That is a claim presented at the beginning of the article. Through the end, if you read it, it is proven in benchmark that it is
not true (number of queues horizontally and time spent computing vertically - lower is better)
View attachment 67772
Maxwell is faster than GCN up to 32 queues, and it evens out with GCN to 128 queues, where GCN has same speed up to 128 queues.
It's also shown that with async shaders it's extremely important how they are compiled for each architecture.
Good find
@RejZoR



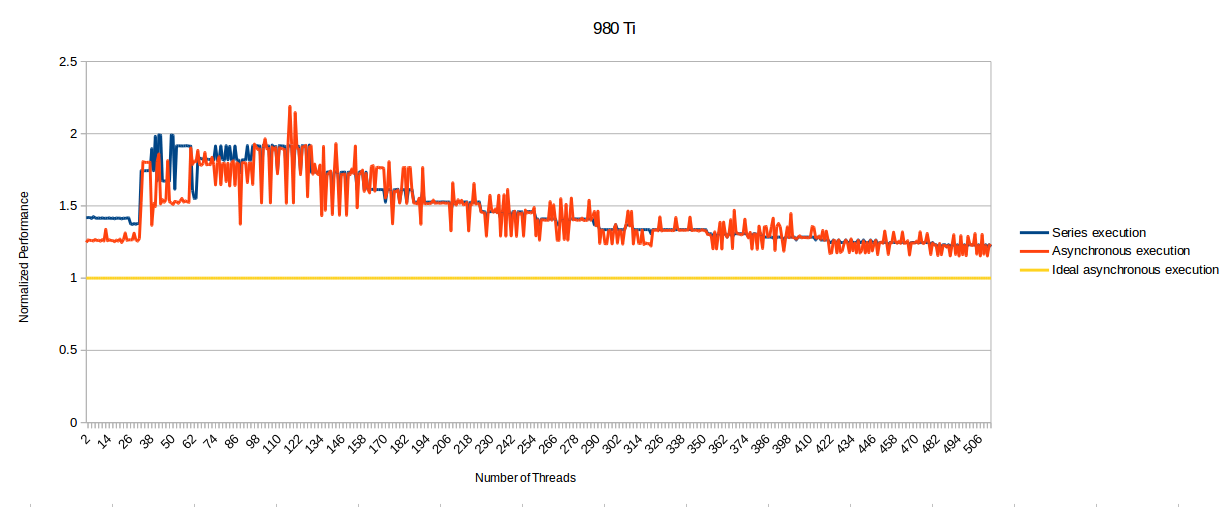
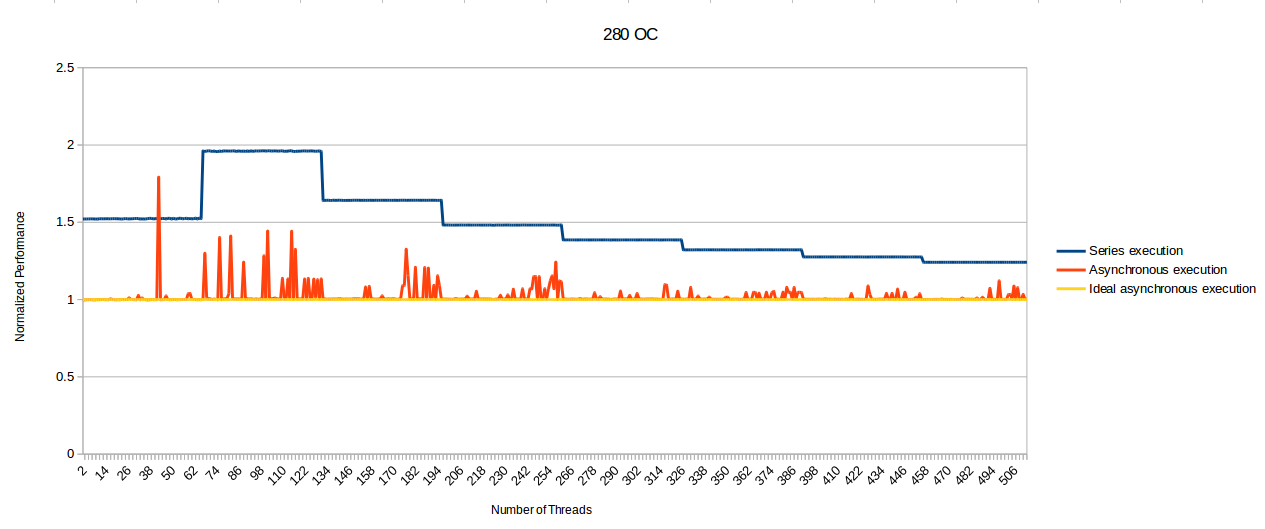

 Especially the bold bit. With idiotic statements like that, no wonder you're getting criticized by everyone.
Especially the bold bit. With idiotic statements like that, no wonder you're getting criticized by everyone.
")


