TheLostSwede
News Editor
- Joined
- Nov 11, 2004
- Messages
- 18,900 (2.50/day)
- Location
- Sweden
| System Name | Overlord Mk MLI |
|---|---|
| Processor | AMD Ryzen 7 7800X3D |
| Motherboard | Gigabyte X670E Aorus Master |
| Cooling | Noctua NH-D15 SE with offsets |
| Memory | 32GB Team T-Create Expert DDR5 6000 MHz @ CL30-34-34-68 |
| Video Card(s) | Gainward GeForce RTX 4080 Phantom GS |
| Storage | 1TB Solidigm P44 Pro, 2 TB Corsair MP600 Pro, 2TB Kingston KC3000 |
| Display(s) | Acer XV272K LVbmiipruzx 4K@160Hz |
| Case | Fractal Design Torrent Compact |
| Audio Device(s) | Corsair Virtuoso SE |
| Power Supply | be quiet! Pure Power 12 M 850 W |
| Mouse | Logitech G502 Lightspeed |
| Keyboard | Corsair K70 Max |
| Software | Windows 10 Pro |
| Benchmark Scores | https://valid.x86.fr/yfsd9w |
This is an interesting observation that I had missed until now.
It would appear AMD has "cheaped out" on their memory controller a bit and it only has "half the performance" on CPUs with only one CCD in them, during write operations.
Seemingly it has little affect in most applications, but if you're doing something that does a lot of intensive memory writes, you might want to consider getting a dual CCD CPU.
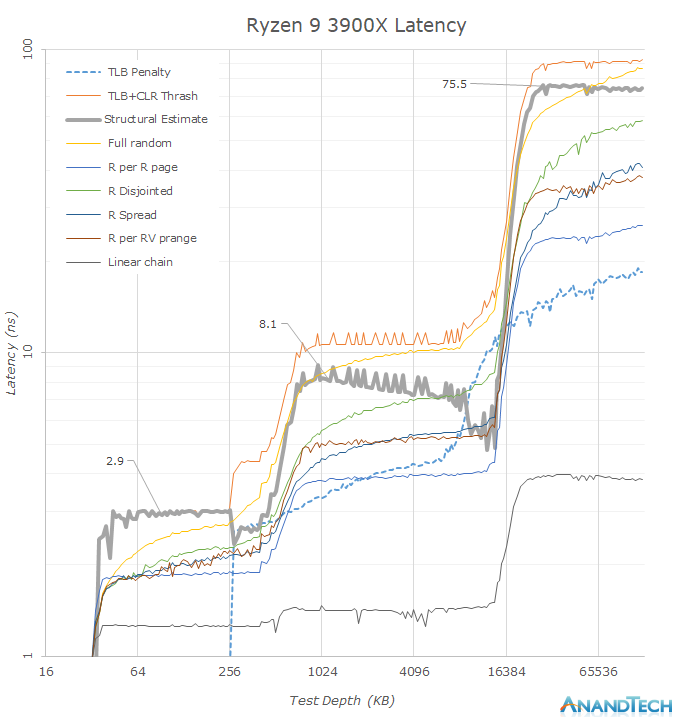
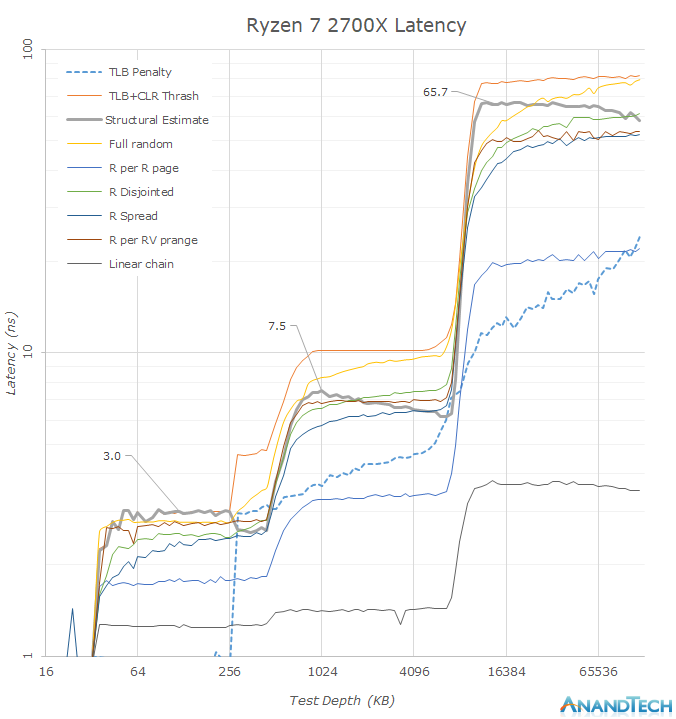
It does seem to have a small affect on the memory latency though.
Just a heads up, as it was not something that was particularly clear from AMD's side.

Source: https://www.guru3d.com/articles_pages/amd_ryzen_7_3700x_ryzen_9_3900x_review,21.html
It would appear AMD has "cheaped out" on their memory controller a bit and it only has "half the performance" on CPUs with only one CCD in them, during write operations.
Seemingly it has little affect in most applications, but if you're doing something that does a lot of intensive memory writes, you might want to consider getting a dual CCD CPU.
It does seem to have a small affect on the memory latency though.
Just a heads up, as it was not something that was particularly clear from AMD's side.
Source: https://www.guru3d.com/articles_pages/amd_ryzen_7_3700x_ryzen_9_3900x_review,21.html
Last edited: