Tuesday, October 6th 2020
Crysis 3 Installed On and Run Directly from RTX 3090 24 GB GDDR6X VRAM
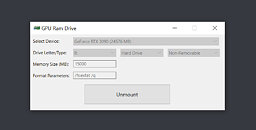
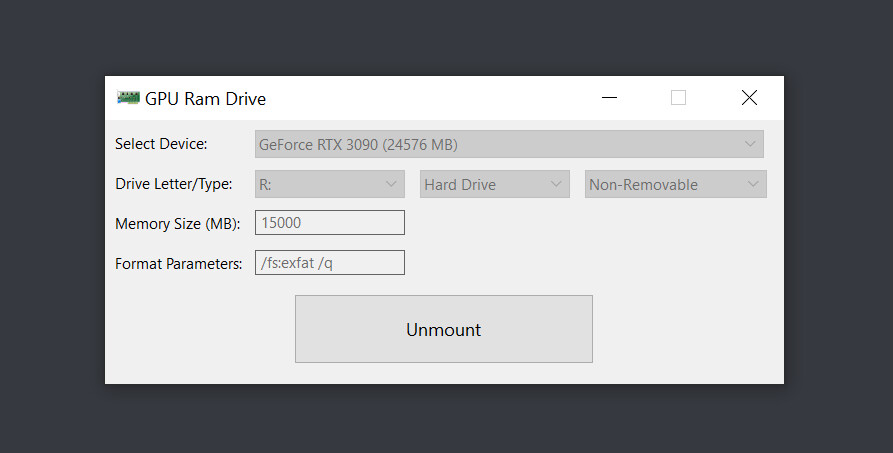
Let's skip ahead of any "Can it run Crysis" introductions for this news piece, and instead state it as it is: Crysis 3 can absolutely run when installed directly on a graphics card's memory subsystem. In this case, an RTX 3090 and its gargantuan 24 GB of GDDR6X memory where the playground for such an experiment. Using the "VRAM Drive" application, distributed in an open-source manner via the GitHub platform, one can allocate part of their GPU's VRAM and use it as if it was just another system drive. After doing so, user Strife212 (as per her Twitter handle) then went on to install Crysis 3 on 15 GB of the allocated VRAM. The rest of the card's 9 GB were then available to actually load in graphical assets for the game, and VRAM consumption (of both the installed game and its running assets) barely crossed the 20 GB total VRAM utilization.
As you might expect, graphics memory is one of the fastest memory subsystems on your PC, being even faster (in pure performance terms) than system RAM. Loading up of game levels and asset streaming from VRAM "disk-sequestered" pools to free VRAM pools was obviously much faster than usual, even more than the speeds achieved by today's NVMe drives. Crysis 3 in this configuration was shown to run by as many as 75 FPS in 4K resolution, with the High preset settings. A proof of concept more than anything - but users with a relatively powerful (or memory-capable) graphics card can perhaps look at this exotic solution as a compromise of sorts, should they not have any fast storage options, and provided the game install size is relatively small.
Sources:
Strife212 @ Twitter, via Tom's Hardware
As you might expect, graphics memory is one of the fastest memory subsystems on your PC, being even faster (in pure performance terms) than system RAM. Loading up of game levels and asset streaming from VRAM "disk-sequestered" pools to free VRAM pools was obviously much faster than usual, even more than the speeds achieved by today's NVMe drives. Crysis 3 in this configuration was shown to run by as many as 75 FPS in 4K resolution, with the High preset settings. A proof of concept more than anything - but users with a relatively powerful (or memory-capable) graphics card can perhaps look at this exotic solution as a compromise of sorts, should they not have any fast storage options, and provided the game install size is relatively small.


70 Comments on Crysis 3 Installed On and Run Directly from RTX 3090 24 GB GDDR6X VRAM
I get that it was done for giggles, by why do giggles require a news article? There's nothing new going on here.
Also, bandwidth tests by our own W1zzard show the PCIe bus is barely used, and if the transfer from Vmem to RAM is faster than from a SSD or NVMe while not hindering performance of the data between the CPU and GPU it's interesting when you consider the new DMA and what could happen if a CPU core was placed on the GPU. No more need for decompression and transfers. Which is kinda one of the new things Nvidia and AMD have been working on, instead of using the CPU to decompress data the GPU needs load compressed textures into Vmem and allow the GPU to handle decompression on the fly, and if they do it with fine enough resolution the GPU could direct fetch and decompress only the part of the texture needed.
I think it's cool, and it shows how much more the hardware we have is capable of, and how in a few years we may have a true "APU" of graphics cores intermixed with CPU cores sharing cache and a homogeneous pool of faster memory.
Read a couple of posts before you. Also try benchmarking it.
Maybe with DirectStorage and stuff like RTX IO it will be great, but surely not with GpuRamDrive in its current form. I wonder if that tool lets you assign more MB than VRAM available ...because quite possibly if it gets full you end up in RAM anyway and if it gets full you end up on NVMe/SSD/HDD or wherever your swap file is.
What I want to see is someone do something like this with one of those incoming 48GB/64GB Quadro cards. That would be fascinating!
This was just an old amateur concept that hasn't been updated in several years (for a good reason). The main issue is that it still uses RAM for data exchange, so basically it works like a conventional RAM disk that needs slightly less memory space, but uses GPU as temporary storage. Adding several more steps to read/write process only makes it drastically slower than RAM disk (to the point where GDDR5 is slower than NVME). Looked through that code and even though I haven't touched CUDA or even C++ in years, I can already see some issues.
I'm sure there are much better and efficient ways to make this work, but I still don't see any reasons to do so... Heck, NVME has already saturated PCIe 3.0 bandwidth, and PCIe 4.0 isn't even at the full swing yet. Regardless of how fast GDDR5/6/7... or HBM is on paper, it's only gonna be that fast from the perspective of the GPU. For the rest of the system it's gonna be only as fast as PCIe and a shitton of abstraction layers will allow it to be. Basically, what I'm trying to say is that you can't make it faster than NVME RAID, even less so - RAM disk. That's why AMD stuck their guns to hybrid solutions, like Radeon Pro SSG. At least for now this approach makes a bit more sense, when you actually need to have "storage" on GPU.
So, in summary:
Fun level of doing this if it's novel to you and you get excited by this kind of thing: High
Practical usefulness of doing this when you have a NVMe drive: Never
You two can argue how pointless or uninteresting it is till the cows come home. The rest of us will continue to find it interesting.
For this particular case it'll be exactly the same as if you had multi-GPU without any bridges(e.g. you can create individual vRAM disks, but can't combine them). The only way around it is to create a storage pool out of several vRAM disks(Windows Storage Spaces), but I'm not sure if it'll even work for these.
......at least, that is how SLI worked through through Turing..... did it change with Ampere? (gaming/SLI, not compute note)
Please, go look online to confirm. Here's a start. :)
www.build-gaming-computers.com/sli-performance-increase.html#:~:text=SLI%20Myth%20%236%3A%20SLI%20Doubles%20VRAM&text=So%20to%20set%20the%20record,or%20added%2C%20but%20instead%20copied.www.wepc.com/tips/what-is-sli/If you find something different, feel free to post it. But those links go on for days and back a decade. ;)
Edit: I vaguely recall dx12 supposedly being able to pool it, but... I cant find a thing thats concrete... people are saying the same thing but get shut down left and right.
EDIT2: From Nvidia (circa 2012, lol) - nvidia.custhelp.com/app/answers/detail/a_id/153/~/in-sli-mode%2C-is-memory-shared-%28i.e-do-both-2gb-cards-become-a-4gb
developer.download.nvidia.com/whitepapers/2011/SLI_Best_Practices_2011_Feb.pdf
www.nvidia.com/content/dam/en-zz/Solutions/design-visualization/technologies/turing-architecture/NVIDIA-Turing-Architecture-Whitepaper.pdf
In short, VRAM availability to applications and APIs will be equal to the amount on one card, but the cards themselves do and must use all VRAM available. If custom code is used SLI performance can optimized on a per-application basis which includes both symmetric and asymmetric VRAM usage, which means the standard limits and operational constraints can and are altered.
That being said, in the context of a VRAM drive, the VRAM of each card can be used independently or in series while the card still runs SLI functions simultaneously.