 89
89
AMD FX-8150 3.60 GHz with Windows Patches Review
FX Lineup & FX-8150 »AM3+ platform
After a long and somewhat successful period of AM2 and AM2+, followed by not so long ago introduced AM3 socket, for the next few years AMD is going to lean on its newest AM3+ socket platform combined with processors based on the Bulldozer architecture. The new AM3+ socket has 942 pin count, compared to 941 found on previous AM3 socket. We wont be seeing any DDR2 motherboards anymore, as the new Bulldozer processors only has a native DDR3 memory controller, but we'll get to that in more detail later on.Compatibility wise, AM3+ has kept backward compatibility with AM3 processors, but new AM3+ processors will not be supported on older AM3 platforms. In other words, you can buy an AM3+ motherboard and continue using your current AM3 Phenom II or Athlon II processor with DDR3 memory, but you can't buy an AM3+ processor and put it in your older AM3 motherboards.
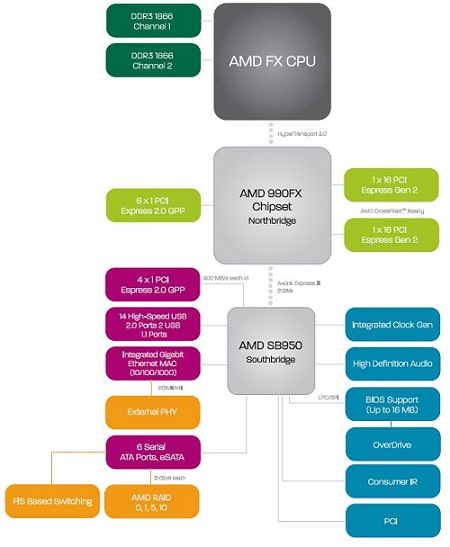
AMD's recently introduced 9-series chipset will be the heart of new AM3+ platform, but other than the name there are very few differences to older 800 series chipsets. The 900 series' flagship is an 990FX northbridge that has just two differences from its predecessor 890FX. When paired with Bulldozer, Hyper Transport will run at HT v3.1, which in theory runs up to 3200 MHz compared to HT v3.0 which runs up to 2600 MHz. This increases the bandwidth in communication between processor and the rest of the system, but it will run at HT 3.1 only with Bulldozer processors. Phenom II and Athlon II processors will run at HT 3.0 when used in any AM3+ motherboard. The Northbridge is providing in total 42 PCIe 2.0 lanes, of which 32 are for graphics cards and now support both AMD Crossfire and NVIDIA SLI; six PCIe lanes are available in 6x 1 PCIe combination, and last four PCIe lanes are reserved for A-Link Express III connection with the new SB950 Southbridge, which again, has the same specifications as the older SB850 - still no native USB 3.0 support, so AMD will have to rely on third party chips for providing USB 3.0.

To make matters more complicated, there have been AM3 boards on the market for quite some time now, using 800 series chipset and claiming to have AM3+ processor support. That is true only if those boards have implemented an AM3+ socket layout, also known as "black colored" socket featuring 942 pin holes. They will run your Bulldozer processors with proper BIOS update, but without the use of HT 3.1 support. Older AM3 boards using "white" 941 pin sockets so far offer limited support via beta BIOS updates, so please inform yourself about your motherboard CPU support before choosing to upgrade with Bulldozer sample.
Bulldozer
As stated in the introduction, Bulldozer is the name of the new architecture AMD will base future processors on, and in many ways it will lay the new foundation for AMD's core business. It will become basis for further architecture developments, something similar to K8 architecture long ago, and those foundations led to today's Phenom II processors, and K10.5 architecture revision. Although Bulldozer's architecture already had its bundle of bad critics, let's try to keep an open mind and try to understand AMD's newest product as best as we can.AMD launched the Bulldozer architecture with few keynotes, telling us what to expect from future products. In short, those keynotes were: great gaming experience, eight core processor with unlocked overclocking capabilities that would be part of a balanced performance PC, and of course new architecture. We're going to dig into that architecture, but on a small side-note, notice how they used the term "part of a BALANCED performance PC", even when launching the flagship model, that in fact should be something like "part of ULTIMATE performance PC"?

Bulldozer's architecture is based on building blocks, highly modular and adaptive designed, easily scaled to fit all demands. Its basic building block is a module, consisting of two integer cores, sharing some of the core's traditional resources; instruction fetcher and decoder, floating point unit and L2 cache memory. This makes a single Bulldozer module, in essence CMP (chip-level multiprocessing) style dual core processor. Although many would argue this is not a true dual core processor because of shared resources, unlike Intel that's using SMT (simultaneous multithreading), where two threads are processed virtually at the same time on one core, Bulldozer runs two threads trough two separate physical cores.
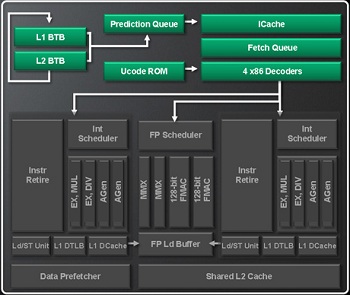
The entire process starts at newly designed front end with new prediction pipeline which tries to predict the next two instructions that are going to be used. The fetch unit loads those instructions onto four x86 decoders, one more than K10.5 had. Now we stumble upon the first possible problem in Bulldozer performance. Since the entire module front end is shared between cores, including fetch unit, it means the L1 cache is also shared between cores inside one Bulldozer module. Each module has a total of 96 KB L1 cache memory, of which 64 KB is shared two-way set associative instruction L1 cache, and each core receives 16 KB of dedicated L1 data cache memory, four-way associative. If we look at the Phenom II processor, they had 64 KB L1 data and 64 KB L1 instruction cache memory. So even with a core architecture so much more complex, L1 cache received a noticeable cut down in size.

After the decoder is done converting x86 instructions to much simpler micro-instructions, they are assigned to either floating point unit or one of the two integer units - or cores if you like the sound of it. Another thing that's shared here, a single floating point unit per module, heavily upgraded compared to Phenom II processors. Now featuring dual integer MMX units for basic floating point instructions and also dual 128-bit FMAC units.
These new FMAC (fused multiply-accumulate function) units are capable of performing two functions, multiply and add in one cycle, whereas traditional FP unit required separate cycles. Two FMAC units also work separately executing instructions that are ready for processing, without waiting for other unit to be done. In addition to standard x86 instructions, the new FPU unit supports SSE3, SSE4a, SSE4.1, SSE4.2, AES-NI and AVX instructions.

Two integer cores per module both have four execution units capable of processing four arithmetical or memory out of order operations in one cycle, per core. Instructions are not executed in order they come in. If one instruction requires execution on a unit that is busy, the out of order scheduler will fetch another instruction that can be executed right away on another execution unit, thus removing idle time where no instructions would be processed. Two EX MUL units can execute integer instruction including multiplication, excluding division, while EX DIV excludes multiplication operations. Two Agen units on the other hand are responsible for assigning address for data storage. Instructions are put back into order in the Integer Retire unit, after they are executed. The load/store unit is tasked for loading or storing data in memory, and is capable of two 128-bit loads and one 128-bit store per cycle.
On the outer rim of a Bulldozer module sits L2 cache, in total 2048 KB of it, 16-way associative. The L2 cache memory is shared between cores, and is a substantial increase over 512 KB in Phenom II or 1024 KB in some Athlon II processors, but there every L2 cache had its dedicated core. Contrary to the positive increase in size, L2 cache load-to-load latency jumped to 18-20 cycles and bus remained at 128-bit, compared to 10 cycles on previous K10.5 generation processors. The trade off for these higher latency clocks are seen in higher core frequencies, where Bulldozer cores easily overclock the older generation of processors. Like L1 data cache, L2 data cache also has a Data Prefetcher Unit, capable of 23 outstanding misses, and loading speculative data into the cache data bank, in other words, it tries to predict which of the instructions will be needed next, and loads them into buffer, ready to be sent to L1 cache, and onto further processing.
In the end, a complete Bulldozer module featuring its heavily redesigned front end, two integer units, one floating point unit and L2 cache memory, looks maybe a bit more complicated than AMD talked about as the architecture was in development. A vast number of critical processor functions are shared between the cores, and with just one data prefetch and decode unit, both of the cores can only process four instructions per clock, making a Bulldozer module theoretical counterpart to Intel's single core Sandy Bridge.
Uncore level - Northbridge
The last unit, transforming the Bulldozer architecture to Zambezi processor core is the on die northbridge. Part of the northbride is an 8 MB large, L3 cache memory shared between all modules, and like with Phenom II processors it's exclusive in its hierarchy, meaning it doesn't necessarily include all the data from L1 and L2 caches. L3 cache can be partitioned if needed, and supports 72-bit ECC, and Probe Filter function.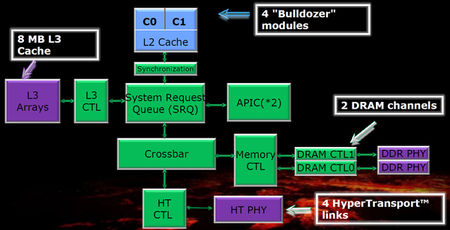
The System Request Queue and Crossbar modules shown in the diagram are the real brains behind the new northbridge. They are charged with information traffic control, redirecting all of the information from their source to destination. The SRQ handles all the traffic and requests from module cores, L3 cache and APICs. It's interesting to know that SRQ can also process core requests from other processors in multisocket setups. Crossbar on the other hand deals with system memory and HyperTransport infromation flow. Together, these two modules ensure that the data needed will be on disposal in shortest possible time, without wasting any unnecessary bandwidth...that's the idea anyways.
The Zambezi processor has two memory controllers, supporting DDR3 only, and up to 1866 MHz speed in dual channel configuration. DDR3 1600 MHz is supported in four sticks configurations only, tough. Controllers support unbuffered, registered, and Load Reduced type of memories, working at 1.50 V, 1.35 V or 1.25 V. The memory controller received a heavy upgrade on the power management side, and now supports a whole variate of tips and tricks on how to eliminate any excess power usage.
Four HyperTransport links are also upgraded and are now running 5.2 GT/s, each 16 bit wide and can be split into two 8 bit links (multiprocessor configuration). The number of active links is dependent on the configuration in which Zambezi's core will be used. For the desktop market, only one HT link will be active, and will be used to communicate with the chipset. Other links are reserved for server specifications, where they will be used for processor to processor communication.
Turbo Core & Power Saving

Two major features AMD boasted about are Turbo Core and improved power saving features. Turbo Core was taken from the previous generation six core processor and heavily overhauled. In addition, to the two so far known power states (P-state), the base clock, P2, and Turbo Core P1, AMD added another state called Max Turbo Core and carries a P0 designation. P2 state is what you get when you disable Turbo Core altogether, the maximum base clock. Enabling Turbo Core, Bulldozer's Application Power Management (APM) module is constantly tracking each module's power consumption in real-time, and if all modules and cores are working below the processor's TDP, the processor goes to P1 state and all core frequencies are increased. To activate P0 state, or Max Turbo Core, only half of the modules must be running. In that case, all of the L1 and L2 caches are flushed to L3 cache, and the whole module enters a CC6 sleep mode, and all power to that module is gated.
CC6 sleep state works in conjunction with Turbo Core, but it's also active on its own, shutting down modules whenever they're not under load, thus saving power. CC6 state is limited to per module functionality, as much of the module's resources are shared between the two cores, AMD decided it would be easier or more power efficient to shut down entire modules with both cores' current state saved to L3 buffer. If CC6 state represents the utmost power efficient state, or shut down state, that would imply that between base clock P2 and CC6 (P6), are three more power saving P3, P4, and P5 states, each setting the core frequency and voltage to lower and lower values.
Although complete power gating is supported per module only, clock adjustment is done per core, so those cores not under load idle at lower voltage and frequency levels. To improve performance with light-threaded and light-load tasks, the minimum clock level for cores is set to 1400 MHz, a big 800 MHz bump over Phenom II idle clocks. This should result in better responsiveness when dealing with small tasks and every day computing, but it could also mean slightly more power consumption in idle.
May 17th, 2024 10:07 EDT
change timezone
Latest GPU Drivers
New Forum Posts
- Finally a lithium starting battery (5)
- What's your latest tech purchase? (20545)
- 20 Years? (40)
- RX7900XT stealth update and adrenalin left on old version (5)
- Do you use Linux? (257)
- Hi, my GPU suddenly dropped in performance 2 days ago and i have been trying to fix it since then, my GPU clock is capped at 300 MHz (5)
- LOL ASUS says this is $200 in repair, Steve from gamers Nexus smokes ASUS, Steam Deck til I die boys!!!! (104)
- EULA in Games (28)
- Sapphire Rx 6700 XT (2)
- Would you pay more for hardware with AI capabilities? (28)
Popular Reviews
- Homeworld 3 Performance Benchmark Review - 35 GPUs Tested
- Enermax REVOLUTION D.F. X 1200 W Review
- Lofree Edge Ultra-Low Profile Wireless Mechanical Keyboard Review
- Silverstone Shark Force 120 mm Fan Review
- Ghost of Tsushima Performance Benchmark Review - 35 GPUs Tested
- Upcoming Hardware Launches 2023 (Updated Feb 2024)
- AMD Ryzen 7 7800X3D Review - The Best Gaming CPU
- ZMF Caldera Closed Planar Magnetic Headphones Review
- Corsair MP700 Pro SE 4 TB Review
- Horizon Forbidden West Performance Benchmark Review - 30 GPUs Tested
Controversial News Posts
- Intel Statement on Stability Issues: "Motherboard Makers to Blame" (268)
- AMD to Redesign Ray Tracing Hardware on RDNA 4 (227)
- Windows 11 Now Officially Adware as Microsoft Embeds Ads in the Start Menu (172)
- NVIDIA to Only Launch the Flagship GeForce RTX 5090 in 2024, Rest of the Series in 2025 (154)
- AMD Hits Highest-Ever x86 CPU Market Share in Q1 2024 Across Desktop and Server (138)
- AMD RDNA 5 a "Clean Sheet" Graphics Architecture, RDNA 4 Merely Corrects a Bug Over RDNA 3 (130)
- AMD's RDNA 4 GPUs Could Stick with 18 Gbps GDDR6 Memory (114)
- AMD Ryzen 9 7900X3D Now at a Mouth-watering $329 (104)