Monday, July 11th 2011

AMD FX-8130P Processor Benchmarks Surface
Here is a tasty scoop of benchmark results purported to be those of the AMD FX-8130P, the next high-end processor from the green team. The FX-8130P was paired with Gigabyte 990FXA-UD5 motherboard and 4 GB of dual-channel Kingston HyperX DDR3-2000 MHz memory running at DDR3-1866 MHz. A GeForce GTX 580 handled the graphics department. The chip was clocked at 3.20 GHz (16 x 200 MHz). Testing began with benchmarks that aren't very multi-core intensive, such as Super Pi 1M, where the chip clocked in at 19.5 seconds; AIDA64 Cache and Memory benchmark, where L1 cache seems to be extremely fast, while L2, L3, and memory performance is a slight improvement over the last generation of Phenom II processors.


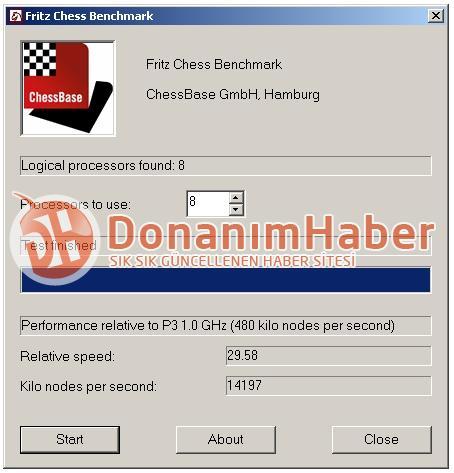
 Moving on to multi-threaded tests, Fritz Chess yielded a speed-up of over 29.5X over the set standard, with 14,197 kilonodes per second. x264 benchmark encoded first pass at roughly 136 fps, with roughly 45 fps in the second pass. The system scored 3045 points in PCMark7, and P6265 in 3DMark11 (performance preset). The results show that this chip will be highly competitive with Intel's LGA1155 Sandy Bridge quad-core chips, but as usual, we ask you to take the data with a pinch of salt.
Moving on to multi-threaded tests, Fritz Chess yielded a speed-up of over 29.5X over the set standard, with 14,197 kilonodes per second. x264 benchmark encoded first pass at roughly 136 fps, with roughly 45 fps in the second pass. The system scored 3045 points in PCMark7, and P6265 in 3DMark11 (performance preset). The results show that this chip will be highly competitive with Intel's LGA1155 Sandy Bridge quad-core chips, but as usual, we ask you to take the data with a pinch of salt.




Source:
DonanimHaber








317 Comments on AMD FX-8130P Processor Benchmarks Surface
What i wan to say... Why not... i cant wait to buy this 8-Core... i still prefer my AMD X6 then my i7 950 because heat... Im live in hot asia... cool processor is better for me...
PS: :toast: to AMD on what ever u do u still the best for me... but i still like your Athlon XP :roll: :laugh:
But the funny thing is HT can increase performance by just 15-25% if the program is optimized and if not It can even degrade your performance. So I am voting for AMD's approach although their naming scheme of 8 cores instead of 4 cores with mega threading:) was a failure on their part and do you know why?
BD 8130 will be compared to SB2600k and in multi-threading it will win but it won't be as significant because everybody will say that was to be expected its a battle between 8 cores versus 4 cores another example a battle between BD against SB-E where it will loose even in MT workload but then It will be how shitty AMD cpu is when a 6 core can win over an 8 core, what isn't true, it was true SB2500 versus Thuban although in some cases Thuban won. They are 4 cores, one uses SMT approach and the other CMT, one gives better performance increase with a 12% increase in core area and the other max 25% and sometimes you have lower score than without it but it costs just 5-7% of die space, yet one is an 8 core and the other 4 core just because it has 2 integer units. Its just not logical calling it an 8 core like Thuban is a 6 core, die area and performance increase in MT is way different.
www.techpowerup.com/img/10-08-25/bulldozer-8.jpg
just by the green parts should be a BD called an 8 core? Thats so stupid when an 8130 or 4 module has 4 identical modules(extended cores) and one module is shown in the picture.
Or I guess you never tOok statistics in school?
Or how about this, you monitor memory I/o, and instead of looking at the app results, you see how it stresses the system, and measure that?
:laugh: or just read the thread.
An FPU and branch predictor are extensions to those already existing units. The FPU is part of the execution unit and the branch preditor is an extension to the front end. It's part of the fetching unit in an out-of-order CPU and cannot operate nor has a purpose outside of it.
Early processors could only operate on integers, but that doesn't change a thing, the execution unit was simply not as advanced. They later added a coprocessor on the MB, but architecturally the FPU was already part of the execution unit and thus, the CPU. And at any rate an FPU cannot operate outside of the CPU, it requires the control unit to fetch and decode the instructions for him. All of them execution units need them, hence why for me 1 fetch and decode unit means 1 core, and always will. A more robust and at the same time more streamlined core probably, but a core nonetheless.
On a very different situation the memory controler is not an integral part of the CPU, it operates outside of the CPU and has a purpose outside of the CPU. It controls the memory whether it's for a CPU, a GPU or an application specific processor, like a sound processor or A/V decoder. Including it in the die, shortens up latencies so it's desirable, but that's all.
When there are huge amounts of thread stalls, and that sort of stuff, this is where HT benefits the most because it can take the other thread and fill in the gaps while the other stalls - keeping the pipes as full as possible.
This most commonly happens is some unique workload types .. but mostly happens when someone writes shitty code.
A program that is written decently will most likely be the least to benefit from HT.
---
I kinda enjoy AMD's approach to this issue, rather than using HT in their cores, knowing the caveats of x86 and sometimes crappy code writers, they sat back and said...whats the point of making the fattest core possible?? - none really because it isnt utilized most of the time 100%. So, they decided to make skinnier, leaner (both transistor and power budget) cores, which have a chance of being, more often times then not, fully utilized. The advantage being that although the cores themselves may be leaner (a tad weaker)... at least 2 threads arent fighting over resources as much as they would be in an HT setup.
But, I do agree w/ some of your guys statements. I see this implementation and the fact AMD is marketing them as 8cores and part of me thinks they should be marketing them as 4 cores yet w/ a significant advantage over HT cores.
I guess thats why, when it comes to it...they are priced really close to intel's 4 core SB's. Because if they were to be priced at the levels of 8 cores then AMD would be doing it wrong.
Shame on you!
x87 is dead
Hail! SSE
Drop support for that is dropping support for that scene. Could my wishes comes true?:laugh:
Not too sure why such a small segment of users drives product design so greatly, anyway, but OK.
i kinda think ASUS' ROG line, GIgabyte UD7 boards, and the other high-end products are a waste of R&D dollars too, technically, as their cost in retail greatly surpasses what most can afford. I mean I udnerstand that stuff from the high-end maybe in a couple fo gens becomes standard, but damn.
Scaling can never be better than +100% per core. And also 140% for 1 core? :laugh: If you want to make up some numbers, I'm sure you can do it better. :roll:
And I'll tell you now that with the shared resources, especially the fetch/decode unit which does 4 Mops/cycle per module, for each "core" that can handle 4 Mops, so 8 per module, scaling is not going to be anywhere near 100% per core, except on some very espeific and rare ocasions.
The maximum that a second core can do is add another 100%, that is, doubling up peak performance and that only under very favorable conditions.
A 3rd core will 3x the performance and so on.
Your over 100% inprovements are pure BS.
Say, CPU can process 1x 80-bit instructions on it's own, being 128-bit.
Now, if it can work with another, together, they can do 3x 80 bit within the 256-bit capabilities, with a bit of room for overhead.
Oh, what's that, suddenly 80-bit SuperPi becomes important?
:laugh: