Nfina Technologies Releases 3rd Gen Intel Xeon Scalable Processor-based Systems
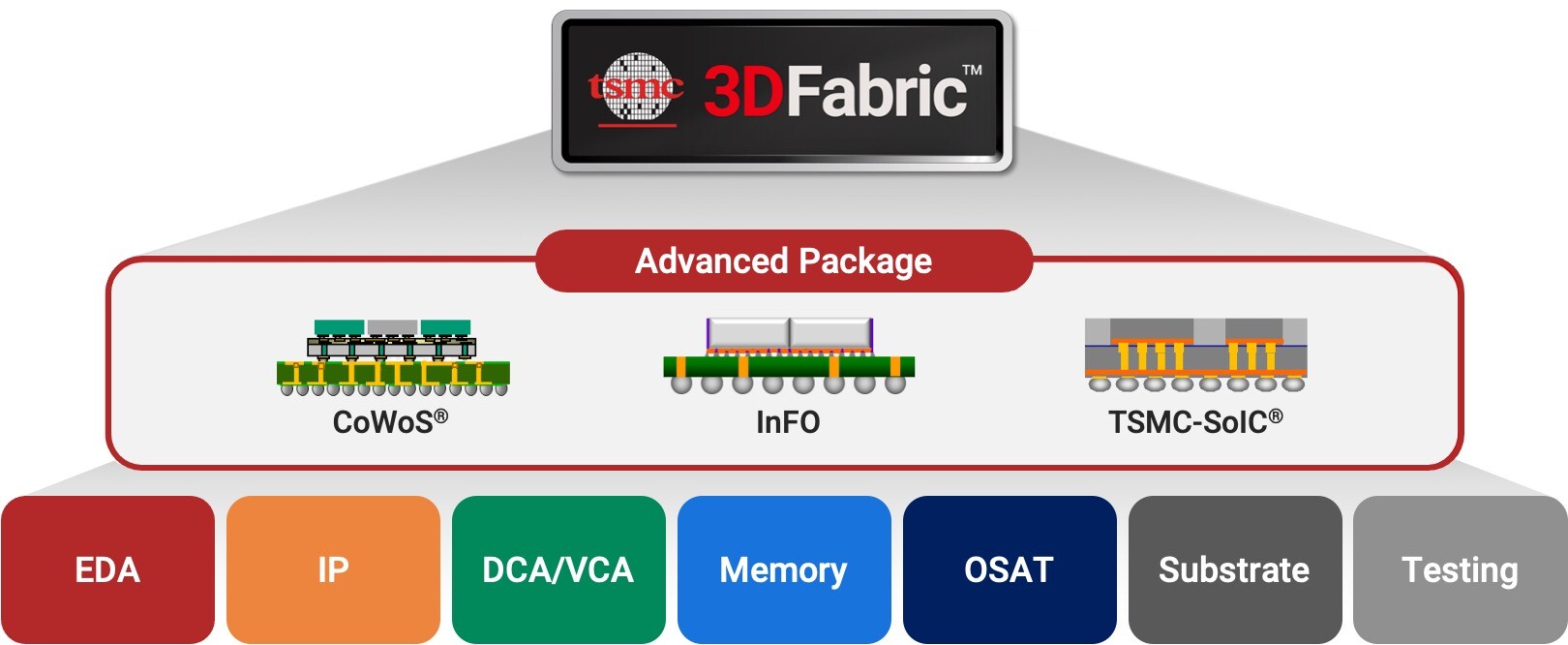
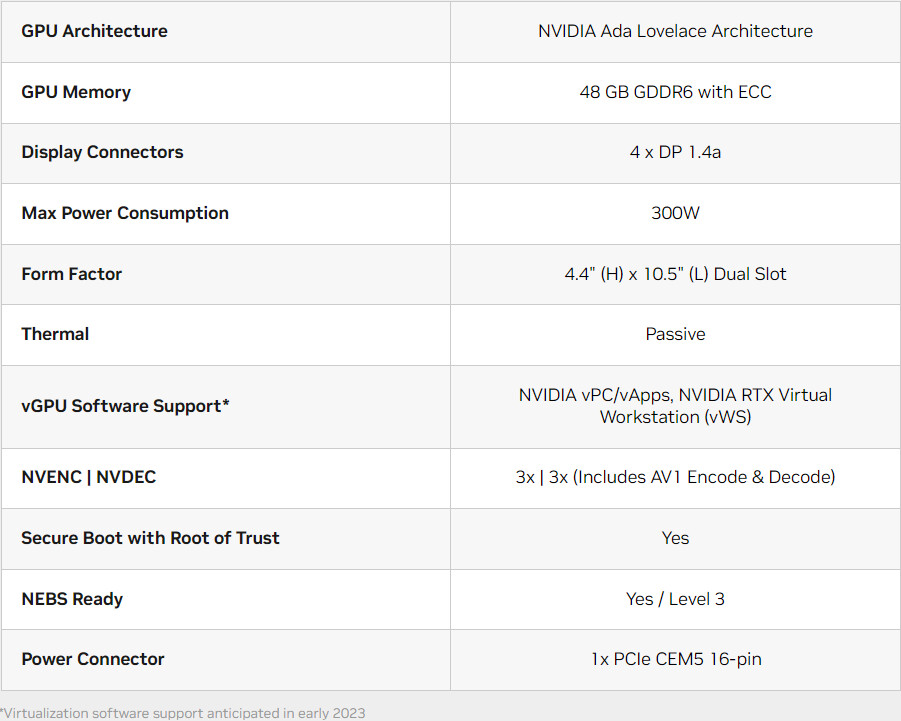
Nfina announces the addition of three new server systems to its lineup, customized for hybrid/multi-cloud, hyperconverged HA infrastructure, HPC, backup/disaster recovery, and business storage solutions. Featuring 3rd Gen Intel Xeon Scalable Processors, Nfina-Store, and Nfina-View software, these scalable server systems fill a void in the marketplace, bringing exceptional multi-socket processing performance, easy-to-use management tools, built-in backup, and rapid disaster recovery.
"We know we must build systems for the business IT needs of today while planning for unknown future demands. Flexible infrastructure is key, optimized for hybrid/multi-cloud, backup/disaster recovery, HPC, and growing storage needs," says Warren Nicholson, President, and CEO of Nfina. He continues by saying, "Flexible infrastructure also means offering managed services like IaaS, DRaaS, etc., that provide customers with choices that fit the size of their application and budget - not a one size fits all approach like many of our competitors. Our goal is to serve many different business IT applications, any size, anywhere, at any time."

"We know we must build systems for the business IT needs of today while planning for unknown future demands. Flexible infrastructure is key, optimized for hybrid/multi-cloud, backup/disaster recovery, HPC, and growing storage needs," says Warren Nicholson, President, and CEO of Nfina. He continues by saying, "Flexible infrastructure also means offering managed services like IaaS, DRaaS, etc., that provide customers with choices that fit the size of their application and budget - not a one size fits all approach like many of our competitors. Our goal is to serve many different business IT applications, any size, anywhere, at any time."