Demand for NVIDIA's Blackwell Platform Expected to Boost TSMC's CoWoS Total Capacity by Over 150% in 2024
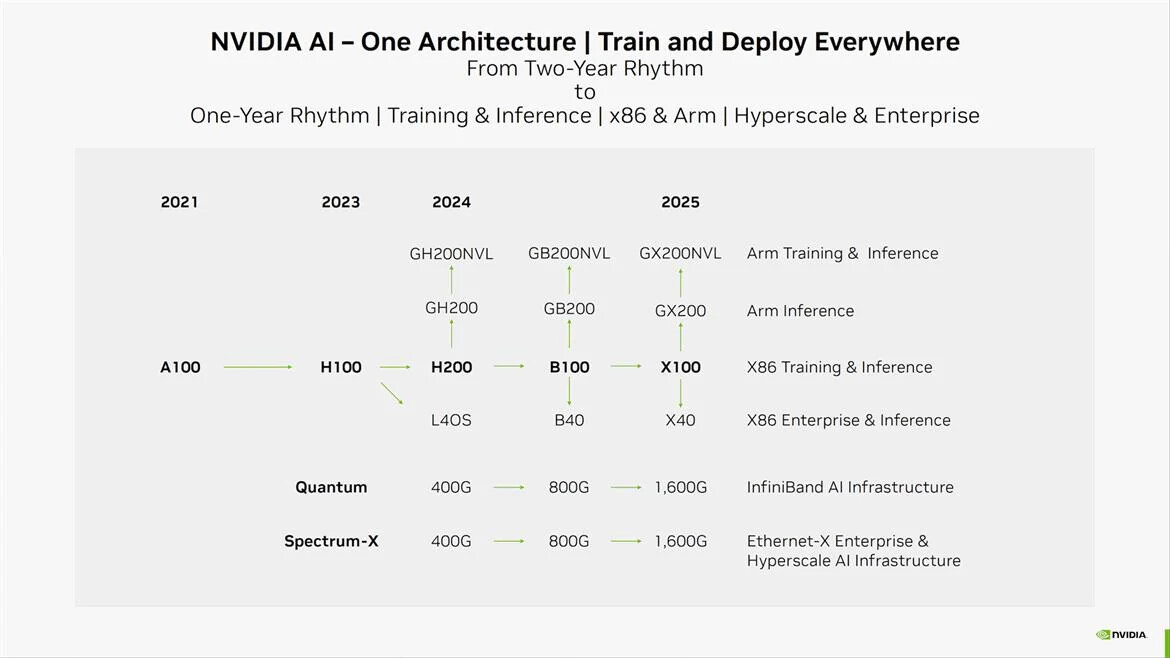
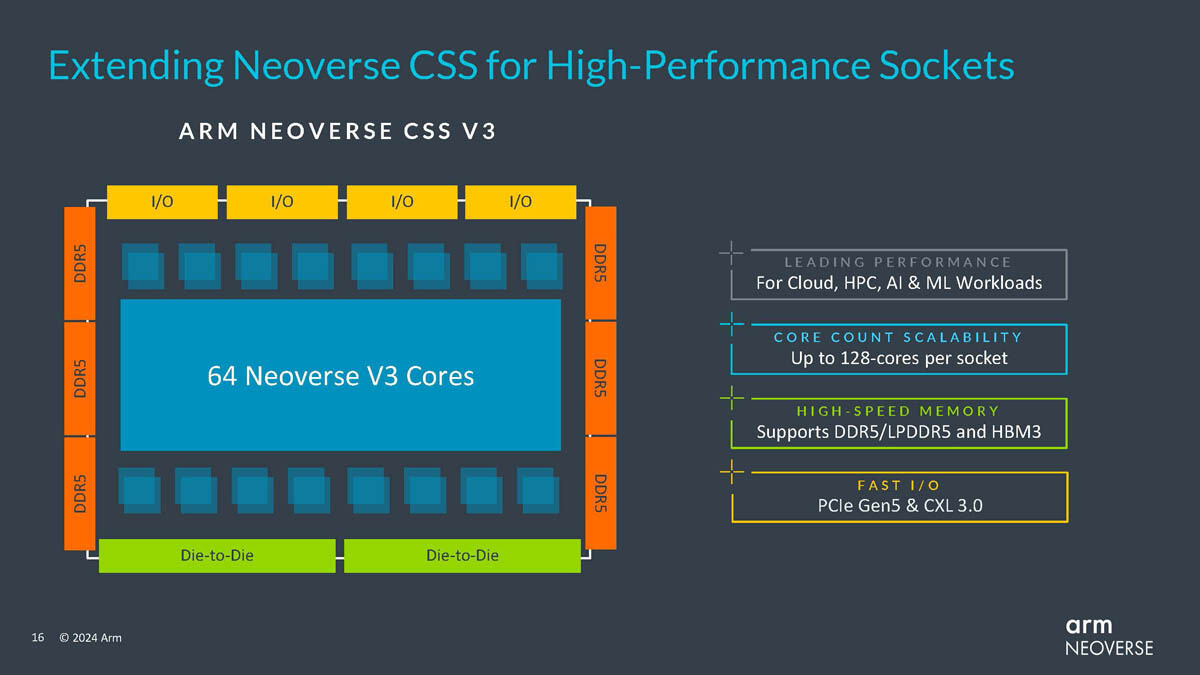
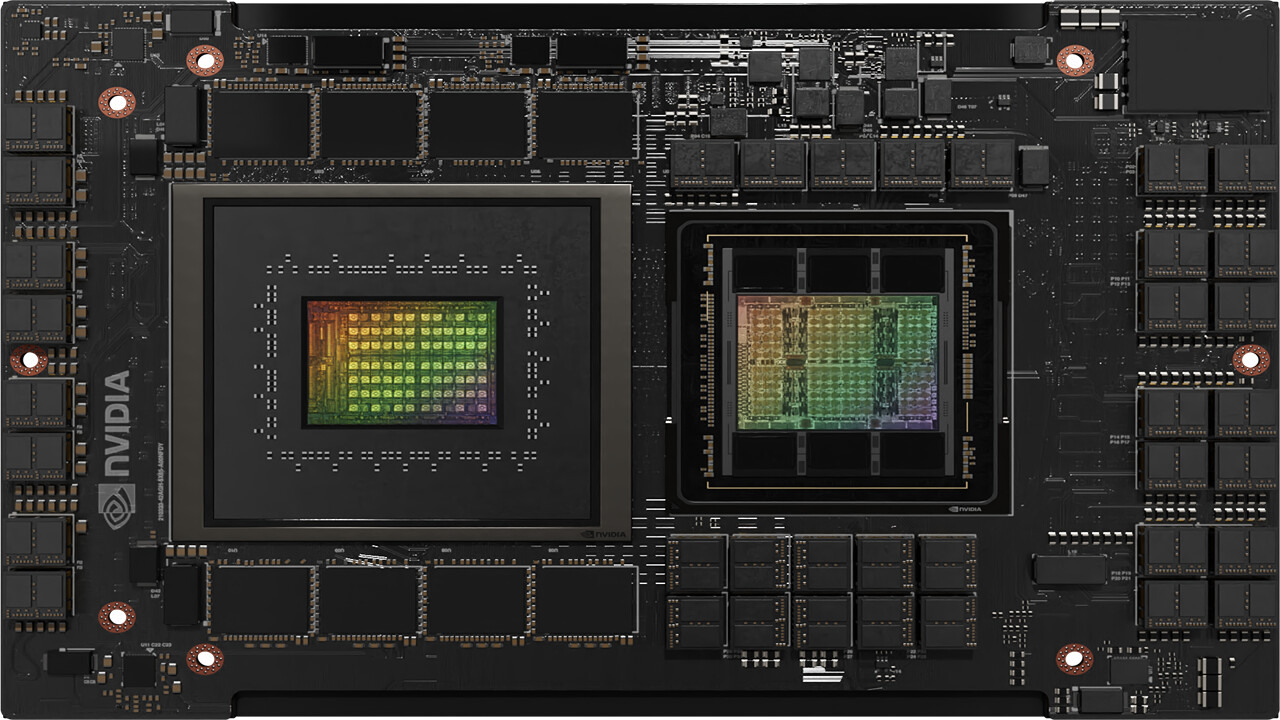
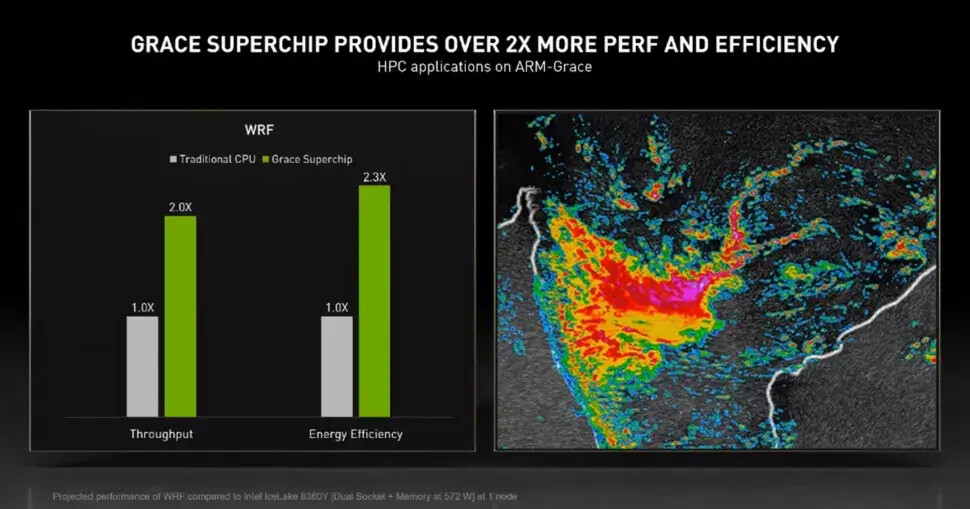
NVIDIA's next-gen Blackwell platform, which includes B-series GPUs and integrates NVIDIA's own Grace Arm CPU in models such as the GB200, represents a significant development. TrendForce points out that the GB200 and its predecessor, the GH200, both feature a combined CPU+GPU solution, primarily equipped with the NVIDIA Grace CPU and H200 GPU. However, the GH200 accounted for only approximately 5% of NVIDIA's high-end GPU shipments. The supply chain has high expectations for the GB200, with projections suggesting that its shipments could exceed millions of units by 2025, potentially making up nearly 40 to 50% of NVIDIA's high-end GPU market.
Although NVIDIA plans to launch products such as the GB200 and B100 in the second half of this year, upstream wafer packaging will need to adopt more complex and high-precision CoWoS-L technology, making the validation and testing process time-consuming. Additionally, more time will be required to optimize the B-series for AI server systems in aspects such as network communication and cooling performance. It is anticipated that the GB200 and B100 products will not see significant production volumes until 4Q24 or 1Q25.
Although NVIDIA plans to launch products such as the GB200 and B100 in the second half of this year, upstream wafer packaging will need to adopt more complex and high-precision CoWoS-L technology, making the validation and testing process time-consuming. Additionally, more time will be required to optimize the B-series for AI server systems in aspects such as network communication and cooling performance. It is anticipated that the GB200 and B100 products will not see significant production volumes until 4Q24 or 1Q25.