- Joined
- Aug 19, 2017
- Messages
- 3,082 (1.09/day)
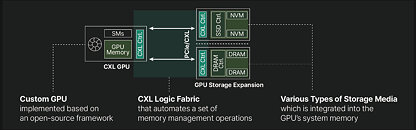
South Korean startup Panmnesia has unveiled an interesting solution to address the memory limitations of modern GPUs. The company has developed a low-latency Compute Express Link (CXL) IP that could help expand GPU memory with external add-in card. Current GPU-accelerated applications in AI and HPC are constrained by the set amount of memory built into GPUs. With data sizes growing by 3x yearly, GPU networks must keep getting larger just to fit the application in the local memory, benefiting latency and token generation. Panmnesia's proposed approach to fix this leverages the CXL protocol to expand GPU memory capacity using PCIe-connected DRAM or even SSDs. The company has overcome significant technical hurdles, including the absence of CXL logic fabric in GPUs and the limitations of existing unified virtual memory (UVM) systems.
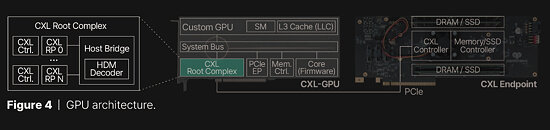
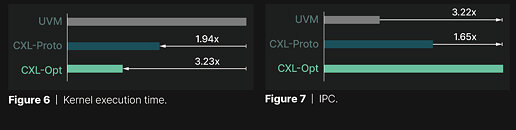
At the heart of Panmnesia's solution is a CXL 3.1-compliant root complex with multiple root ports and a host bridge featuring a host-managed device memory (HDM) decoder. This sophisticated system effectively tricks the GPU's memory subsystem into treating PCIe-connected memory as native system memory. Extensive testing has demonstrated impressive results. Panmnesia's CXL solution, CXL-Opt, achieved two-digit nanosecond round-trip latency, significantly outperforming both UVM and earlier CXL prototypes. In GPU kernel execution tests, CXL-Opt showed execution times up to 3.22 times faster than UVM. Older CXL memory extenders recorded around 250 nanoseconds round trip latency, with CXL-Opt potentially achieving less than 80 nanoseconds. As with CXL, the problem is usually that the memory pools add up latency and performance degrades, while these CXL extenders tend to add to the cost model as well. However, the Panmnesia CXL-Opt could find a use case, and we are waiting to see if anyone adopts this in their infrastructure.


Below are some benchmarks by Panmnesia, as well as the architecture of the CXL-Opt.
View at TechPowerUp Main Site | Source
At the heart of Panmnesia's solution is a CXL 3.1-compliant root complex with multiple root ports and a host bridge featuring a host-managed device memory (HDM) decoder. This sophisticated system effectively tricks the GPU's memory subsystem into treating PCIe-connected memory as native system memory. Extensive testing has demonstrated impressive results. Panmnesia's CXL solution, CXL-Opt, achieved two-digit nanosecond round-trip latency, significantly outperforming both UVM and earlier CXL prototypes. In GPU kernel execution tests, CXL-Opt showed execution times up to 3.22 times faster than UVM. Older CXL memory extenders recorded around 250 nanoseconds round trip latency, with CXL-Opt potentially achieving less than 80 nanoseconds. As with CXL, the problem is usually that the memory pools add up latency and performance degrades, while these CXL extenders tend to add to the cost model as well. However, the Panmnesia CXL-Opt could find a use case, and we are waiting to see if anyone adopts this in their infrastructure.


Below are some benchmarks by Panmnesia, as well as the architecture of the CXL-Opt.




View at TechPowerUp Main Site | Source







