- Joined
- Aug 19, 2017
- Messages
- 3,094 (1.09/day)
Apple has today patented a new approach to how it uses memory in the System-on-Chip (SoC) subsystem. With the announcement of the M1 processor, Apple has switched away from the traditional Intel-supplied chips and transitioned into a fully custom SoC design called Apple Silicon. The new designs have to integrate every component like the Arm CPU and a custom GPU. Both of these processors need good memory access, and Apple has figured out a solution to the problem of having both the CPU and the GPU accessing the same pool of memory. The so-called UMA (unified memory access) represents a bottleneck because both processors share the bandwidth and the total memory capacity, which would leave one processor starving in some scenarios.
Apple has patented a design that aims to solve this problem by combining high-bandwidth cache DRAM as well as high-capacity main DRAM. "With two types of DRAM forming the memory system, one of which may be optimized for bandwidth and the other of which may be optimized for capacity, the goals of bandwidth increase and capacity increase may both be realized, in some embodiments," says the patent, " to implement energy efficiency improvements, which may provide a highly energy-efficient memory solution that is also high performance and high bandwidth." The patent got filed way back in 2016 and it means that we could start seeing this technology in the future Apple Silicon designs, following the M1 chip.
Update 21:14 UTC: We have been reached out by Mr. Kerry Creeron, an attorney with the firm of Banner & Witcoff, who provided us with additional insights about the patent. Mr. Creeron has provided us with his personal commentary about it, and you can find Mr. Creeron's quote below.




View at TechPowerUp Main Site
Apple has patented a design that aims to solve this problem by combining high-bandwidth cache DRAM as well as high-capacity main DRAM. "With two types of DRAM forming the memory system, one of which may be optimized for bandwidth and the other of which may be optimized for capacity, the goals of bandwidth increase and capacity increase may both be realized, in some embodiments," says the patent, " to implement energy efficiency improvements, which may provide a highly energy-efficient memory solution that is also high performance and high bandwidth." The patent got filed way back in 2016 and it means that we could start seeing this technology in the future Apple Silicon designs, following the M1 chip.
Update 21:14 UTC: We have been reached out by Mr. Kerry Creeron, an attorney with the firm of Banner & Witcoff, who provided us with additional insights about the patent. Mr. Creeron has provided us with his personal commentary about it, and you can find Mr. Creeron's quote below.

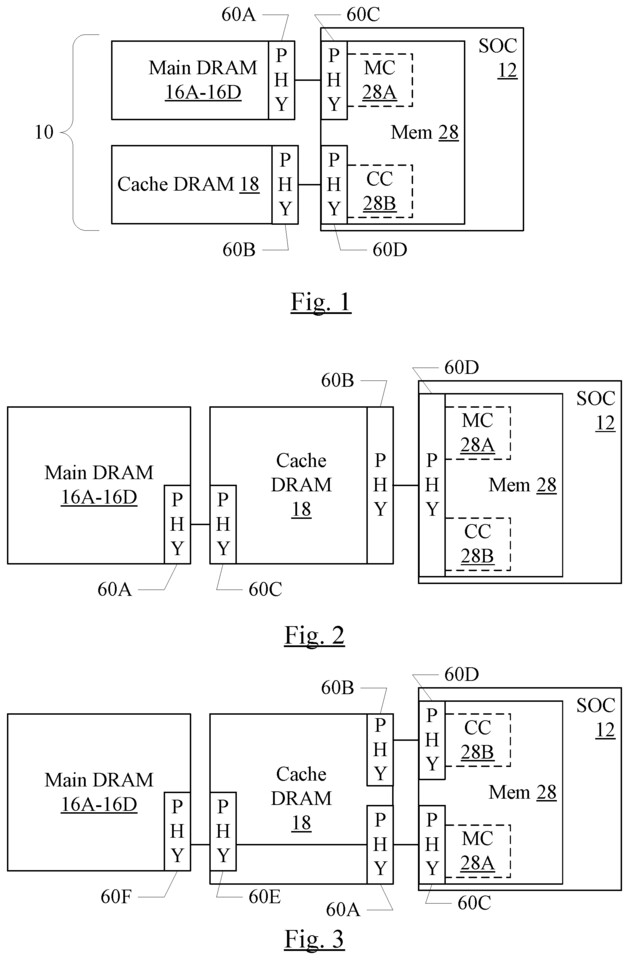

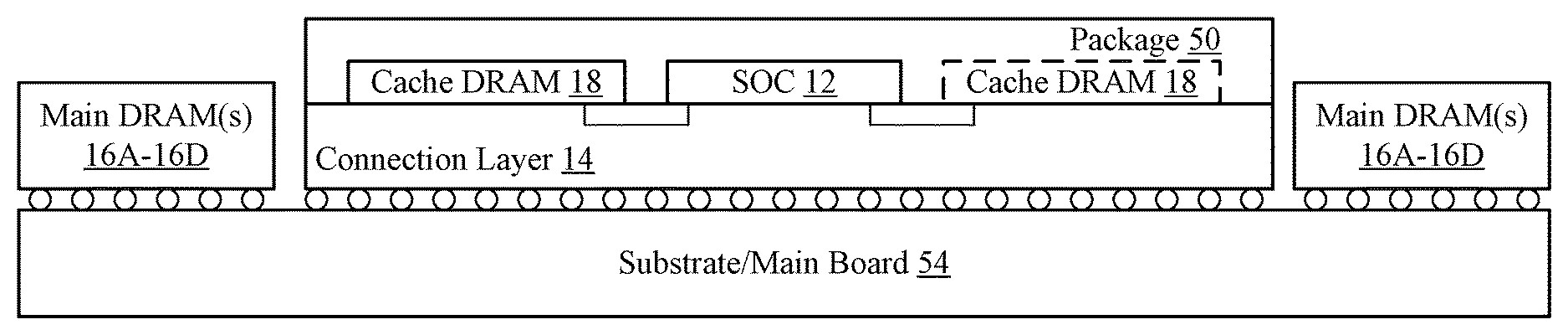
Kerry Creeron—an attorney with the firm of Banner & Witcoff. said:High-level, the patent covers a memory system having a cache DRAM and that is coupled to a main DRAM. The cache DRAM is less dense and has lower energy consumption than the main DRAM. The cache DRAM may also have higher performance. A variety of different layouts are illustrated for connecting the main and cache DRAM ICs, e.g. in FIGS. 8-13. One interesting layout involves through silicon vias (TSVs) that pass through a stack of main DRAM memory chips.
Theoretically, such layouts might be useful for adding additional slower DRAM to Apple's M1 chip architecture.
Finally, I note that the lead inventor, Biswas, was with PA Semi before Apple Acquired it.
View at TechPowerUp Main Site




")