TheLostSwede
News Editor
- Joined
- Nov 11, 2004
- Messages
- 18,493 (2.47/day)
- Location
- Sweden
| System Name | Overlord Mk MLI |
|---|---|
| Processor | AMD Ryzen 7 7800X3D |
| Motherboard | Gigabyte X670E Aorus Master |
| Cooling | Noctua NH-D15 SE with offsets |
| Memory | 32GB Team T-Create Expert DDR5 6000 MHz @ CL30-34-34-68 |
| Video Card(s) | Gainward GeForce RTX 4080 Phantom GS |
| Storage | 1TB Solidigm P44 Pro, 2 TB Corsair MP600 Pro, 2TB Kingston KC3000 |
| Display(s) | Acer XV272K LVbmiipruzx 4K@160Hz |
| Case | Fractal Design Torrent Compact |
| Audio Device(s) | Corsair Virtuoso SE |
| Power Supply | be quiet! Pure Power 12 M 850 W |
| Mouse | Logitech G502 Lightspeed |
| Keyboard | Corsair K70 Max |
| Software | Windows 10 Pro |
| Benchmark Scores | https://valid.x86.fr/yfsd9w |
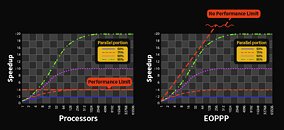
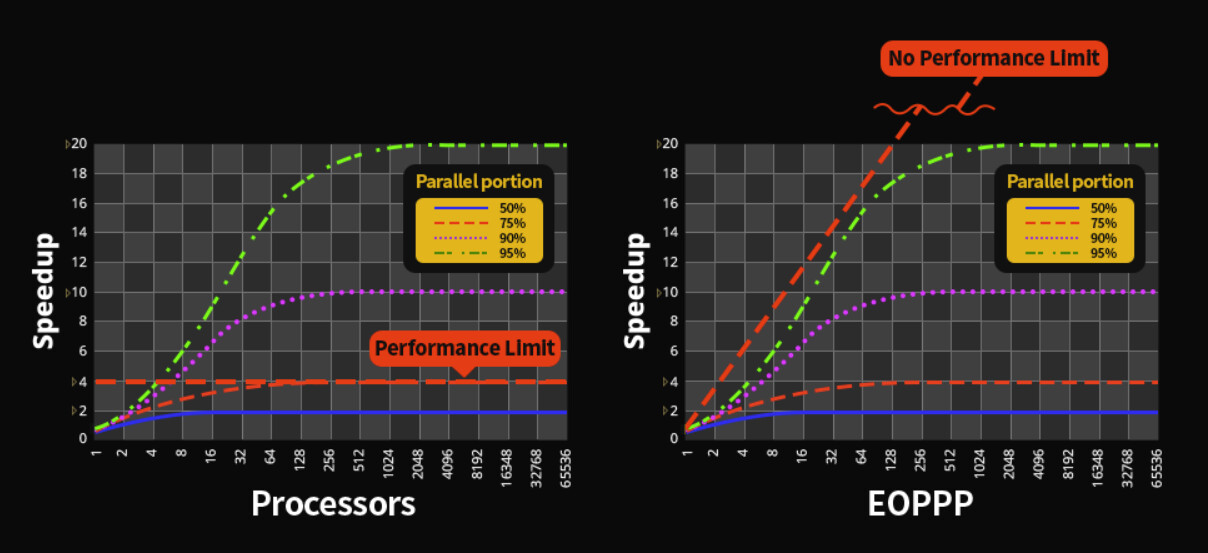
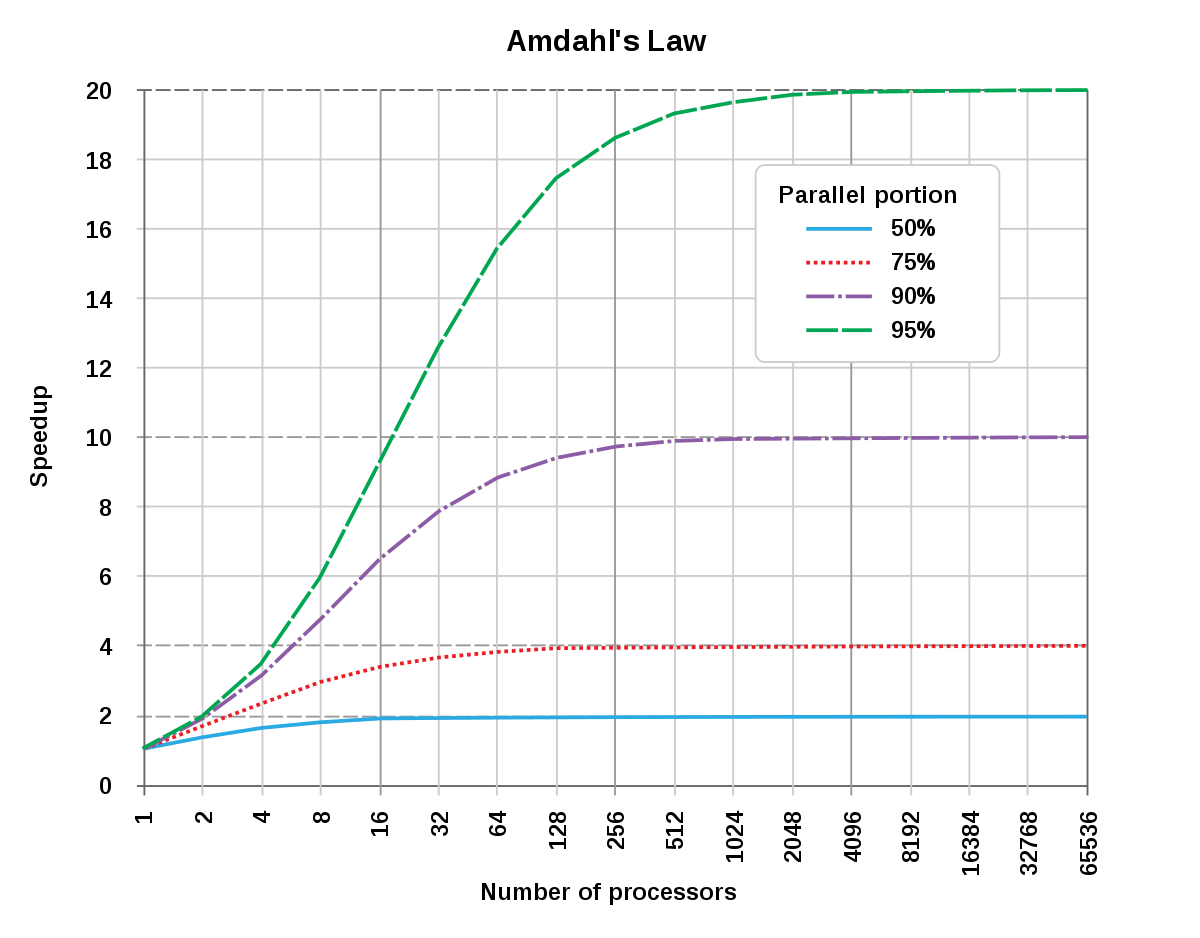
One of the biggest drawbacks of modern CPUs is that adding more cores doesn't equal more performance in a linear fashion. Parallelism in CPUs offer limited scaling for most applications and even none for some. A South Korean company called Morumi is now taking a stab at solving this problem and wants to develop a CPU that can offer more or less infinite processing scaling, as more cores are added. The company has been around since 2018 and focused on various telecommunications chips, but has now started the development on what it calls every one period parallel processor (EOPPP) technology.
EOPPP is said to distribute data to each of the cores in a CPU before the data is being processed, which is said to be done over a type of mesh network inside the CPU. This is said to allow for an almost unlimited amount of instructions to be handled at once, if the CPU has enough cores. Morumi already has an early 32-core prototype running on an FPGA and in certain tasks the company has seen a tenfold performance increase. It should be noted that this requires software specifically compiled for EOPPP and Moumi is set to release version 1.0 of its compiler later this year. It's still early days, but it'll be interesting to see how this technology develops, but if it's successfully developed, there's also a high chance of Morumi being acquired by someone much bigger that wants to integrate the technology into their own products.
View at TechPowerUp Main Site | Source
EOPPP is said to distribute data to each of the cores in a CPU before the data is being processed, which is said to be done over a type of mesh network inside the CPU. This is said to allow for an almost unlimited amount of instructions to be handled at once, if the CPU has enough cores. Morumi already has an early 32-core prototype running on an FPGA and in certain tasks the company has seen a tenfold performance increase. It should be noted that this requires software specifically compiled for EOPPP and Moumi is set to release version 1.0 of its compiler later this year. It's still early days, but it'll be interesting to see how this technology develops, but if it's successfully developed, there's also a high chance of Morumi being acquired by someone much bigger that wants to integrate the technology into their own products.
View at TechPowerUp Main Site | Source

 made me laugh, it's staying, now where are those glasses.
made me laugh, it's staying, now where are those glasses. ")

")