 344
344
NVIDIA GeForce GTX 680 Kepler 2 GB Review
Packaging & Contents »Architecture


At the heart of the GeForce GTX 680, is the GeForce Kepler architecture. Its design goals are to raise performance and energy-efficiency over the previous generation "Fermi" architecture. GeForce Kepler's architecture more or less maintains the basic component-hierarchy of GeForce Fermi, which emphasizes on a fast, highly parallelized component load-out. Think of the hierarchy as a Bento container. At the topmost level is the PCI-Express Gen. 3.0 host interface, a 256-bit wide GDDR5 memory interface, and a highly-tweaked NVIDIA GigaThread Engine, which transacts processed and unprocessed data between the host and memory interfaces.



At the downstream of the GigaThread Engine are four Graphics Processing Clusters (GPCs). Each GPC is a self-contained GPU subunit, since it has nearly every component an independent GPU does. The GPC has one shared resource, and two dedicated resources, the shared resource is the Raster Engine, which handles high-level raster operations such as edge setup, and Z-cull. The dedicated resources are the next-generation Streaming Multiprocessor-X (SMX). A large chunk of architectural improvements have gone into perfecting this component. The Streaming Multiprocessor-X (SMX) is the GPU's number-crunching resource. It is highly-parallelized, to handing the kind of computing loads that tomorrow's 3D applications demand.

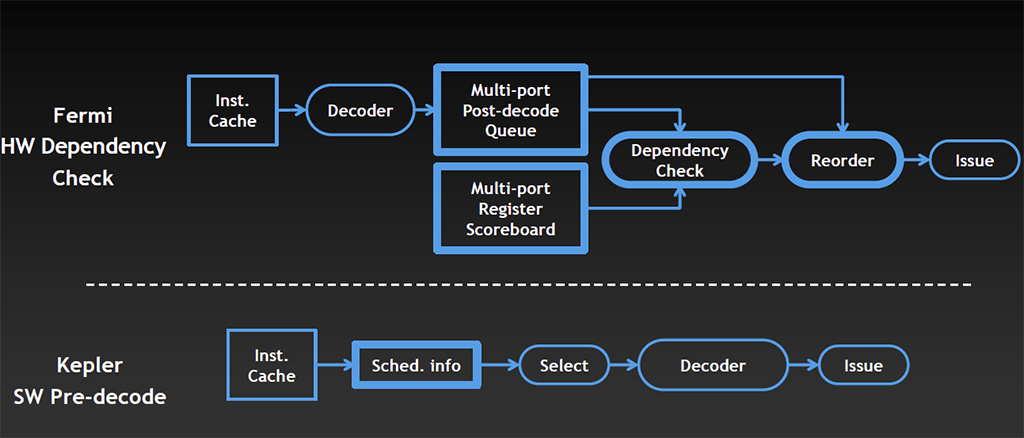
The SMX further has shared and dedicated resources. The next-generation PolyMorph 2.0 Engine handles the low-level raster operations, such as vertex-fetch, tessellation, viewpoint-transformation, attribute setup, etc. The dedicated components are where the number-crunching action happens. Four Warp Schedulers marshal instructions and data between 192 CUDA cores. This is a six-fold increase over that of the GF110, and four-fold over that of the GF114. There are 16 texture memory units per SMX, which are cached. The Warp Schedulers are backed by a more efficient software pre-decode algorithm that reduces the number of steps needed to issue instructions. Essentially at shader compile time the shader compiler, which is a component of NVIDIA's driver, will evaluate the instruction stream, reorder instructions as needed and provide extra info to hardware by attaching additional info to instructions. It can do so because it has a complete view of the shader code.


NVIDIA also innovated what it calls Bindless Textures. In the classical GPU model, to reference a texture, the GPU has to allocate it a slot in a fixed size binding table, which limits the number of textures a shader can access at a given time, which ended up being 128, with the previous-generation Fermi architecture. The Kepler architecture removes this binding step, a shader can reference textures directly in the memory, without needing a conventional binding table. So the number of textures a shader can reference is practically unlimited, or 1 million if you want to talk in figures. This makes rendering scenes that are as complex as the photo above, a breeze, because it can be done so with fewer passes.
To sum it all up, the GeForce Kepler 104 GPU has 192 CUDA cores per SMX, 384 per GPC, and 1536 in all. It has 128 Texture Memory Units (TMUs) in all (16 per SMX, 32 per GPC); and 32 Raster Operations Processors (ROPs) in all. At several levels, transactions between the various components are cached, to prevent wastage of clock cycles (in turn, translating to energy efficiency).


NVIDIA also introduced a new anti-aliasing (AA) algorithm called TXAA. There have already been a few new AA algorithms introduced in recent past, such as FXAA, SMAA and SRAA, which raised the bar with quality, with lower performance-impact. TXAA seeks to raise it even further, with image quality comparable to high levels MSAA, with the performance penalty of 4x MSAA. TXAA is a hybrid between hardware multi-sampling, temporal AA, and a customized AA resolve. It has two levels: TXAA1 and TXAA2. The former offers image quality comparable to 8x MSAA, with the performance-penalty of 2x MSAA; the latter offers image quality beyond 8x MSAA, with the performance-penalty comparable to 4x MSAA. Since lower MSAA levels are practically "free" with today's GPUs, TXAA will wipe the floor with the competition, in terms of image quality, but there's a catch. Applications have to be customized to take advantage of TXAA. This is where NVIDIA's developer-relations muscle should kick in. We expect a fairly decent proliferation of TXAA among upcoming games.
NVIDIA has also added an FXAA option to the driver control panel, which enables it in all games without the need for any integration from game developers.


The last of the three big features is Adaptive V-Sync. The feature improves on traditional V-Sync, by dynamically adjusting the frame limiter to ensure smoother gameplay. Traditional V-Sync merely sends frame data to the screen after every full screen refresh. This means if a frame arrives slow, because the GPU took longer to render it, it will have to wait a full screen refresh before it can be displayed, effectively reducing frame rate to 30 FPS. If rendering a frame takes longer than two full refreshes, the frame rate will even drop down to 20 FPS. These framerate differences are very noticeable during gaming because they are so huge.
What Adaptive V-Sync does is, it makes the transition between frame-rate drop and synchronized frame-rate smooth, alleviating lag. It achieves this by dynamically adjusting the value that V-Sync takes into account when limiting frame-rates. I did some testing of this feature and found it to work as advertised. Of course this does not completely eliminate frame rate differences, but it makes them less noticeable.
Jun 30th, 2025 18:39 CDT
change timezone
Latest GPU Drivers
New Forum Posts
- Will you buy a RTX 5090? (581)
- The TPU UK Clubhouse (26529)
- Do you use Linux? (663)
- Can you guess Which game it is? (194)
- Help me choose the right PSU , Cooler Master vs Seasonic (53)
- HOW TO ADD NVMe M.2 SSD SUPPORT TO OLD MOTHERBOARDS WITH AWARD-Phoenix LEGACY SUPPORT? (2)
- Whats a fair asking price - MSI 4070 Super (4)
- HTPC Power Consumption Discussion, Upgrade vs Migration (18)
- RX 9000 series GPU Owners Club (1103)
- Rare GPUs / Unreleased GPUs (2111)
Popular Reviews
- Sapphire Radeon RX 9070 XT Nitro+ Review - Beating NVIDIA
- ASUS ROG Crosshair X870E Extreme Review
- Sapphire Radeon RX 9060 XT Pulse OC 16 GB Review - Samsung Memory Tested
- Lexar NQ780 4 TB Review
- AVerMedia CamStream 4K Review
- ASRock Phantom Gaming Z890 Riptide Wi-Fi Review
- AMD Ryzen 7 9800X3D Review - The Best Gaming Processor
- Upcoming Hardware Launches 2025 (Updated May 2025)
- NVIDIA GeForce RTX 5060 8 GB Review
- Intel Core Ultra 7 265K Review
TPU on YouTube
Controversial News Posts
- Intel's Core Ultra 7 265K and 265KF CPUs Dip Below $250 (288)
- NVIDIA Grabs Market Share, AMD Loses Ground, and Intel Disappears in Latest dGPU Update (204)
- Some Intel Nova Lake CPUs Rumored to Challenge AMD's 3D V-Cache in Desktop Gaming (140)
- Microsoft Partners with AMD for Next-gen Xbox Hardware (105)
- NVIDIA Launches GeForce RTX 5050 for Desktops and Laptops, Starts at $249 (104)
- Intel "Nova Lake‑S" Series: Seven SKUs, Up to 52 Cores and 150 W TDP (100)
- NVIDIA GeForce RTX 5080 SUPER Could Feature 24 GB Memory, Increased Power Limits (90)
- Reviewers Bemused by Restrictive Sampling of RX 9060 XT 8 GB Cards (88)