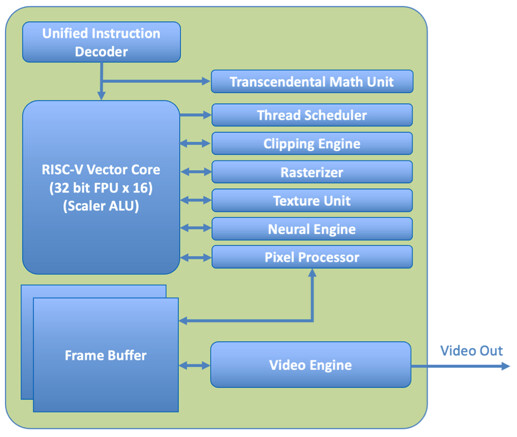
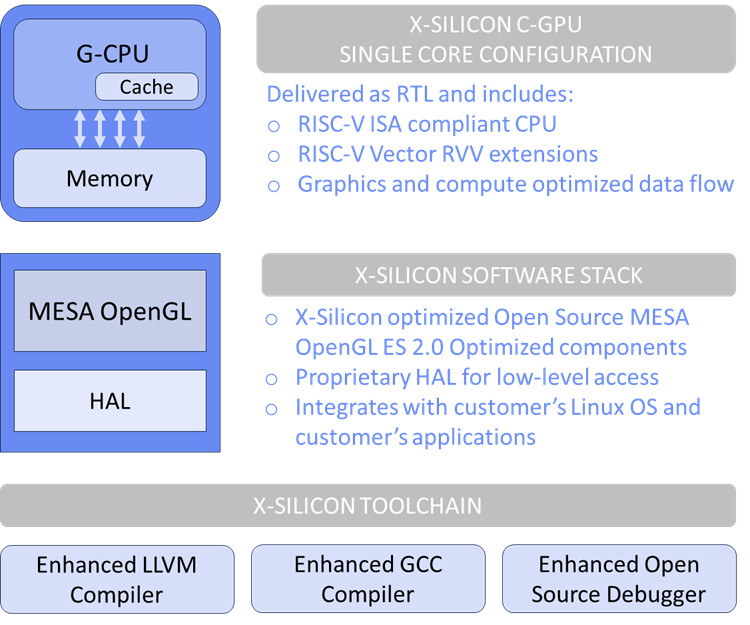
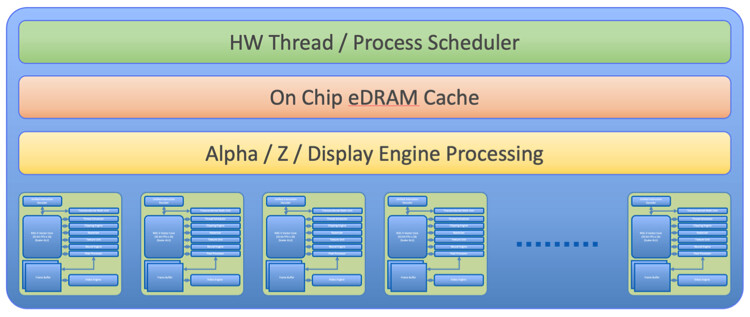
NVIDIA's NVLink Fusion Stays Proprietary, Third Parties Can Only Work Around It
To expand its growing influence in the data center market, NVIDIA recently launched the NVLink Fusion program. This initiative enables select partners to integrate their custom-designed chips into the NVIDIA system framework. For example, a partner can connect its custom CPU to an NVIDIA GPU using the 900 GB/s NVLink-C2C interface. However, this collaboration comes with significant restrictions. Any custom chip must be connected to an NVIDIA product, and the company maintains firm control over the critical software that manages these connections. This means partners cannot create truly independent, mix-and-match systems. NVIDIA retains control over the essential communication controller and PHY layers in the NVLink Fusion, which initializes and manages these links. It also mandates a license for third-party hardware to use its NVLink Switch chips.
In response, a growing coalition of tech giants, including AMD, Google, and Intel, is championing an open-standard alternative. Their UALink Consortium released its 1.0 specification in April 2025, defining a public standard for linking up to 1,024 accelerators from any vendor. While NVIDIA currently offers superior raw bandwidth, UALink represents a move toward greater flexibility and cost efficiency. According to reports, eight companies expressed interest in NVLink Fusion. However, the frustration of working with a communication link with limited visibility results in designs that are not always optimal and efficient. NVIDIA sets these standards from the beginning, so any company willing to work with NVLink Fusion is aware of these limitations from the outset. Cloud hyperscalers, such as AWS, GCP, and Azure, have expressed interest among the reported eight customers, so they might swallow this pill and continue working with NVIDIA to gain access to the IP despite the limited information available.


In response, a growing coalition of tech giants, including AMD, Google, and Intel, is championing an open-standard alternative. Their UALink Consortium released its 1.0 specification in April 2025, defining a public standard for linking up to 1,024 accelerators from any vendor. While NVIDIA currently offers superior raw bandwidth, UALink represents a move toward greater flexibility and cost efficiency. According to reports, eight companies expressed interest in NVLink Fusion. However, the frustration of working with a communication link with limited visibility results in designs that are not always optimal and efficient. NVIDIA sets these standards from the beginning, so any company willing to work with NVLink Fusion is aware of these limitations from the outset. Cloud hyperscalers, such as AWS, GCP, and Azure, have expressed interest among the reported eight customers, so they might swallow this pill and continue working with NVIDIA to gain access to the IP despite the limited information available.