We Tested NVIDIA's new ChatRTX: Your Own GPU-accelerated AI Assistant with Photo Recognition, Speech Input, Updated Models
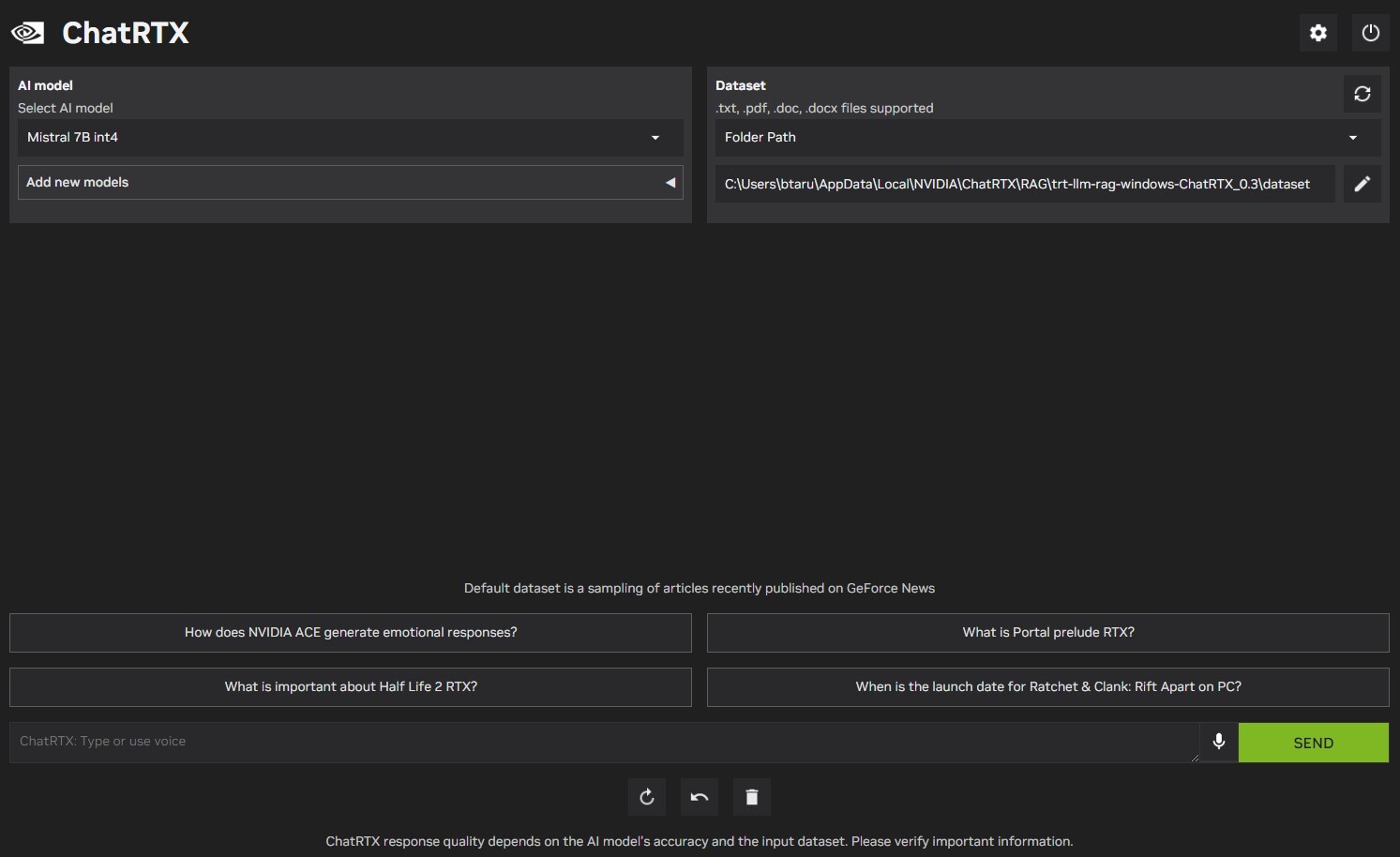
NVIDIA today unveiled ChatRTX, the AI assistant that runs locally on your machine, and which is accelerated by your GeForce RTX GPU. NVIDIA had originally launched this as "Chat with RTX" back in February 2024, back then this was regarded more as a public tech demo. We reviewed the application in our feature article. The ChatRTX rebranding is probably aimed at making the name sound more like ChatGPT, which is what the application aims to be—except it runs completely on your machine, and is exhaustively customizable. The most obvious advantage of a locally-run AI assistant is privacy—you are interacting with an assistant that processes your prompt locally, and accelerated by your GPU; the second is that you're not held back by performance bottlenecks by cloud-based assistants.
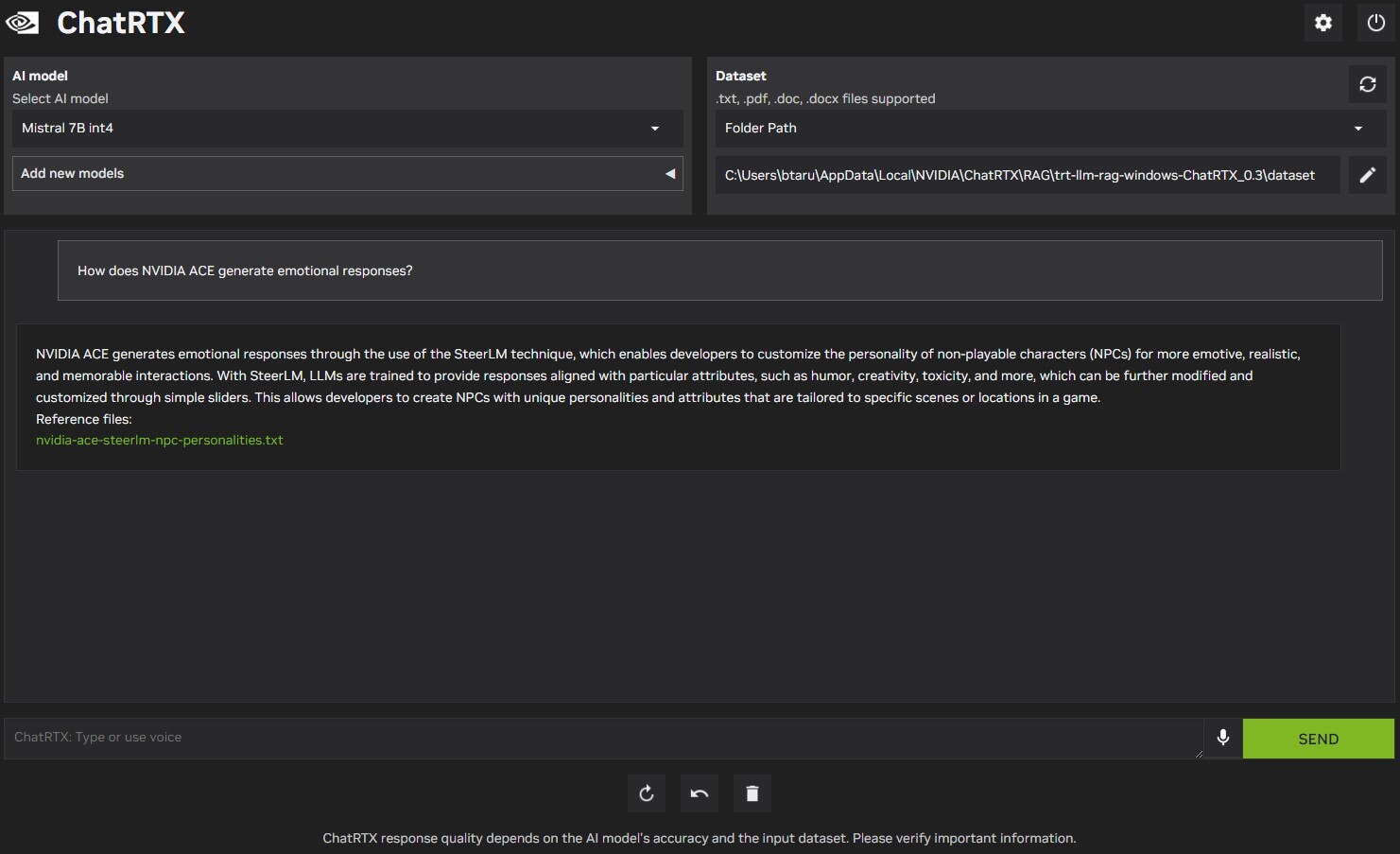
ChatRTX is a major update over the Chat with RTX tech-demo from February. To begin with, the application has several stability refinements from Chat with RTX, which felt a little rough on the edges. NVIDIA has significantly updated the LLMs included with the application, including Mistral 7B INT4, and Llama 2 7B INT4. Support is also added for additional LLMs, including Gemma, a local LLM trained by Google, based on the same technology used to make Google's flagship Gemini model. ChatRTX now also supports ChatGLM3, for both English and Chinese prompts. Perhaps the biggest upgrade ChatRTX is its ability to recognize images on your machine, as it incorporates CLIP (contrastive language-image pre-training) from OpenAI. CLIP is an LLM that recognizes what it's seeing in image collections. Using this feature, you can interact with your image library without the need for metadata. ChatRTX doesn't just take text input—you can speak to it. It now accepts natural voice input, as it integrates the Whisper speech-to-text NLI model.

 DOWNLOAD: NVIDIA ChatRTX
DOWNLOAD: NVIDIA ChatRTX
ChatRTX is a major update over the Chat with RTX tech-demo from February. To begin with, the application has several stability refinements from Chat with RTX, which felt a little rough on the edges. NVIDIA has significantly updated the LLMs included with the application, including Mistral 7B INT4, and Llama 2 7B INT4. Support is also added for additional LLMs, including Gemma, a local LLM trained by Google, based on the same technology used to make Google's flagship Gemini model. ChatRTX now also supports ChatGLM3, for both English and Chinese prompts. Perhaps the biggest upgrade ChatRTX is its ability to recognize images on your machine, as it incorporates CLIP (contrastive language-image pre-training) from OpenAI. CLIP is an LLM that recognizes what it's seeing in image collections. Using this feature, you can interact with your image library without the need for metadata. ChatRTX doesn't just take text input—you can speak to it. It now accepts natural voice input, as it integrates the Whisper speech-to-text NLI model.