Tuesday, April 10th 2012

Trinity (Piledriver) Integer/FP Performance Higher Than Bulldozer, Clock-for-Clock
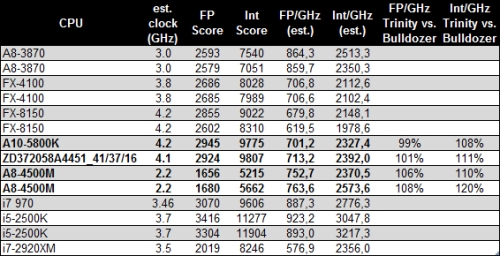
AMD's upcoming "Trinity" family of desktop and mobile accelerated processing units (APUs) will use up to four x86-64 cores based on the company's newest CPU architecture, codenamed "Piledriver". AMD conservatively estimated performance/clock improvements over current-generation "Bulldozer" architecture, with Piledriver. Citavia put next-generation A10-5800K, and A8-4500M "Trinity" desktop and notebook APUs, and pitted them against several currently-launched processors, from both AMD and Intel.
It found integer and floating-point performance increases clock-for-clock, against Bulldozer-based FX-8150. The benchmark is not multi-threaded, and hence gives us a fair idea of the per core performance. On a rather disturbing note, the performance-per-GHz figures of Piledriver are trailing far behind K12 architecture (Llano, A8-3850), let alone competitive architectures from Intel.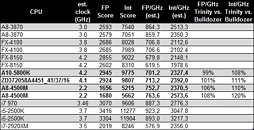
Source:
Expreview
It found integer and floating-point performance increases clock-for-clock, against Bulldozer-based FX-8150. The benchmark is not multi-threaded, and hence gives us a fair idea of the per core performance. On a rather disturbing note, the performance-per-GHz figures of Piledriver are trailing far behind K12 architecture (Llano, A8-3850), let alone competitive architectures from Intel.
115 Comments on Trinity (Piledriver) Integer/FP Performance Higher Than Bulldozer, Clock-for-Clock
A stacked APU with four Steaming modules of two(8) plus 8gig(:pimp:dreamin) of on die memory and dual gcn GPU units wouls be a truely killer App:)
And if the GPU and CPU can read and write to shared cache so the GPU could execute instruction A, C, F, H, I, J, and M, while the CPU runs B which is dependent on A, D & E which are then stored for F to run two iterations of, the checked results are then stored back for the CPU to run G....so on and so forth.
so in essence it seems like both amd and intel are taking a new approach in fetching/decoding to let the hardware decide the execution part to be as efficient as possible, that is by far what the future of computing, to try to take advantage of every piece of silicon on the die, cuz even untill now i cant think of one software that will use even a core2quad or a phenom x4 at 100% on all 4 cores, and making cores fatter and fatter also can only get so far, even intel seems to be slowing down on that approach now that they realize fabrication process shrinking is getting to its limits, and is only getting more difficult
What if Instruction B depends on data from instruction A? or F depends on data from instruction E? Between the PCI-E latency, time it takes for the GPU to execute the instruction, store it, then send it back over PCI-E you just hammered your performance by 10 fold. GPUs aren't designed for procedural code. They're designed to process large amounts of data in a similar fashion and I think you're confusing what a GPU can actually do. GPUs process many kilobytes to many megabytes of data per every instruction, not just two operands.
Learn what you're talking about before you start saying that something can be done when people who do this for a living and have had 8+ years of schooling to do this stuff. Honestly, what you're describing isn't feasible and I think I pointed this out before.
however you have a point and these are pretty much the challenges that both intel and amd go through, but it is possible though
also you need to remember that we are not talking about using a gpu and forgetting the cpu, we are talking about both working together, meaning certain kinds of instructions like the one u stated would most likely be crunched on the cpu, while things like floating point operations would be done by the gpu
also note that there will be no more pci express linking the gpu and cpu when both are integrated together
it seems like you are talking about having a discrete gpu and a cpu doing the method that steevo mentioned but that is NOT the case, we are talking about gpu/cpu integrated in the architecture level
I'm not saying that this is the way things are moving, but with how GPUs and CPUs exist now, there isn't enough coherency between the two architectures to really be able to do as you describe. The CPU still has to dispatch GPU instructions at the software level because there are no instructions that says, use the GPU cores to calculate blar.
Also keep in mind that for a single-threaded, non-optimized application, you have to wait for the last operation to complete before being able to execute the next one. Now this isn't true for modern super-scalar processors, however if the next instruction requires the output of the last, then you have to wait. You can't just execute all the instructions at once. It's not a matter of can it be done, it's a matter of how practical would it be. Right now with how GPUs are designed, providing large sets of data to be calculated at once is the way to go.
What you're describing is some kind of computational "core" that has the ability to do GPU-like calculations on a CPU core and the closest thing to what you're describing is Bulldozer (and most likely its sucessors which will be more like what you're describing) where a Bulldozer "module" contains a number of components for executing threads concurrently where a CPU can have an instruction that computed a Fast Fourier Transform on a matrix (array of data,) where the CPU would have control over so many ALUs to do the task at once where on the other hand, if multiple different ALU operations are being performed at once, only that number of resources are used.
This is what AMD would like to do and BD was step 1.
The issues are:
No software supports it.
No compiler supports it.
No OS supports it.
Could it be fast: Absolutely.
Could is be feasible in the near future: I don't think so.
I think there will be a middle ground in between a CPU and GPU core when all is said and done, we just haven't got there yet and I think it will be some time before we do. I'm just saying what you're describing between a unique CPU and a unique GPU core isn't feasible with how CPUs with an iGPU work and even GCN doesn't overcome these issues.
The diea to make a GPU with X86/X64 compute has been realized, now it is just the memory addressing between two independent processors (CPU & GPU) that makes it hard to do, but with both on one die and one hardware controller that runs controlling dispatches for both......
Also once again, as I said, if it really was as easy as your describe it, someone who has been working on this for years with doctoral degrees in either Comp Sci or EE would figure it out before you and since it practically doesn't exist, I'm very certain that you're describing is purely theoretically without any real-world background to back up such claims.
We have the technology, we have the capability, it will be hard, and require a few spins to get right but even a 25% IPC improvement is well worth it.
So Hardware that is in the die between the RAM and L3 and can read and write to either, and also allows DMA for both CPU and GPU, while maintaining the TLB, reading the branching and decoding instructions and issuing them to the proper channel, and or even to the next available core, (Think hardware level multithreading of single threaded apps).......
Sounds complex until you realize that half the issues were dealt with when we moved away from PIO and to DMA.
The primary issue of data could be overcome by the controller issuing thread A to core 0 and assigning thread B to GPU subunit 1
Operation X waits on the results of both, the next instruction Y is fetched and core 1 is assigned the two corresponding memory addresses that will hold the result of thread A and Thread B, programmed to perform a multiply of the two results and save to a new memory address.
This clock cycle is over and now core 1 is able to perform the work while the hardware dispatcher marks all the locations dirty involved in the previous operation, starts issuing the next set of commands including wipe the previous locations used.
It would require the use of a X64 environment optimally, resulting in a bit of overallocation of cache, unless we knew that we wouldn't need or use any registers that large.
Anyway, the point is, we could do it, we are moving to it, and it is going to happen.
Also we have to note that AMD is developing a compiler for this, that's what the research wd heard about some university research getting performance must by software optimization or something, that turned out to be research for making a new compiler
AMD definitely was on the right path with High IPC, but with Bulldozer they decided to go all Netburst and start using lower IPC with substantially higher clocks. Worked well for Intel back then right?
they just decided to not only focus on ipc but also get more efficient execution, in theory a bulldozer module has 25% more compute capabilities than a phenom II core, but due to improper tuning and high latencies it takes a good 30-40% hit which puts its per core ipc behind phenom II, but if things were to work out perfect they would be years ahead, and im sure thats what amd thot aswell when they tested on simulated machines
there is no point for amd to go against intel in the "fat cores" with high IPC battle because if amd does so it will always be behind due to intel having more money which allows it to stay ahead in fabrication process, amd will have to take a more efficient architecture approach to get anywhere and thats where cores with shared resources came from(bulldozer was supposed to share the hardware that isnt always used by the core, and share it between 2 cores, and while integer cores would be crunching data in their cycle, the shared resources would be feeding the second core ) , and i think bulldozer was a good move in theory, just had very bad execution, what piledriver is turning out to be was supposed 2 be bulldozer. also there is nothing fundamentally wrong with bulldozer, they can add more decoders and fpu units to it and increase the modules ipc and with fine tuning sharing will have no affect to performance wat so ever, but it wasnt designed that way because bulldozer was meant to be for 45nm so adding more hardware would only make the modules too big
now if bulldozer was to compete with nehelem it would be seen as a much better cpu, but SB was the problem
remember bulldozer was years late to market