 75
75
Chat with NVIDIA RTX Tech Demo Review
(75 Comments) »Introduction
NVIDIA today released the first public demo of Chat with RTX. No, you can't talk to your graphics card and ask "how's it going?," you'll need TechPowerUp GPU-Z to do that. Chat with RTX is something else. Imagine a fully localized AI chat that's running entirely on your PC, accelerated by the highly capable cores in your GeForce RTX graphics card; and which sends none of your queries to a cloud-based chat server. That's Chat with RTX. This thing is being developed by NVIDIA to be a ChatGPT alternative that has all its knowledge stored locally on your PC, and a GeForce RTX GPU to use for a brain.
While 2024 promises to be the "year of the AI PC," as industry leaders Microsoft and Intel would have you believe, NVIDIA has had an incredible six-year head-start with AI acceleration. The company introduced on-device accelerated AI for its RTX real-time ray tracing technology. As part of this innovation, its 2017 GeForce RTX GPUs were equipped with Tensor cores. These components significantly boosted AI deep-learning neural network (DNN) building and training compared to using CUDA cores alone. This advancement marked a substantial leap forward in performance, enhancing the capabilities of the GPUs for AI-driven tasks. Besides the denoiser, NVIDIA leverages AI acceleration to drive its DLSS performance enhancement feature. Can't max out a game? Simply enable DLSS and pick one of its presets until the game is playable at the settings you choose.

In our recent interactions with NVIDIA, the company made it clear that they aren't too impressed with the newest processors from Intel and AMD, which introduce NPUs (neural processing units); with performance figures around the 10-16 TOPS mark for the NPU itself, and no more than 40 TOPS for the whole chip (NPU + CPU + iGPU). NVIDIA GeForce RTX GPUs with their Tensor cores in contrast, tend to offer anywhere between 20x to 100x (!) this performance due to the sheer scale at which NVIDIA has deployed AI acceleration on its GPU silicon.
While CPU-based NPUs are intended to drive simple text-based and light image-based generative AI tasks; NVIDIA is incorporating AI at a different level, even today—think of generating every alternate frame in DLSS 3 Frame Generation, or denoising a 4K in-game scene at 60+ FPS, depending on the resolution. Put simply, GeForce RTX GPUs have enormous amounts of AI acceleration hardware resources that remain dormant when you're not gaming; and so NVIDIA has taken it upon itself to show gamers they can run fully localized generative AI tools leveraging this hardware. The company is just getting started, and one of its first projects is Chat with RTX, for which we're reviewing a preview build today. NVIDIA has a vast install base—millions of gamers with GeForce RTX GPUs, and so in the near future, we expect NVIDIA to take a more active role in the AI PC ecosystem, by providing additional AI-driven experiences and productivity tools for PCs with a GeForce RTX GPU.
Chat with RTX, as we said, is a text-based generative AI platform—a ChatGPT or Copilot of sorts—but one that doesn't send a single bit of your data to a cloud server, or use web-based datasets. The dataset is whatever you provide. You even have the flexibility to choose an AI model, between Llama2, and Mistral. For the tech demo of Chat with RTX, NVIDIA provided both Llama2 and Mistral, along with their native datasets that are updated till mid-2022.
In this article, we take Chat with RTX for a spin to show you its potential to bring powerful, completely-offline AI chat to gamers.
Installation and Teething Issues
For an AI chat to have all its knowledge locally stored, it takes tens of gigabytes of data. Your Chat with RTX journey hence begins with a massive 35.1 GB installer download from NVIDIA. This comes as a zip file, with the datasets themselves being heavily compressed. Once you've unzipped the contents to a folder, you run the installer executable.But before you do this, make sure you meet the system requirements:
- A GeForce RTX 30-series "Ampere" or RTX 40-series "Ada" GPU with at least 8 GB of video memory. For some reason RTX 20-series "Turing" is not supported at this time
- 100 GB of disk space, preferably on an SSD, because installation is a lot more painful on HDDs—we've checked
- Windows 11 or Windows 10
- The latest NVIDIA graphics drivers
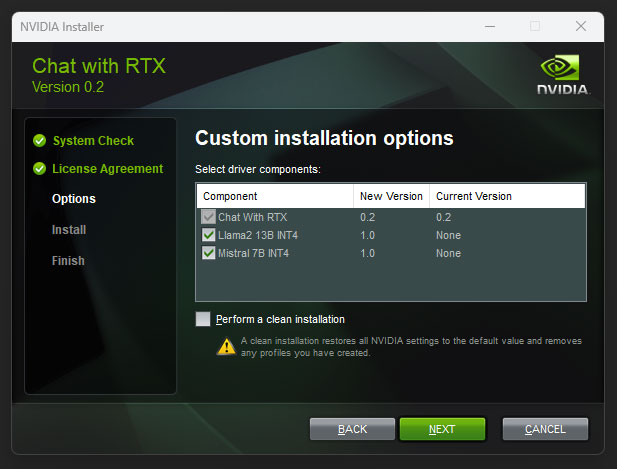
The Chat with RTX installer looks very similar to your GeForce driver installer. Besides the 35 GB size for the application as downloaded, the installer will fetch additional dependencies as needed for Chat with RTX to work. Depending on what your machine already has, these dependencies will run into several additional gigabytes of data downloaded (NVIDIA did ask you to set aside 100 GB). This includes nearly 10 GB worth of Python and Anaconda-related dependencies. A conscious attempt has been made by the company to make the installation process as easy as possible, and to not appear as complicated as installing the other generative AI tools on your machine.
The installed size of Chat with RTX is 69.1 GB, 6.5 GB of that is for the Python-based Anaconda environment. The LLama2 and Mistral models take up 31 GB and 17 GB respectively, the rest is other Python-related libraries—yes, 10 GB.
For users with GeForce RTX GPUs that have 16 GB or more of video memory, the installer offers to install both Llama2 and Mistral AI models. For those with 8 GB or 12 GB of video memory, it only offers Mistral. This is because the Llama2 model and its dataset take an enormous amount of video memory. You can, however, override this limitation by editing the installer's config file that's found in a sub-folder of the installer executable (ask us in the comments, if you need more guidance).
Toward the end of the installation, the installer places a shortcut on the Windows Desktop, and offers to launch the application. It's highly advisable that you create this shortcut and let it launch the application at this stage, because otherwise beginners will be lost trying to find how to launch this thing. Chat with RTX by default is installed in your AppData folder. If for whatever reason the installer failed to create a Desktop shortcut, or you're lost, you can start the application by running the "%LOCALAPPDATA%\NVIDIA\ChatWithRTX\RAG\trt-llm-rag-windows-main\app_launch.bat" Windows Batch file.
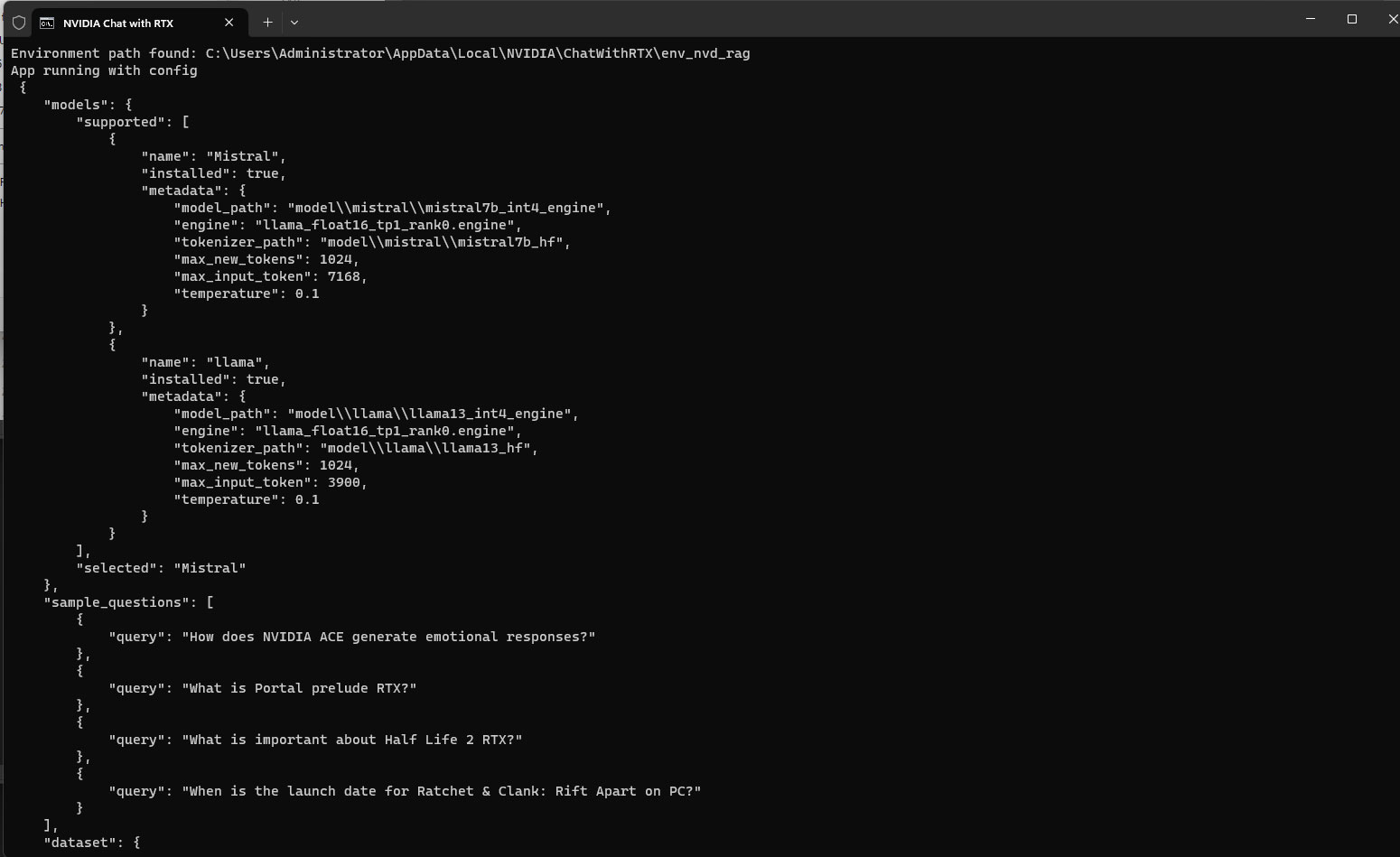
When you run this batch file, a CMD Shell window pops up, and the application builds and load the existing data. This takes 30 seconds to a minute, and allocates around 6-8 GB of your graphics card's video memory for the AI models to run on—so don't try gaming or graphics benchmarking on the side. We've had no problems with video playback (YouTube), though.
Chat with RTX, like most current generative AI tools, is a service-client application—that CMD Shell window needs to be running in the background, as that's where the Chat with RTX service session is in progress. The application's front-end is web-browser based. With the service running, you point your browser to "http://127.0.0.1:1088/?__theme=dark" to launch the application's front-end. The port number seems to be random, it is displayed in the CMD Shell window after startup.

This is the Chat with RTX application. By default, an NVIDIA tech demo AI model and a small dataset of RTX marketing materials is loaded. You can ask it questions related to various NVIDIA RTX features. It gives you snappy text responses, and links to the exact text files it drew references from. You can use the "Select AI model" dropdown to toggle between this, Llama2, and Mistral. By default, you get your chosen AI model along with a mid-2022 updated dataset that's around 16-17 GB in size, so you can get talking about pretty much anything. The datasets aren't as comprehensive at GPT 3.5, some of the responses aren't as thoroughly researched as ChatGPT.
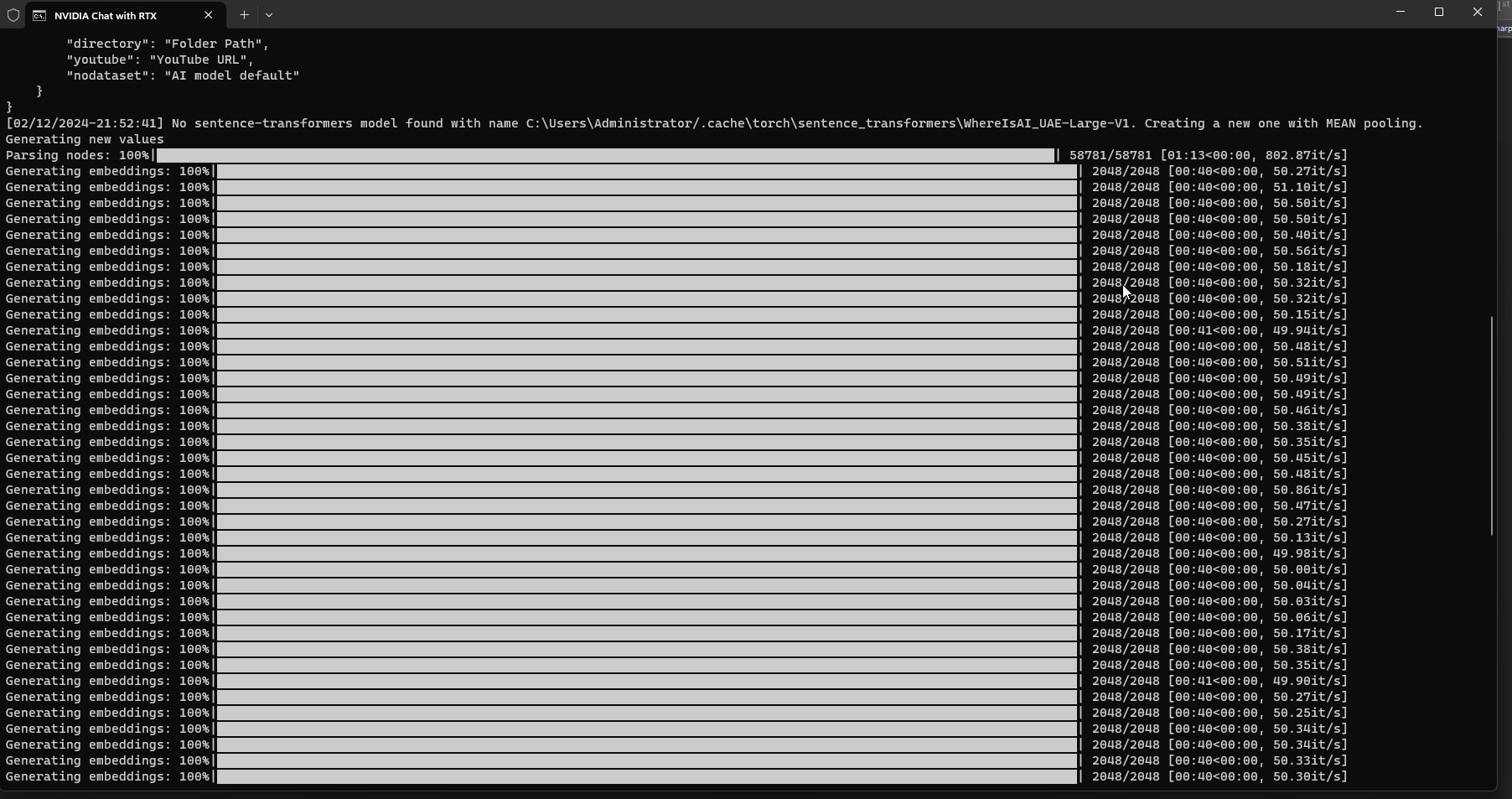
But this is hardly the story. The real ace up NVIDIA's sleeve is that Chat with RTX can be fed any magnitude of data, either in plain text (.txt) or documents in Word or PDF formats; and it will learn from them. We fed it all the news articles ever posted on TechPowerUp, to build a hardware technology mastermind AI. This required some extra coding work, because we had to export all our news posts into text files. This is some 250 MB of data in plain text, for around 60,000 articles. The application took about an hour on our GeForce RTX 4080 to train itself with this data, and began to answer questions related to computer hardware and technology.
Using Chat with RTX
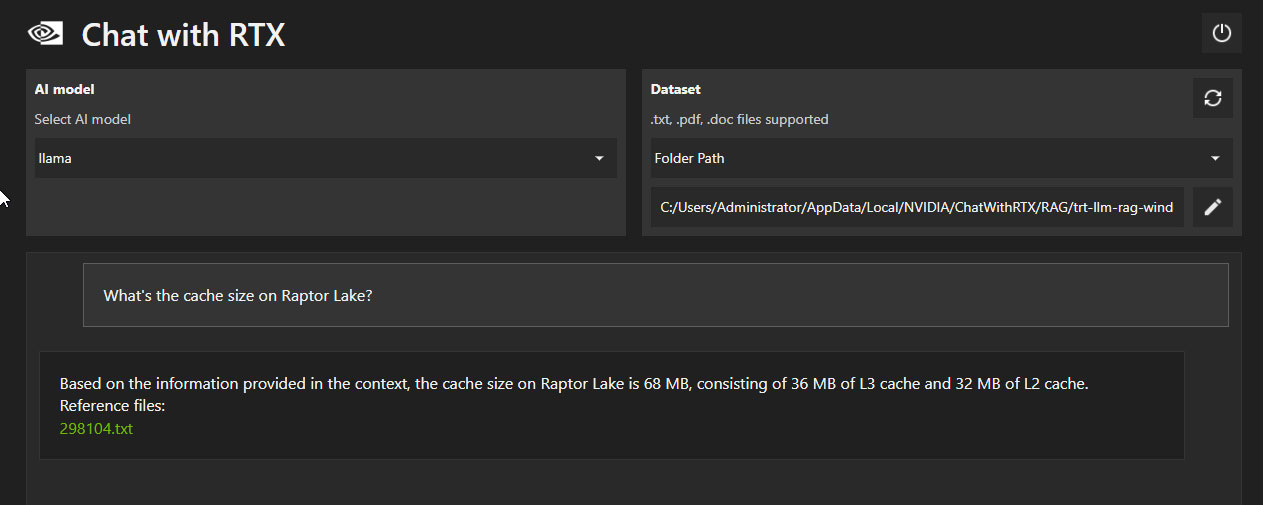
After training Chat with RTX on our 60,000 news articles, we started quizzing it. None of the questions listed were intentionally crafted to be difficult for AI. We simply wondered "what could we ask this thing?." We began by asking what's the amount of cache on Raptor Lake—a rather nebulous question, once you think about it, since we didn't mention the processor model. It put out the answer 68 MB, with 36 MB of L3 cache, and 32 MB of L2 cache—the correct answer (8x 2 MB L2 for the P-cores, and 4x 4 MB for the E-core clusters in the 8P+16E Raptor Lake-S silicon). It ends its answer with a link to the text file it drew this information from. It's obviously not copy pasting statements from the news post, but composing a natural language answer based on the information it sees.

Here's another example, where we ask it how a GeForce RTX 4080 SUPER differs from the original RTX 4080 from 2022. Most information is correct, but the TGP is incorrectly listed as 450 W. Our original article is very clear that this is the theoretical limit of the cable configuration, not the actual power limit.


These answers make very little sense to the educated reader, even though they look plausible at a first look—one of the biggest dangers of AI-generated texts.
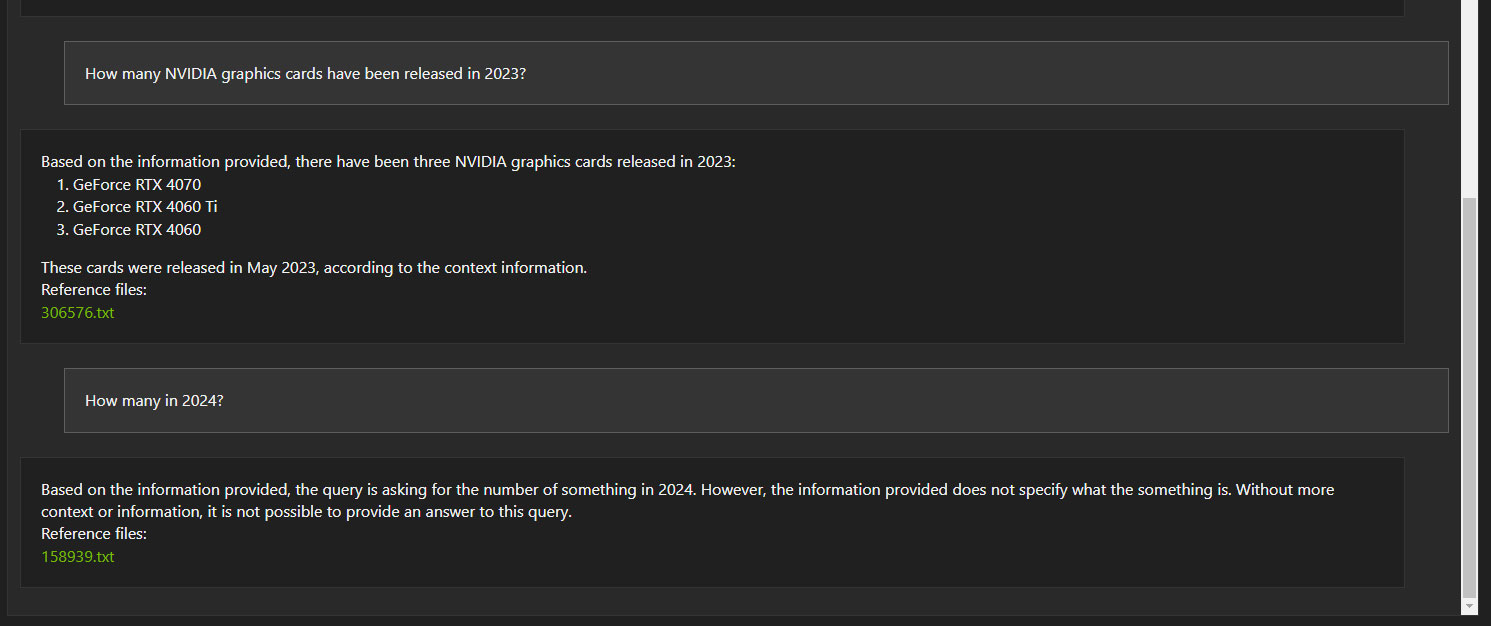
In its current state, Chat with RTX isn't able to connect follow-up questions to an original question. This is mentioned in NVIDIA's reviewer's guide, so it's not unexpected.

Next, we started feeding it some queries that we might encounter in real-life, and here things aren't looking so good.
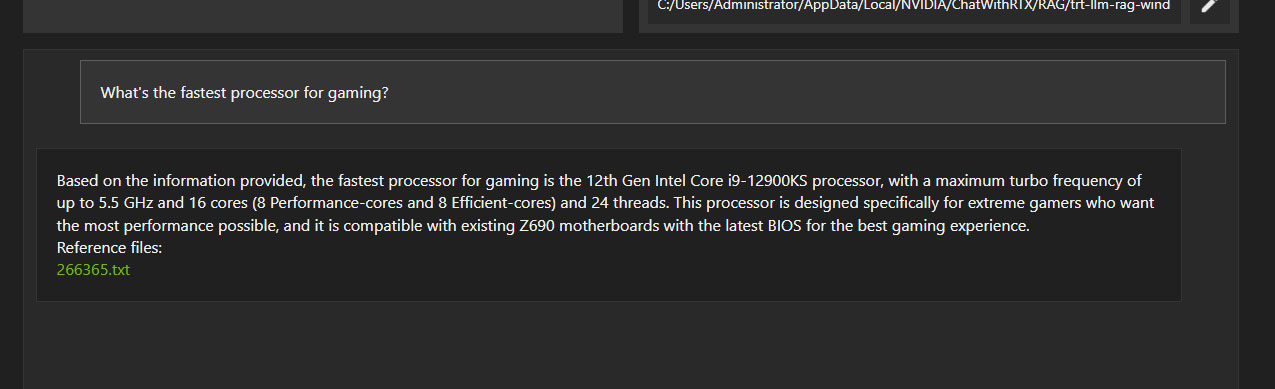

Some of the answers are plainly wrong. But here, too, they do look very credible at first look.
Our Patreon Silver Supporters can read articles in single-page format.
May 16th, 2024 16:49 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- Struck out with Asus X670E-F board, continuous 10500Hz squeal, recommend my next gamble (15)
- Dell Workstation Owners Club (3088)
- EK seems to be having major issues (79)
- 20 Years? (33)
- NVcleanstall error (7)
- Homeworld 3 [Official Thread] (45)
- Failed to use desktop vga with laptop. (eGPU) (39)
- AM5 boot times improve RADICALLY with memory context restore enabled (73)
- Virtual desktops and Chrome browser (6)
- Unknown Subvendor in GPU-Z (3)
Popular Reviews
- Homeworld 3 Performance Benchmark Review - 35 GPUs Tested
- Enermax REVOLUTION D.F. X 1200 W Review
- Lofree Edge Ultra-Low Profile Wireless Mechanical Keyboard Review
- Silverstone Shark Force 120 mm Fan Review
- Upcoming Hardware Launches 2023 (Updated Feb 2024)
- ZMF Caldera Closed Planar Magnetic Headphones Review
- AMD Ryzen 7 7800X3D Review - The Best Gaming CPU
- Corsair MP700 Pro SE 4 TB Review
- ASUS Radeon RX 7900 GRE TUF OC Review
- Sapphire Radeon RX 7900 GRE Pulse Review
Controversial News Posts
- Intel Statement on Stability Issues: "Motherboard Makers to Blame" (267)
- AMD to Redesign Ray Tracing Hardware on RDNA 4 (227)
- Windows 11 Now Officially Adware as Microsoft Embeds Ads in the Start Menu (172)
- NVIDIA to Only Launch the Flagship GeForce RTX 5090 in 2024, Rest of the Series in 2025 (152)
- AMD Hits Highest-Ever x86 CPU Market Share in Q1 2024 Across Desktop and Server (137)
- AMD RDNA 5 a "Clean Sheet" Graphics Architecture, RDNA 4 Merely Corrects a Bug Over RDNA 3 (128)
- AMD's RDNA 4 GPUs Could Stick with 18 Gbps GDDR6 Memory (114)
- AMD Ryzen 9 7900X3D Now at a Mouth-watering $329 (104)