TheLostSwede
News Editor
- Joined
- Nov 11, 2004
- Messages
- 18,475 (2.47/day)
- Location
- Sweden
| System Name | Overlord Mk MLI |
|---|---|
| Processor | AMD Ryzen 7 7800X3D |
| Motherboard | Gigabyte X670E Aorus Master |
| Cooling | Noctua NH-D15 SE with offsets |
| Memory | 32GB Team T-Create Expert DDR5 6000 MHz @ CL30-34-34-68 |
| Video Card(s) | Gainward GeForce RTX 4080 Phantom GS |
| Storage | 1TB Solidigm P44 Pro, 2 TB Corsair MP600 Pro, 2TB Kingston KC3000 |
| Display(s) | Acer XV272K LVbmiipruzx 4K@160Hz |
| Case | Fractal Design Torrent Compact |
| Audio Device(s) | Corsair Virtuoso SE |
| Power Supply | be quiet! Pure Power 12 M 850 W |
| Mouse | Logitech G502 Lightspeed |
| Keyboard | Corsair K70 Max |
| Software | Windows 10 Pro |
| Benchmark Scores | https://valid.x86.fr/yfsd9w |
Anandtech asked AMD during a meeting at CES about the production nodes used to make its chips at TSMC and the importance of leading edge nodes for AMD to stay competitive, especially in light of the cost of using said nodes. Lisa Su confirmed in her answer to Anandtech that AMD is using an optimised high-performance 5 nm node for its upcoming Zen 4 processor chiplets, which there interestingly appears to be both 2D and 3D versions of. This is the first time we've heard a mention of two different chiplet types using the same architecture and it could mean that we get to see Zen 4 based CPUs with and without 3D cache.
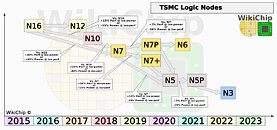
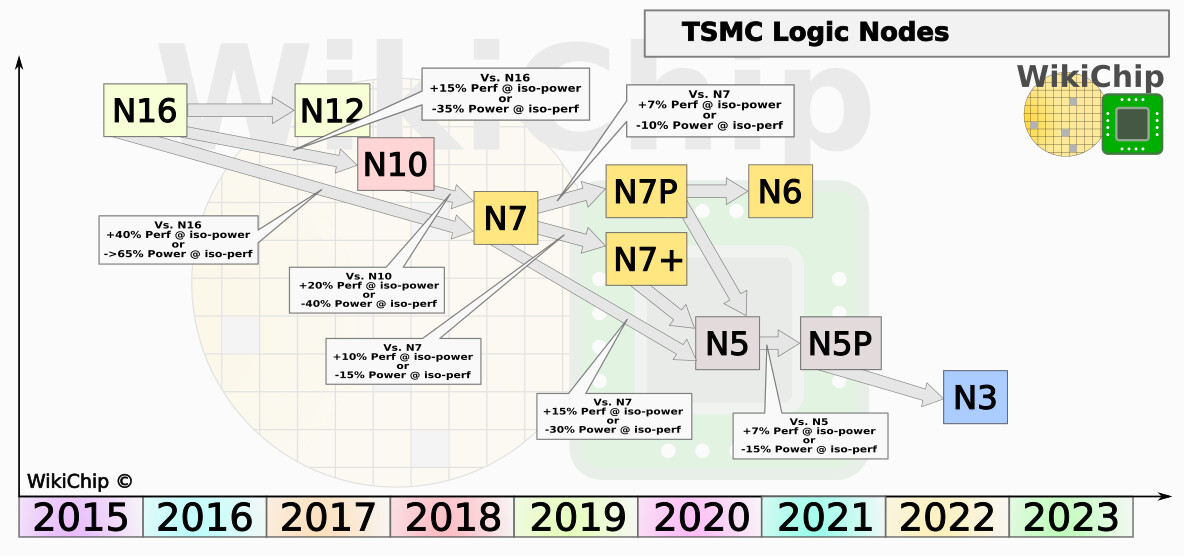
What strikes us as a bit odd about the Anandtech article, is that they mention the fact that several of TSMC's customers are already making 4 nm and soon 3 nm chips and are questioning why AMD wouldn't want to be on these same nodes. It seems like Anandtech has forgotten that not all process nodes are universally applicable and just because you can make one type of chip on a smaller node, doesn't mean it'll be suitable for a different type of chip. For the longest of times, mobile SoCs or other similar chips seem to always have been among the first things being made on new nodes, with more complex things like GPUs and more advanced CPUs coming later, to tweaked versions of the specific node. The fact that TSMC has no less than three 7 nm nodes, should be reason enough to realise that the leading edge node might not be the ideal node for all types of chips.

In related news, TSMC is said to have accepted advanced payments of US$5.44 billion from at least 10 of its clients, of which AMD, Apple, Nvidia and Qualcomm are all mentioned. The payments have been done to secure production capacity, although for exactly how long time into the future isn't clear. TSMC saw advanced payments of US$3.8 billion in the first three quarters of last year and it's likely that these kinds of deals will continue as long as there's more demand than supply.
View at TechPowerUp Main Site
What strikes us as a bit odd about the Anandtech article, is that they mention the fact that several of TSMC's customers are already making 4 nm and soon 3 nm chips and are questioning why AMD wouldn't want to be on these same nodes. It seems like Anandtech has forgotten that not all process nodes are universally applicable and just because you can make one type of chip on a smaller node, doesn't mean it'll be suitable for a different type of chip. For the longest of times, mobile SoCs or other similar chips seem to always have been among the first things being made on new nodes, with more complex things like GPUs and more advanced CPUs coming later, to tweaked versions of the specific node. The fact that TSMC has no less than three 7 nm nodes, should be reason enough to realise that the leading edge node might not be the ideal node for all types of chips.

In related news, TSMC is said to have accepted advanced payments of US$5.44 billion from at least 10 of its clients, of which AMD, Apple, Nvidia and Qualcomm are all mentioned. The payments have been done to secure production capacity, although for exactly how long time into the future isn't clear. TSMC saw advanced payments of US$3.8 billion in the first three quarters of last year and it's likely that these kinds of deals will continue as long as there's more demand than supply.
View at TechPowerUp Main Site




")
