- Joined
- Oct 9, 2007
- Messages
- 47,727 (7.42/day)
- Location
- Dublin, Ireland
| System Name | RBMK-1000 |
|---|---|
| Processor | AMD Ryzen 7 5700G |
| Motherboard | Gigabyte B550 AORUS Elite V2 |
| Cooling | DeepCool Gammax L240 V2 |
| Memory | 2x 16GB DDR4-3200 |
| Video Card(s) | Galax RTX 4070 Ti EX |
| Storage | Samsung 990 1TB |
| Display(s) | BenQ 1440p 60 Hz 27-inch |
| Case | Corsair Carbide 100R |
| Audio Device(s) | ASUS SupremeFX S1220A |
| Power Supply | Cooler Master MWE Gold 650W |
| Mouse | ASUS ROG Strix Impact |
| Keyboard | Gamdias Hermes E2 |
| Software | Windows 11 Pro |
Tachyum Inc. today announced that it has successfully completed a demonstration showing its Prodigy Universal Processor running faster than any other processor, HPC or AI chips, including ones from NVIDIA and Intel. This is the latest of many recent milestones achieved by Tachyum as the company continues its march towards Prodigy's product release next year.
Tachyum demonstrated how its computational operation and the speed of its product design, using an industry-standard Verilog simulation of the actual Prodigy post layout hardware, is the superior solution to current competitive offerings. Not only does Prodigy execute instructions at very high speeds, but Tachyum now has an infrastructure implemented for automatically checking correct results from the Verilog RTL. These automated tests check Verilog output for correctness compared to Tachyum's C-model, which was used to measure performance, and is now the 'Golden Model' for the Verilog hardware simulation to ensure it produces identical, step-by-step results.
This verification milestone dramatically increases Tachyum's productivity and its ability to test the Prodigy hardware design efficiently in order to find bugs and correct them prior to tape-out. With this latest accomplishment, Tachyum now has automated the constrained random test generation capability, which further adds to its productivity.
Tachyum's previous hardware design milestone was to build components and interconnect them, which was successfully completed in April. The most recent hardware design milestone - and resulting tool - is about the Prodigy processor producing correct results and its performance on test programs. Prodigy is now handling branch mispredictions, or compiler misprediction of memory dependency, whereupon it detects, recovers and produces correct results.
Thanks to Tachyum's IP suppliers, the company is now able to do read/writes from Prodigy communications mesh to its DDR5 DIMMs hardware memory models. The global clock is now connected from the PLL to Prodigy cores. RAMBIST and other manufacturability features are now integrated into the Prodigy hardware design in large part due to Tachyum's physical design partner.
"This latest hardware milestone is a testament to the diligent work of our engineering team and the vast human resources we have been able to assemble to complete a revolutionary solution never before seen," said Dr. Radoslav Danilak, Tachyum founder and CEO. "We set out to produce the highest performance, lowest energy and most cost-efficient processor for the hyperscale, HPC and AI marketplace, and these milestones are proving that we are achieving those goals. With a product that is faster than the fastest Intel Xeon or NVIDIA A100 Chips, Prodigy is nearing all of its stated objectives and remains on track to make its debut as planned next year."
Tachyum's Prodigy can run HPC applications, convolution AI, explainable AI, general AI, bio AI and spiking neural networks, as well as normal data center workloads on a single homogeneous processor platform with its simple programming model. Using CPU, GPU, TPU and other accelerators in lieu of Prodigy for these different types of workloads is inefficient. A heterogeneous processing fabric, with unique hardware dedicated to each type of workload (e.g. data center, AI, HPC), results in underutilization of hardware resources, and a more challenging programming environment. Prodigy's ability to seamlessly switch among these various workloads dramatically changes the competitive landscape and the economics of data centers.
Prodigy significantly improves computational performance, energy consumption, hardware (server) utilization and space requirements compared to existing chips provisioned in hyperscale data centers today. It will also allow Edge developers for IoT to exploit its low power and high performance, along with its simple programming model to deliver AI to the edge.
Prodigy is truly a universal processor. In addition to native Prodigy code, it also runs legacy x86, ARM and RISC-V binaries. And, with a single, highly efficient processor architecture, Prodigy delivers industry-leading performance across data center, AI, and HPC workloads. Prodigy, the company's flagship Universal Processor, will enter volume production in 2021. In April the Prodigy chip successfully proved its viability with a complete chip layout exceeding speed targets. In August the processor is able to correctly execute short programs, with results automatically verified against the software model, while exceeding the target clock speeds. The next step is to get a manufactured wholly functional FPGA prototype of the chip later this year, which is the last milestone before tape-out.
Prodigy outperforms the fastest Xeon processors at 10x lower power on data center workloads, as well as outperforming NVIDIA's fastest GPU on HPC, AI training and inference. The 125 HPC Prodigy racks can deliver a 32 tensor EXAFLOPS. Prodigy's 3X lower cost per MIPS and 10X lower power translates to a 4X lower data center Total Cost of Ownership (TCO), enables billions of dollars of savings for hyperscalers such as Google, Facebook, Amazon, Alibaba, and others. Since Prodigy is the world's only processor that can switch between data center, AI and HPC workloads, unused servers can be used as CAPEX-free AI or HPC cloud, because the servers have already been amortized.
For demo resources and videos, visit this page.
View at TechPowerUp Main Site
Tachyum demonstrated how its computational operation and the speed of its product design, using an industry-standard Verilog simulation of the actual Prodigy post layout hardware, is the superior solution to current competitive offerings. Not only does Prodigy execute instructions at very high speeds, but Tachyum now has an infrastructure implemented for automatically checking correct results from the Verilog RTL. These automated tests check Verilog output for correctness compared to Tachyum's C-model, which was used to measure performance, and is now the 'Golden Model' for the Verilog hardware simulation to ensure it produces identical, step-by-step results.
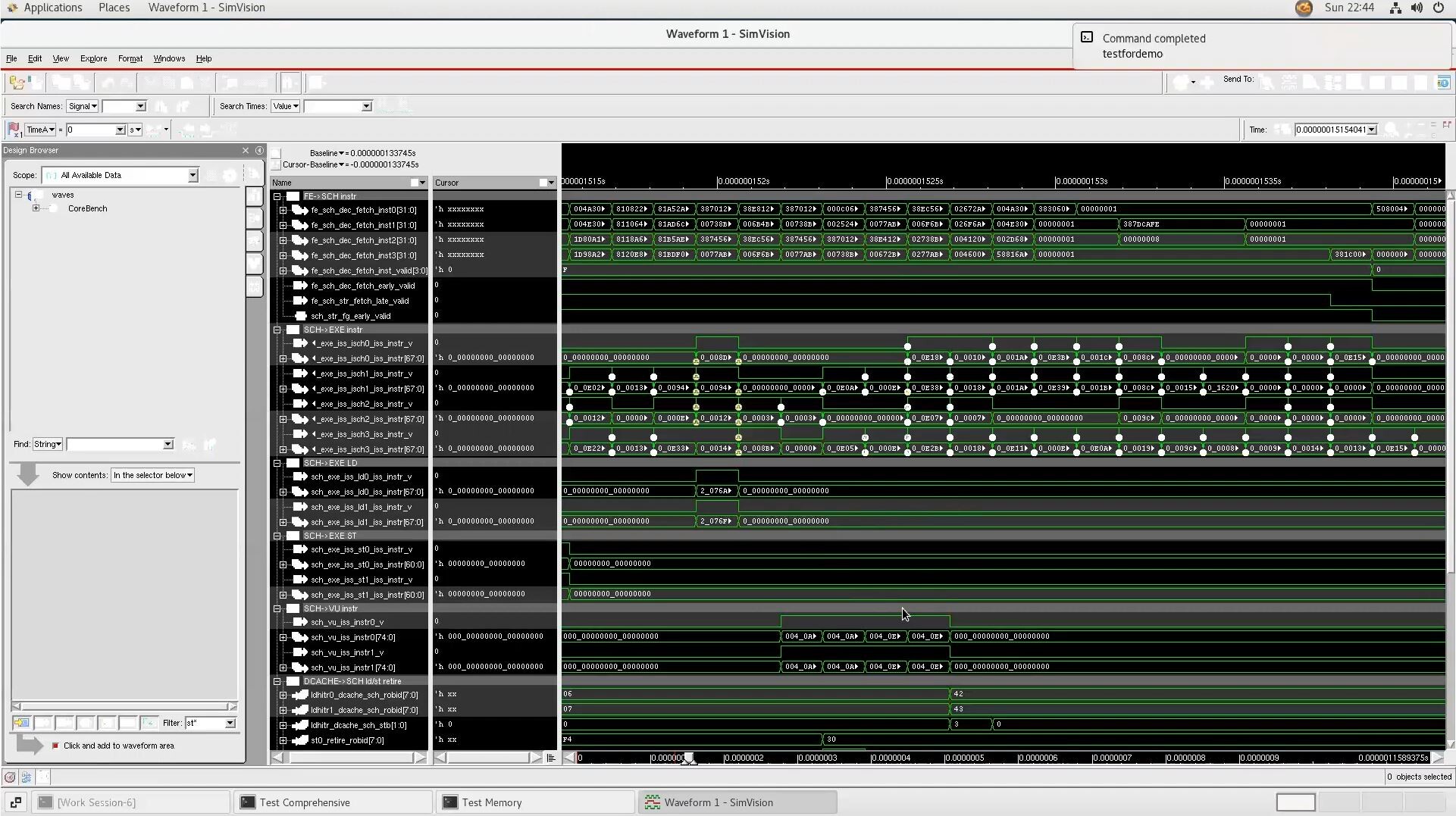
This verification milestone dramatically increases Tachyum's productivity and its ability to test the Prodigy hardware design efficiently in order to find bugs and correct them prior to tape-out. With this latest accomplishment, Tachyum now has automated the constrained random test generation capability, which further adds to its productivity.
Tachyum's previous hardware design milestone was to build components and interconnect them, which was successfully completed in April. The most recent hardware design milestone - and resulting tool - is about the Prodigy processor producing correct results and its performance on test programs. Prodigy is now handling branch mispredictions, or compiler misprediction of memory dependency, whereupon it detects, recovers and produces correct results.
Thanks to Tachyum's IP suppliers, the company is now able to do read/writes from Prodigy communications mesh to its DDR5 DIMMs hardware memory models. The global clock is now connected from the PLL to Prodigy cores. RAMBIST and other manufacturability features are now integrated into the Prodigy hardware design in large part due to Tachyum's physical design partner.
"This latest hardware milestone is a testament to the diligent work of our engineering team and the vast human resources we have been able to assemble to complete a revolutionary solution never before seen," said Dr. Radoslav Danilak, Tachyum founder and CEO. "We set out to produce the highest performance, lowest energy and most cost-efficient processor for the hyperscale, HPC and AI marketplace, and these milestones are proving that we are achieving those goals. With a product that is faster than the fastest Intel Xeon or NVIDIA A100 Chips, Prodigy is nearing all of its stated objectives and remains on track to make its debut as planned next year."
Tachyum's Prodigy can run HPC applications, convolution AI, explainable AI, general AI, bio AI and spiking neural networks, as well as normal data center workloads on a single homogeneous processor platform with its simple programming model. Using CPU, GPU, TPU and other accelerators in lieu of Prodigy for these different types of workloads is inefficient. A heterogeneous processing fabric, with unique hardware dedicated to each type of workload (e.g. data center, AI, HPC), results in underutilization of hardware resources, and a more challenging programming environment. Prodigy's ability to seamlessly switch among these various workloads dramatically changes the competitive landscape and the economics of data centers.
Prodigy significantly improves computational performance, energy consumption, hardware (server) utilization and space requirements compared to existing chips provisioned in hyperscale data centers today. It will also allow Edge developers for IoT to exploit its low power and high performance, along with its simple programming model to deliver AI to the edge.
Prodigy is truly a universal processor. In addition to native Prodigy code, it also runs legacy x86, ARM and RISC-V binaries. And, with a single, highly efficient processor architecture, Prodigy delivers industry-leading performance across data center, AI, and HPC workloads. Prodigy, the company's flagship Universal Processor, will enter volume production in 2021. In April the Prodigy chip successfully proved its viability with a complete chip layout exceeding speed targets. In August the processor is able to correctly execute short programs, with results automatically verified against the software model, while exceeding the target clock speeds. The next step is to get a manufactured wholly functional FPGA prototype of the chip later this year, which is the last milestone before tape-out.
Prodigy outperforms the fastest Xeon processors at 10x lower power on data center workloads, as well as outperforming NVIDIA's fastest GPU on HPC, AI training and inference. The 125 HPC Prodigy racks can deliver a 32 tensor EXAFLOPS. Prodigy's 3X lower cost per MIPS and 10X lower power translates to a 4X lower data center Total Cost of Ownership (TCO), enables billions of dollars of savings for hyperscalers such as Google, Facebook, Amazon, Alibaba, and others. Since Prodigy is the world's only processor that can switch between data center, AI and HPC workloads, unused servers can be used as CAPEX-free AI or HPC cloud, because the servers have already been amortized.
For demo resources and videos, visit this page.
View at TechPowerUp Main Site








")