cdawall
where the hell are my stars
- Joined
- Jul 23, 2006
- Messages
- 27,683 (3.99/day)
- Location
- Houston
| System Name | Moving into the mobile space |
|---|---|
| Processor | 7940HS |
| Motherboard | HP trash |
| Cooling | HP trash |
| Memory | 2x8GB |
| Video Card(s) | 4070 mobile |
| Storage | 512GB+2TB NVME |
| Display(s) | some 165hz thing that isn't as nice as it sounded |
Considering IBM produces chips that are nearly identical to Bulldozer with four integer clusters and they don't call that a quad-core, I'd say AMD is definitively wrong.
Not to nit pick, but isn't this the exact opposite of what you said earlier? I though AMD was the only CPU to ever attempt this...
They are wide cores. This lawsuit will likely force AMD to call them cores too.
Doubtful. AMD can create words to describe things just as well as the next guy. If AMD can't call what they consider a module a module, I guess Intel will have to ditch HyperThreading in favor for SMT. That is literally what you are saying needs to happen.
It would still be a 4-threaded core. A lot of enterprise RISC processors already handle 8-threads per core (many FPUs and ALUs in each) so that isn't exactly new.
Difference is those only have ONE integer and ONE FPU, not TWO and ONE.
Go ahead and run your benchmarks then. I'm waiting. Here's the post, by the way. Spoiler: it will never reach 95%+ that an actual dual core would.
I was very specific with the workloads that would show near 100% scaling, I would wager you cannot prove me wrong, but after reading your argument you find one useless benchmark (not real world scenario) that only uses the FPU for calculations and claim I am incorrect. As has been said a multitude of times the FPU isn't used for the majority of calculations. The real issue behind AMD isn't the configuration of the modules it is the shit design of the internal cores themselves. The module works excellent and if they were stronger cores the pure idea of this lawsuit wouldn't even exist. That my friend is actually the basic design of Zen mind you.
Last edited:



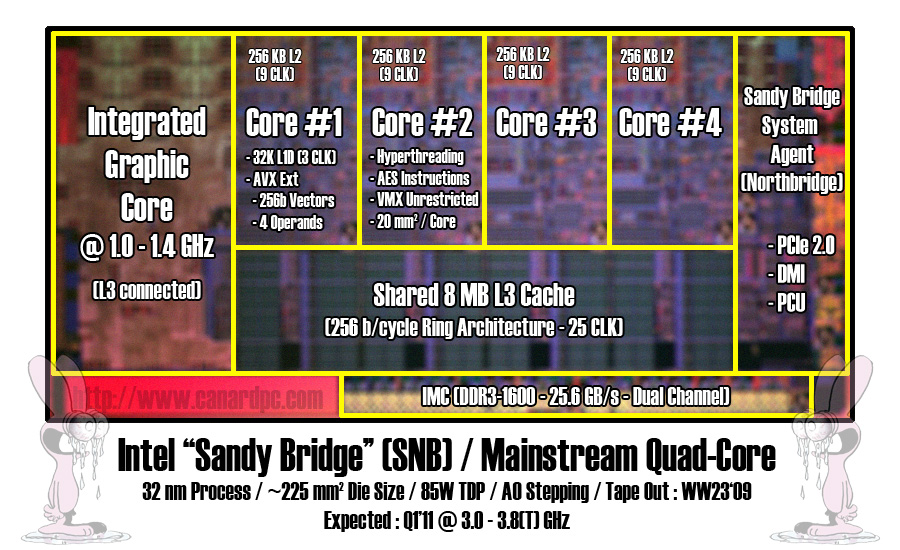
 because rocks have no inner workings but hey, they are silicon and also monolithic albeit not by design).
because rocks have no inner workings but hey, they are silicon and also monolithic albeit not by design).