- Joined
- Oct 9, 2007
- Messages
- 47,770 (7.42/day)
- Location
- Dublin, Ireland
| System Name | RBMK-1000 |
|---|---|
| Processor | AMD Ryzen 7 5700G |
| Motherboard | Gigabyte B550 AORUS Elite V2 |
| Cooling | DeepCool Gammax L240 V2 |
| Memory | 2x 16GB DDR4-3200 |
| Video Card(s) | Galax RTX 4070 Ti EX |
| Storage | Samsung 990 1TB |
| Display(s) | BenQ 1440p 60 Hz 27-inch |
| Case | Corsair Carbide 100R |
| Audio Device(s) | ASUS SupremeFX S1220A |
| Power Supply | Cooler Master MWE Gold 650W |
| Mouse | ASUS ROG Strix Impact |
| Keyboard | Gamdias Hermes E2 |
| Software | Windows 11 Pro |
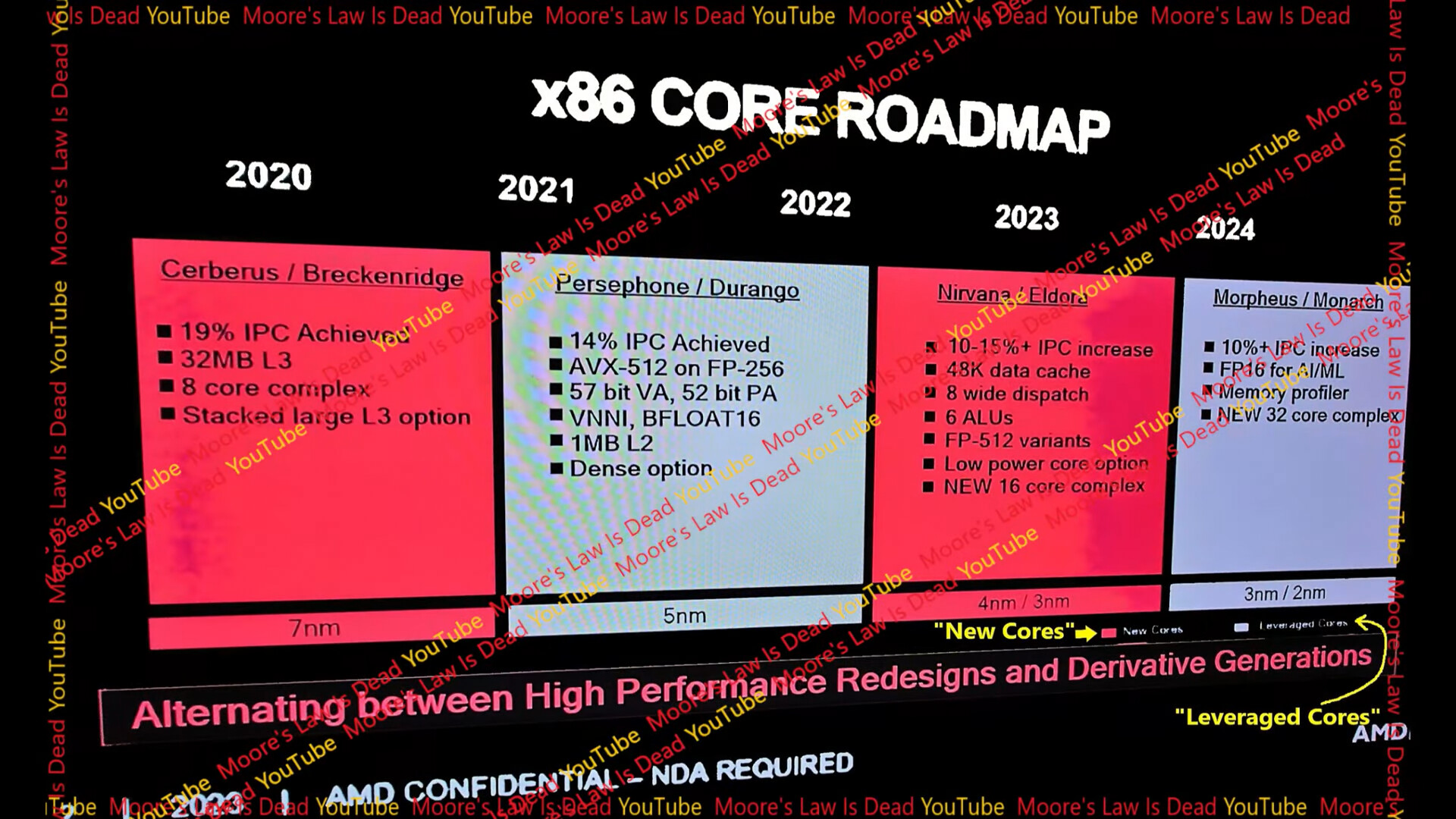
A couple of slides from AMD's internal presentation were leaked to the web by Moore's Law is Dead, referencing what's allegedly the next-generation "Zen 5" microarchitecture. Internally, the performance variant of the "Zen 5" core is referred to as "Nirvana," and the CCD chiplet (CPU core die) based on "Nirvana" cores, is codenamed "Eldora." These CCDs will make up either the company's Ryzen "Granite Ridge" desktop processors, or EPYC "Turin" server processors. The cores themselves could also be part of the company's next-generation mobile processors, as part of heterogenous CCXs (CPU core complex), next to "Zen 5c" low-power cores.
In broad strokes, AMD describes "Zen 5" as introducing a 10% to 15% IPC increase over the current "Zen 4." The core will feature a larger 48 KB L1D cache, compared to the current 32 KB. As for the core itself, it features an 8-wide dispatch from the micro-op queue, compared to the 6-wide dispatch of "Zen 4." The integer execution stage gets 6 ALUs, compared to the current 4. The floating point unit gets FP-512 capabilities. Perhaps the biggest announcement is that AMD has increased the maximum cores per CCX from 8 to 16. At this point we don't know if it means that "Eldora" CCD will have 16 cores, or whether it means that the cloud-specific CCD with 16 "Zen 5c" cores will have 16 cores within a single CCX, rather than spread across two CCXs with smaller L3 caches. AMD is leveraging the TSMC 4 nm EUV node for "Eldora," the mobile processor based on "Zen 5" could be based on the more advanced TSMC 3 nm EUV node.


The opening slide also provides a fascinating way AMD describes its CPU core architectures. According to this, "Zen 3" and "Zen 5" are new cores, while "Zen 4" and the future "Zen 6" cores are leveraged cores. If you recall, "Zen 3" had provided a massive 19% IPC uplift over "Zen 2," which helped AMD dominate the CPU market. Although with a more conservative 15% IPC gain estimate over "Zen 4," the "Zen 5" core is expected to have as big of an impact on AMD's competitiveness.
Speaking of the "Zen 6" microarchitecture and the "Morpheus" core, AMD is anticipating a 10% IPC increase over "Zen 5," new FP16 capabilities for the core, and a 32-core CCX (maximum core-count). This would see a second round of significant increases in CPU core counts.
Diving deep into the "Zen 5" core, and we see AMD introduce an even more advanced branch prediction unit. If you recall, branch predictor improvements had the largest contribution toward the generational IPC gain of "Zen 4." The new branch predictor comes with zero bubble conditional branches capabilities, accuracy improvements, and a larger BTB (branch target buffer). As we mentioned, the core has a larger 48 KB L1D cache, and an unspecified larger D-TLB. There are throughput improvement across the front-end and load/store stages, with dual basic block fetch units, 8-wide op dispatch/rename; Op Fusion, a 50% increase in ALCs, a deeper execution window, a more capable prefetcher, and updates to the CPU core ISA and security. The dedicated L2 cache per core remains 1 MB in size.
View at TechPowerUp Main Site | Source
In broad strokes, AMD describes "Zen 5" as introducing a 10% to 15% IPC increase over the current "Zen 4." The core will feature a larger 48 KB L1D cache, compared to the current 32 KB. As for the core itself, it features an 8-wide dispatch from the micro-op queue, compared to the 6-wide dispatch of "Zen 4." The integer execution stage gets 6 ALUs, compared to the current 4. The floating point unit gets FP-512 capabilities. Perhaps the biggest announcement is that AMD has increased the maximum cores per CCX from 8 to 16. At this point we don't know if it means that "Eldora" CCD will have 16 cores, or whether it means that the cloud-specific CCD with 16 "Zen 5c" cores will have 16 cores within a single CCX, rather than spread across two CCXs with smaller L3 caches. AMD is leveraging the TSMC 4 nm EUV node for "Eldora," the mobile processor based on "Zen 5" could be based on the more advanced TSMC 3 nm EUV node.

The opening slide also provides a fascinating way AMD describes its CPU core architectures. According to this, "Zen 3" and "Zen 5" are new cores, while "Zen 4" and the future "Zen 6" cores are leveraged cores. If you recall, "Zen 3" had provided a massive 19% IPC uplift over "Zen 2," which helped AMD dominate the CPU market. Although with a more conservative 15% IPC gain estimate over "Zen 4," the "Zen 5" core is expected to have as big of an impact on AMD's competitiveness.
Speaking of the "Zen 6" microarchitecture and the "Morpheus" core, AMD is anticipating a 10% IPC increase over "Zen 5," new FP16 capabilities for the core, and a 32-core CCX (maximum core-count). This would see a second round of significant increases in CPU core counts.
Diving deep into the "Zen 5" core, and we see AMD introduce an even more advanced branch prediction unit. If you recall, branch predictor improvements had the largest contribution toward the generational IPC gain of "Zen 4." The new branch predictor comes with zero bubble conditional branches capabilities, accuracy improvements, and a larger BTB (branch target buffer). As we mentioned, the core has a larger 48 KB L1D cache, and an unspecified larger D-TLB. There are throughput improvement across the front-end and load/store stages, with dual basic block fetch units, 8-wide op dispatch/rename; Op Fusion, a 50% increase in ALCs, a deeper execution window, a more capable prefetcher, and updates to the CPU core ISA and security. The dedicated L2 cache per core remains 1 MB in size.
View at TechPowerUp Main Site | Source





