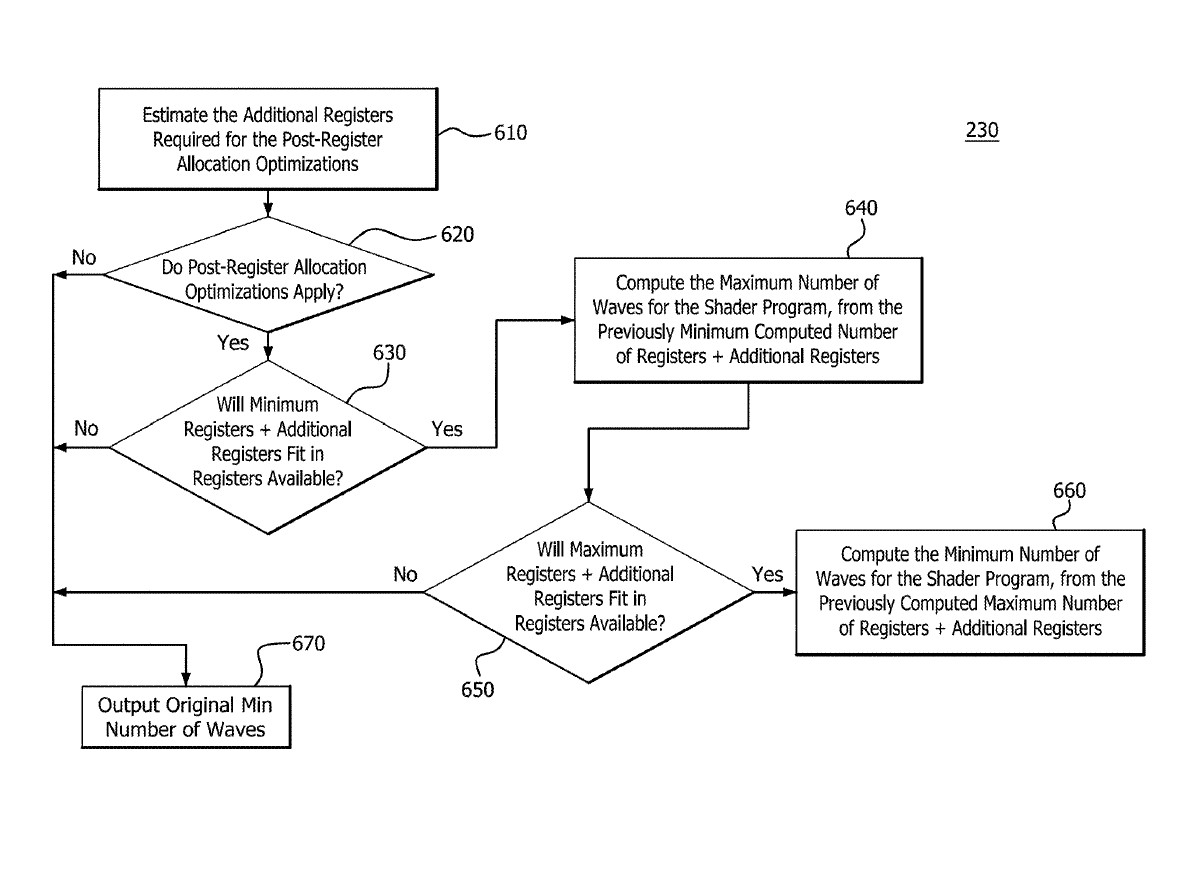
It is important to note that the "liveness" of registers is most probably a reference to register utilization, while the term "wave" refers to the machine states, like for example EOP (End Of Pipe) and DRAW which draws the shader. There are of course many more states but these are just few examples from AMD's "GPU Open" documentation. The new method is supposed to bring additional performance improvements and reduce latency by making data (machine states in this case) like a wave that is stored in a register.
You can find out more about it here.
View at TechPowerUp Main Site



