- Joined
- Jan 29, 2012
- Messages
- 6,881 (1.40/day)
- Location
- Florida
| System Name | natr0n-PC |
|---|---|
| Processor | Ryzen 5950x-5600x | 9600k |
| Motherboard | B450 AORUS M | Z390 UD |
| Cooling | EK AIO 360 - 6 fan action | AIO |
| Memory | Patriot - Viper Steel DDR4 (B-Die)(4x8GB) | Samsung DDR4 (4x8GB) |
| Video Card(s) | EVGA 3070ti FTW |
| Storage | Various |
| Display(s) | Pixio PX279 Prime |
| Case | Thermaltake Level 20 VT | Black bench |
| Audio Device(s) | LOXJIE D10 + Kinter Amp + 6 Bookshelf Speakers Sony+JVC+Sony |
| Power Supply | Super Flower Leadex III ARGB 80+ Gold 650W | EVGA 700 Gold |
| Software | XP/7/8.1/10 |
| Benchmark Scores | http://valid.x86.fr/79kuh6 |
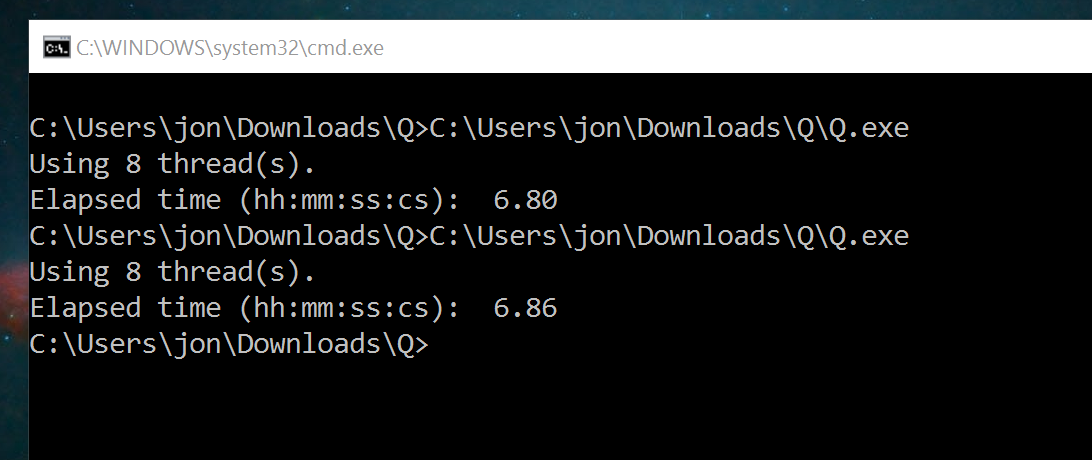
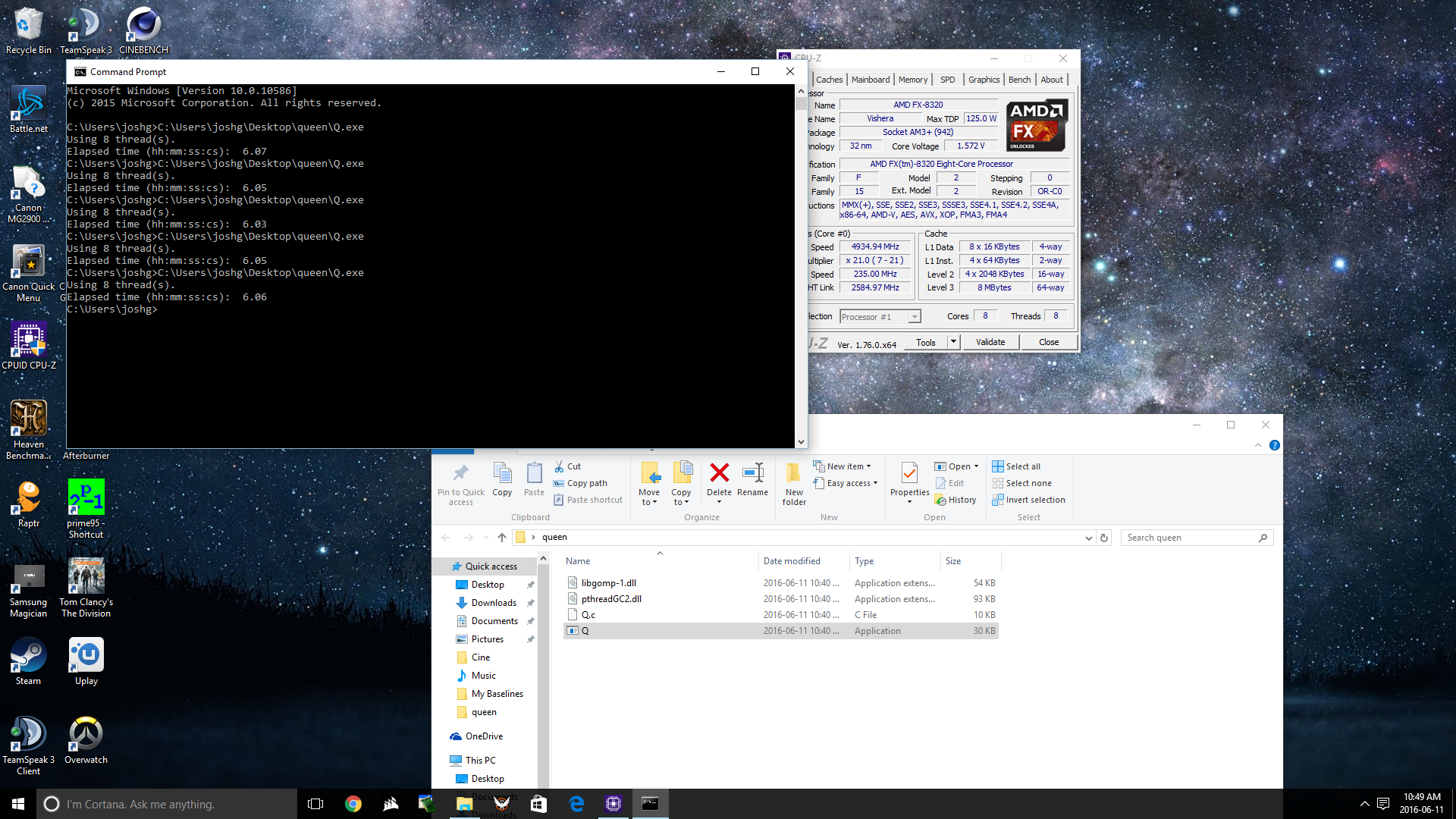
Program foes not work for me? Says its testing 12 threads then the window clothes after a few seconds. ;*(
open command prompt as admin then drag and drop q.exe then hit enter