- Joined
- Aug 19, 2017
- Messages
- 3,233 (1.12/day)
Graphics cards have been developed over the years so that they feature multi-level cache hierarchies. These levels of cache have been engineered to fill in the gap between memory and compute, a growing problem that cripples the performance of GPUs in many applications. Different GPU vendors, like AMD and NVIDIA, have different sizes of register files, L1, and L2 caches, depending on the architecture. For example, the amount of L2 cache on NVIDIA's A100 GPU is 40 MB, which is seven times larger compared to the previous generation V100. That just shows how much new applications require bigger cache sizes, which is ever-increasing to satisfy the needs.
Today, we have an interesting report coming from Chips and Cheese. The website has decided to measure GPU memory latency of the latest generation of cards - AMD's RDNA 2 and NVIDIA's Ampere. By using simple pointer chasing tests in OpenCL, we get interesting results. RDNA 2 cache is fast and massive. Compared to Ampere, cache latency is much lower, while the VRAM latency is about the same. NVIDIA uses a two-level cache system consisting out of L1 and L2, which seems to be a rather slow solution. Data coming from Ampere's SM, which holds L1 cache, to the outside L2 is taking over 100 ns of latency.

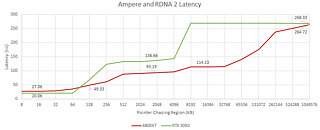
AMD on the other hand has a three-level cache system. There are L0, L1, and L2 cache levels to complement the RDNA 2 design. The latency between the L0 and L2, even with L1 between them, is just 66 ns. Infinity Cache, which is an L3 cache essentially, is adding only additional 20 ns of additional latency, making it still faster compared to NVIDIA's cache solutions. NVIDIA's GA102 massive die seems to represent a big problem for the L2 cache to go around it and many cycles are taken. You can read more about the test here.
View at TechPowerUp Main Site
Today, we have an interesting report coming from Chips and Cheese. The website has decided to measure GPU memory latency of the latest generation of cards - AMD's RDNA 2 and NVIDIA's Ampere. By using simple pointer chasing tests in OpenCL, we get interesting results. RDNA 2 cache is fast and massive. Compared to Ampere, cache latency is much lower, while the VRAM latency is about the same. NVIDIA uses a two-level cache system consisting out of L1 and L2, which seems to be a rather slow solution. Data coming from Ampere's SM, which holds L1 cache, to the outside L2 is taking over 100 ns of latency.

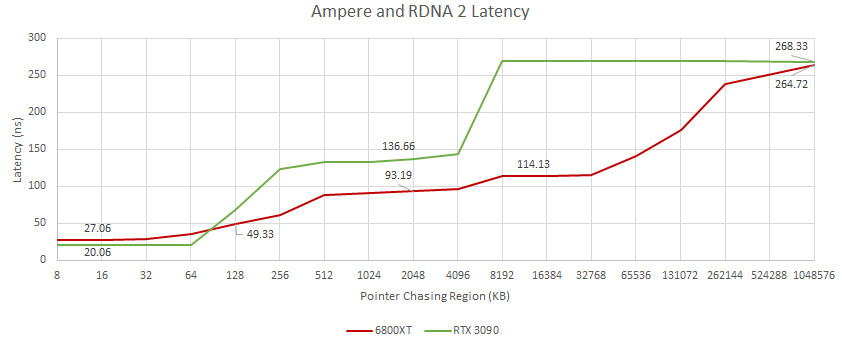
AMD on the other hand has a three-level cache system. There are L0, L1, and L2 cache levels to complement the RDNA 2 design. The latency between the L0 and L2, even with L1 between them, is just 66 ns. Infinity Cache, which is an L3 cache essentially, is adding only additional 20 ns of additional latency, making it still faster compared to NVIDIA's cache solutions. NVIDIA's GA102 massive die seems to represent a big problem for the L2 cache to go around it and many cycles are taken. You can read more about the test here.
View at TechPowerUp Main Site


