Thursday, May 14th 2020

NVIDIA GA100 Scalar Processor Specs Sheet Released
NVIDIA today unveiled the GTC 2020, online event, and the centerpiece of it all is the GA100 scalar processor GPU, which debuts the "Ampere" graphics architecture. Sifting through a mountain of content, we finally found the slide that matters the most - the specifications sheet of GA100. The GA100 is a multi-chip module that has the 7 nm GPU die at the center, and six HBM2E memory stacks at its either side. The GPU die is built on the TSMC N7P 7 nm silicon fabrication process, measures 826 mm², and packing an unfathomable 54 billion transistors - and we're not even counting the transistors on the HBM2E stacks of the interposer.
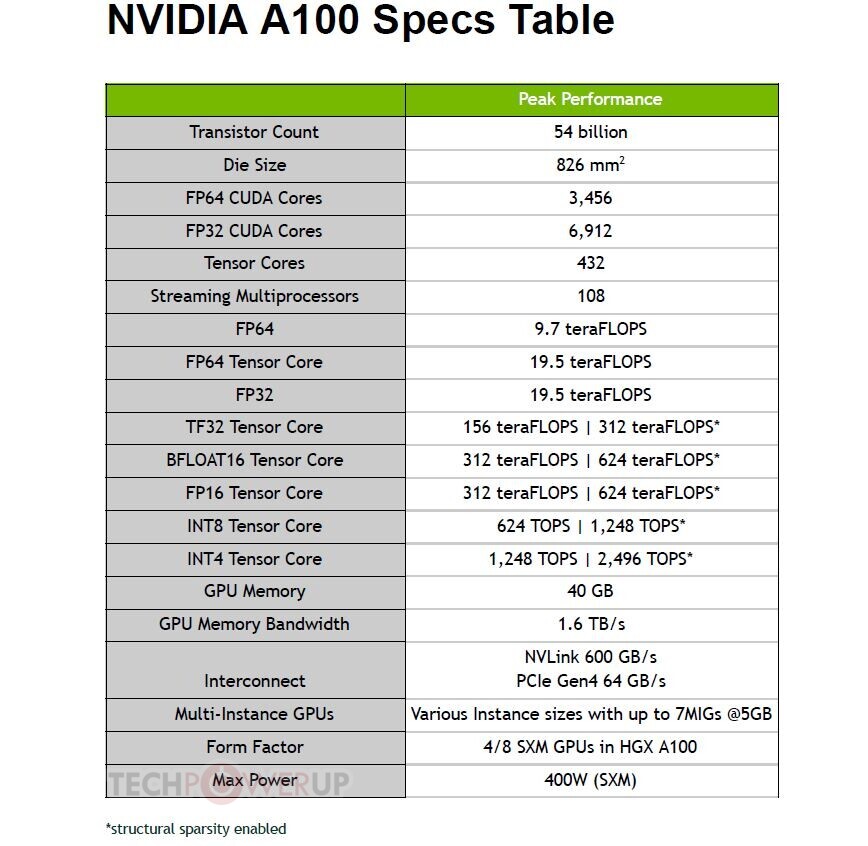
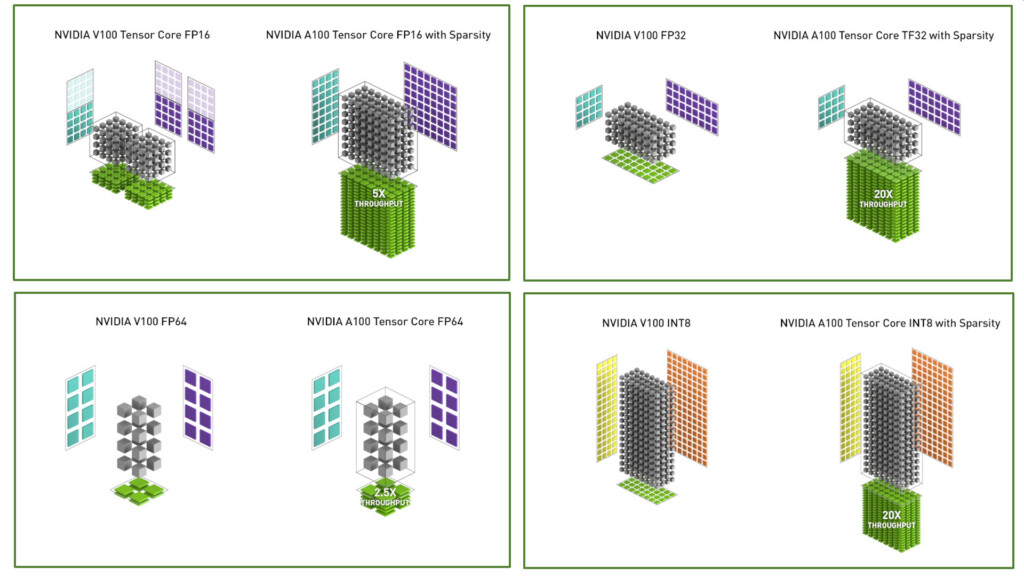
The GA100 packs 6,912 FP32 CUDA cores, and independent 3,456 FP64 (double-precision) CUDA cores. It has 432 third-generation tensor cores that have FP64 capability. The three are spread across a gargantuan 108 streaming multiprocessors. The GPU has 40 GB of total memory, across a 6144-bit wide HBM2E memory interface, and 1.6 TB/s total memory bandwidth. It has two interconnects: a PCI-Express 4.0 x16 (64 GB/s), and an NVLink interconnect (600 GB/s). Compute throughput values are mind-blowing: 19.5 TFLOPs classic FP32, 9.7 TFLOPs classic FP64, and 19.5 TFLOPs tensor cores; TF32 156 TFLOPs single-precision (312 TFLOPs with neural net sparsity enabled); 312 TFLOPs BFLOAT16 throughout (doubled with sparsity enabled); 312 TFLOPs FP16; 624 TOPs INT8, and 1,248 TOPS INT4. The GPU has a typical power draw of 400 W in the SXM form-factor. We also found the architecture diagram that reveals GA100 to be two almost-independent GPUs placed on a single slab of silicon. We also have our first view of the "Ampere" streaming multiprocessor with its FP32 and FP64 CUDA cores, and 3rd gen tensor cores. The GeForce version of this SM could feature 2nd gen RT cores.



The GA100 packs 6,912 FP32 CUDA cores, and independent 3,456 FP64 (double-precision) CUDA cores. It has 432 third-generation tensor cores that have FP64 capability. The three are spread across a gargantuan 108 streaming multiprocessors. The GPU has 40 GB of total memory, across a 6144-bit wide HBM2E memory interface, and 1.6 TB/s total memory bandwidth. It has two interconnects: a PCI-Express 4.0 x16 (64 GB/s), and an NVLink interconnect (600 GB/s). Compute throughput values are mind-blowing: 19.5 TFLOPs classic FP32, 9.7 TFLOPs classic FP64, and 19.5 TFLOPs tensor cores; TF32 156 TFLOPs single-precision (312 TFLOPs with neural net sparsity enabled); 312 TFLOPs BFLOAT16 throughout (doubled with sparsity enabled); 312 TFLOPs FP16; 624 TOPs INT8, and 1,248 TOPS INT4. The GPU has a typical power draw of 400 W in the SXM form-factor. We also found the architecture diagram that reveals GA100 to be two almost-independent GPUs placed on a single slab of silicon. We also have our first view of the "Ampere" streaming multiprocessor with its FP32 and FP64 CUDA cores, and 3rd gen tensor cores. The GeForce version of this SM could feature 2nd gen RT cores.


101 Comments on NVIDIA GA100 Scalar Processor Specs Sheet Released
Edit: Is it possible to have 1.6 GB per wafer in a stack?
Edit #2: Oh and on an unrelated note, it was just released that Nvidia is dropping Xeon and going with Epyc for its complete server solutions.
Are you willing to pay $1500 for a potential RTX 3080 Ti or would you prefer if AMD releases a $700 Navi 21 that is as fast as RTX 3080 Ti ?
Jokes aside ofc i get what you mean and agree 100% competition is always good , but let's wait and see what each company has to offer this time around before making unrealistic expectations .
Here's hoping that Ampere as is in this instance wont power any consumer graphics because the outlook would be grim, we would be looking at another barley incremental performance increase.
www.techpowerup.com/267090/nvidia-ampere-designed-for-both-hpc-and-geforce-quadro
By the way I've just noticed the power :), 400W, that's 150W over V100. Ouch, 7nm hasn't been kind, I was right that this is a power hungry monster.
About the absurd prices of Turing ( which we all agree they are ) nothing indicates that fixed function silicon is the cause for it . Quite the oposite considering from what we know fixed function silicon takes very little die space , so what makes you objectively believe this is the reason of said absurd prices ? The only objective reason is lack of competition from AMD !:shadedshu: Sorry what ? RDNA2 is going to follow the same route by implementing fixed function silicon , what are you talking about ?
Some of what your saying is wrong ,it takes up quite a lot of die space relatively hence Nvidia's large die sizes which are added to by the requirements of extra cache resources and hardware needed to keep the special units busy.
The other reason being because they can, and to make more money, it's not rocket science just business, people should have chosen with their wallet's.
Any talk of their competition's version is hearsay at this point ,no argument required.
GA102 will be the gaming\consumer version
They could be legit future specs still If you count cuda core's equally (cuda64 and cuda32 cores), perhaps.
devblogs.nvidia.com/nvidia-ampere-architecture-in-depth/
What I understand is that raytracing on RDNA2 uses a part of regular shaders. I honestly haven't seen anything about dedicated hardware.
The GA100 is the full fat 8192 GPU.