- Joined
- Oct 9, 2007
- Messages
- 47,695 (7.42/day)
- Location
- Dublin, Ireland
| System Name | RBMK-1000 |
|---|---|
| Processor | AMD Ryzen 7 5700G |
| Motherboard | Gigabyte B550 AORUS Elite V2 |
| Cooling | DeepCool Gammax L240 V2 |
| Memory | 2x 16GB DDR4-3200 |
| Video Card(s) | Galax RTX 4070 Ti EX |
| Storage | Samsung 990 1TB |
| Display(s) | BenQ 1440p 60 Hz 27-inch |
| Case | Corsair Carbide 100R |
| Audio Device(s) | ASUS SupremeFX S1220A |
| Power Supply | Cooler Master MWE Gold 650W |
| Mouse | ASUS ROG Strix Impact |
| Keyboard | Gamdias Hermes E2 |
| Software | Windows 11 Pro |
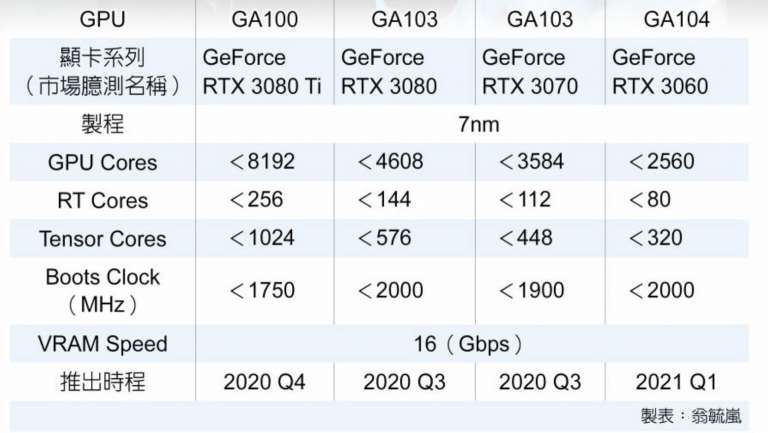
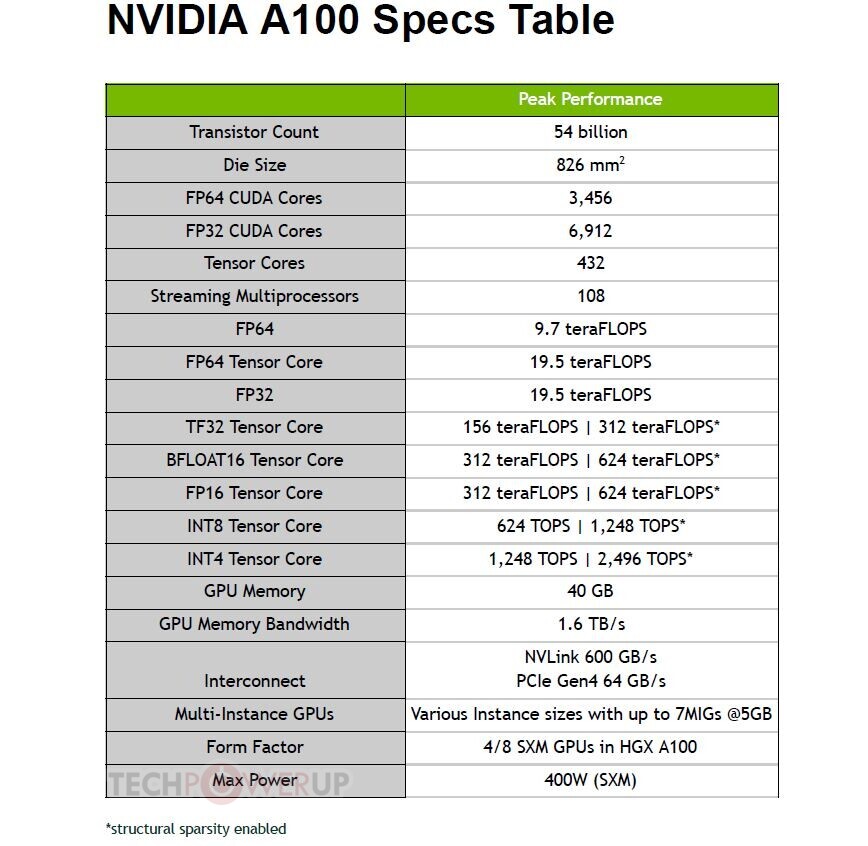
NVIDIA today unveiled the GTC 2020, online event, and the centerpiece of it all is the GA100 scalar processor GPU, which debuts the "Ampere" graphics architecture. Sifting through a mountain of content, we finally found the slide that matters the most - the specifications sheet of GA100. The GA100 is a multi-chip module that has the 7 nm GPU die at the center, and six HBM2E memory stacks at its either side. The GPU die is built on the TSMC N7P 7 nm silicon fabrication process, measures 826 mm², and packing an unfathomable 54 billion transistors - and we're not even counting the transistors on the HBM2E stacks of the interposer.
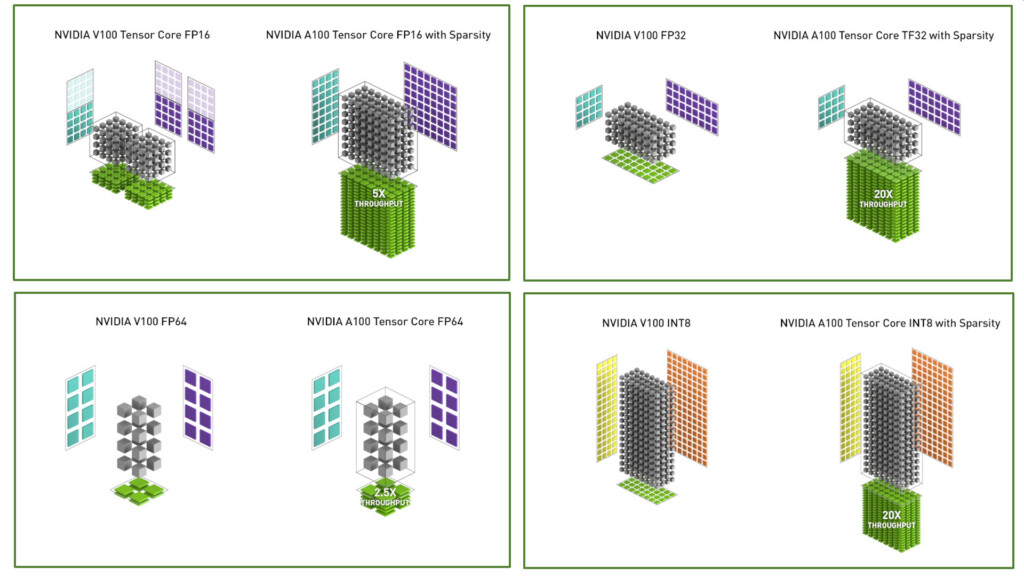
The GA100 packs 6,912 FP32 CUDA cores, and independent 3,456 FP64 (double-precision) CUDA cores. It has 432 third-generation tensor cores that have FP64 capability. The three are spread across a gargantuan 108 streaming multiprocessors. The GPU has 40 GB of total memory, across a 6144-bit wide HBM2E memory interface, and 1.6 TB/s total memory bandwidth. It has two interconnects: a PCI-Express 4.0 x16 (64 GB/s), and an NVLink interconnect (600 GB/s). Compute throughput values are mind-blowing: 19.5 TFLOPs classic FP32, 9.7 TFLOPs classic FP64, and 19.5 TFLOPs tensor cores; TF32 156 TFLOPs single-precision (312 TFLOPs with neural net sparsity enabled); 312 TFLOPs BFLOAT16 throughout (doubled with sparsity enabled); 312 TFLOPs FP16; 624 TOPs INT8, and 1,248 TOPS INT4. The GPU has a typical power draw of 400 W in the SXM form-factor. We also found the architecture diagram that reveals GA100 to be two almost-independent GPUs placed on a single slab of silicon. We also have our first view of the "Ampere" streaming multiprocessor with its FP32 and FP64 CUDA cores, and 3rd gen tensor cores. The GeForce version of this SM could feature 2nd gen RT cores.




View at TechPowerUp Main Site
The GA100 packs 6,912 FP32 CUDA cores, and independent 3,456 FP64 (double-precision) CUDA cores. It has 432 third-generation tensor cores that have FP64 capability. The three are spread across a gargantuan 108 streaming multiprocessors. The GPU has 40 GB of total memory, across a 6144-bit wide HBM2E memory interface, and 1.6 TB/s total memory bandwidth. It has two interconnects: a PCI-Express 4.0 x16 (64 GB/s), and an NVLink interconnect (600 GB/s). Compute throughput values are mind-blowing: 19.5 TFLOPs classic FP32, 9.7 TFLOPs classic FP64, and 19.5 TFLOPs tensor cores; TF32 156 TFLOPs single-precision (312 TFLOPs with neural net sparsity enabled); 312 TFLOPs BFLOAT16 throughout (doubled with sparsity enabled); 312 TFLOPs FP16; 624 TOPs INT8, and 1,248 TOPS INT4. The GPU has a typical power draw of 400 W in the SXM form-factor. We also found the architecture diagram that reveals GA100 to be two almost-independent GPUs placed on a single slab of silicon. We also have our first view of the "Ampere" streaming multiprocessor with its FP32 and FP64 CUDA cores, and 3rd gen tensor cores. The GeForce version of this SM could feature 2nd gen RT cores.


View at TechPowerUp Main Site



")

 Sorry what ? RDNA2 is going to follow the same route by implementing fixed function silicon , what are you talking about ?
Sorry what ? RDNA2 is going to follow the same route by implementing fixed function silicon , what are you talking about ?