Wednesday, September 21st 2022

NVIDIA Ada AD102 Block Diagram and New Architectural Features Detailed
At the heart of the GeForce RTX 4090 is the gigantic AD102 silicon, which we broadly detailed in an older article. Built on the 4 nm silicon fabrication process, this chip measures 608 mm² in die-area, and crams in 76.3 billion transistors. We now have our first look into the silicon-level block diagram of the AD102, including the introduction of several new components.
The AD102 features a PCI-Express 4.0 x16 host interface, and a 384-bit GDDR6X memory interface. The Gigathread Engine acts as a the main resource allocation component of the silicon. Ada introduces the Optical Flow Accelerator, a component crucial for DLSS 3 to generate entire frames without involving the graphics rendering machinery. The chip features double the number of media-encoding hardware engines as "Ampere," including hardware-accelerated AV1 encode/decode. Multiple accelerators mean that multiple streams of videos can be transcoded (helpful in a media production environment), or transcoding is performed at twice the FPS rate (each encoder takes turns at encoding a single frame).


 The main graphics rendering components of the AD102 are the GPCs (graphics processing clusters). There are 12 of these, compared to 7 on the previous-generation GA102. Each GPC shares a raster engine and render backends with six TPCs (texture processing clusters). Each TPC packs two SMs (streaming multiprocessors), the indivisible number-crunching machinery of the NVIDIA GPU. The SM is where maximum architectural innovation is done by NVIDIA. Each SM packs a 3rd generation RT core, a 128 KB L1 cache, and four TMUs, among four clusters that each pack 16 FP32 CUDA cores, 16 concurrent FP32+INT32 CUDA cores, 4 load/store units, a tiny L0 cache with warp-scheduler and threat-dispatch; a register file, and the all-important 4th generation Tensor core.
The main graphics rendering components of the AD102 are the GPCs (graphics processing clusters). There are 12 of these, compared to 7 on the previous-generation GA102. Each GPC shares a raster engine and render backends with six TPCs (texture processing clusters). Each TPC packs two SMs (streaming multiprocessors), the indivisible number-crunching machinery of the NVIDIA GPU. The SM is where maximum architectural innovation is done by NVIDIA. Each SM packs a 3rd generation RT core, a 128 KB L1 cache, and four TMUs, among four clusters that each pack 16 FP32 CUDA cores, 16 concurrent FP32+INT32 CUDA cores, 4 load/store units, a tiny L0 cache with warp-scheduler and threat-dispatch; a register file, and the all-important 4th generation Tensor core.
Each SM hence packs a total of 128 CUDA cores, 4 Tensor cores, and an RT core. There are 12 SM per GPC, so 1,536 CUDA cores, 48 Tensor cores, and 12 RT cores; per GPC. Twelve GPCs hence add up to 18,432 CUDA cores, 576 Tensor cores, and 144 RT cores. Each GPC contributes 16 ROPs, so there are a mammoth 192 ROPs on the silicon. An L2 cache serves as town-square for the various GPCs, memory controllers, and the PCIe host interface, to exchange data. NVIDIA didn't mention the size of this L2 cache, but it is said to be significantly larger than the previous generation, and is playing a major role in lubricating the memory sub-system enough that NVIDIA can retain the same 21 Gbps @ 384-bit data-rate of the previous-generation.
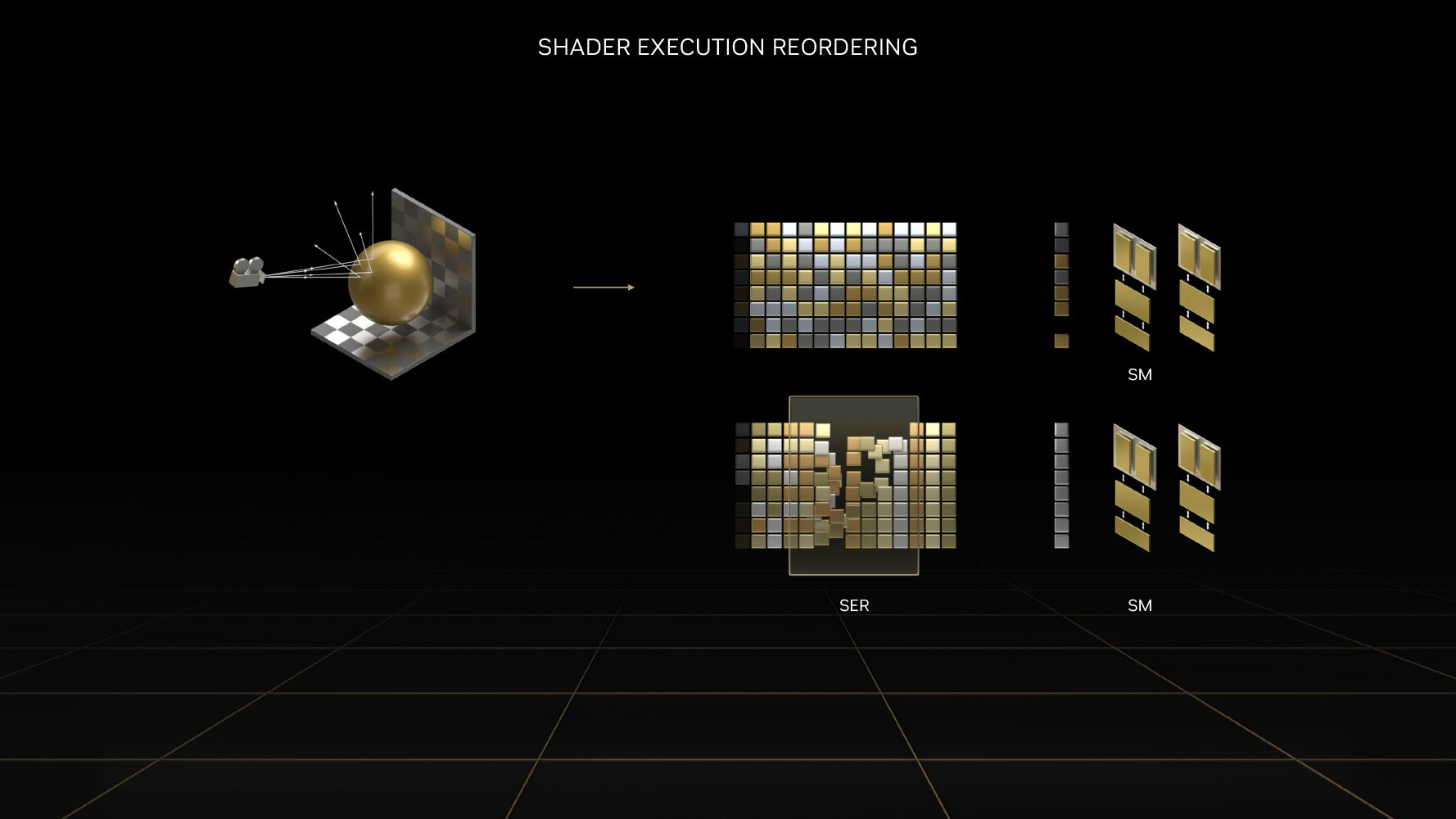
 NVIDIA is introducing shader execution reordering, (SER), a new technology that reorganizes math workloads to be relevant to each worker thread, so it is more efficiently processed by the SIMD components. This is expected to have a particularly big impact on rendering games with ray tracing. A GPU works best when the same operation can be executed on multiple targets. For example, when rendering a triangle, each pixel runs the same shader in parallel. With ray tracing, each ray at a time can execute a completely different piece of code, because it goes in a slightly different direction. With SER, the GPU will "sort" the operations, to create chunks of identical tasks and execute them in parallel. In Cyberpunk 2077 with its new Overdrive graphics preset that significantly dials up RT calculations per pixel, SER improves performance up to 44 percent. NVIDIA is developing Portal RTX, a mod for the original game with RTX effects added. Here, SER improves performance by 29 percent. It is also said to have a 20 percent performance impact on the Racer RTX interactive tech-demo we'll see this November. NVIDIA commented that there's various SER approaches and the best choice vary by-game, so they exposed the shader reordering functionality to game developers as an API, so they have control over how the sorting algorithm works, to best optimize their performance.
NVIDIA is introducing shader execution reordering, (SER), a new technology that reorganizes math workloads to be relevant to each worker thread, so it is more efficiently processed by the SIMD components. This is expected to have a particularly big impact on rendering games with ray tracing. A GPU works best when the same operation can be executed on multiple targets. For example, when rendering a triangle, each pixel runs the same shader in parallel. With ray tracing, each ray at a time can execute a completely different piece of code, because it goes in a slightly different direction. With SER, the GPU will "sort" the operations, to create chunks of identical tasks and execute them in parallel. In Cyberpunk 2077 with its new Overdrive graphics preset that significantly dials up RT calculations per pixel, SER improves performance up to 44 percent. NVIDIA is developing Portal RTX, a mod for the original game with RTX effects added. Here, SER improves performance by 29 percent. It is also said to have a 20 percent performance impact on the Racer RTX interactive tech-demo we'll see this November. NVIDIA commented that there's various SER approaches and the best choice vary by-game, so they exposed the shader reordering functionality to game developers as an API, so they have control over how the sorting algorithm works, to best optimize their performance.
 Displaced micro-mesh engine is a revolutionary feature introduced with the new 3rd generation RT core, which accelerates the displaced micro-mesh feature. Just as mesh shaders and tessellation have had a profound impact on improving performance with complex raster geometry, allowing game developers to significantly increase geometric complexity; DMMs is a method to reduce the complexity of the bounding-volume hierarchy (BVH) data-structure, which is used to determine where a ray hits geometry. Previously the BVH had to capture even the smallest details, to properly determine the intersection point.
Displaced micro-mesh engine is a revolutionary feature introduced with the new 3rd generation RT core, which accelerates the displaced micro-mesh feature. Just as mesh shaders and tessellation have had a profound impact on improving performance with complex raster geometry, allowing game developers to significantly increase geometric complexity; DMMs is a method to reduce the complexity of the bounding-volume hierarchy (BVH) data-structure, which is used to determine where a ray hits geometry. Previously the BVH had to capture even the smallest details, to properly determine the intersection point.
 The BVH now needn't have data for every single triangle on an object, but can represent objects with complex geometry as a coarse mesh of base triangles, which greatly simplifies the BVH data structure. A simpler BVH means less memory consumed and helps to greatly reduce ray tracing CPU load, because the CPU only has to generate a smaller structure. With older "Ampere" and "Turing" RT cores, each triangle on an object had to be sampled at high overhead, so the RT core could precisely calculate ray intersection for each triangle. With Ada, the simpler BVH, plus the displacement maps can be sent to the RT core, which is now able to figure out the exact hit point on its own. NVIDIA has seen 11:1 to 28:1 compression in total triangle counts. This reduces BVH compile speedups by 7.6x to over 15x, in comparison to the older RT core; and reducing its storage footprint by anywhere between 6.5 to 20 times. DMMs could reduce disk- and memory bandwidth utilization, utilization of the PCIe bus, as well as reduce CPU utilization. NVIDIA worked with Simplygon and Adobe to add DMM support for their tool chains.
The BVH now needn't have data for every single triangle on an object, but can represent objects with complex geometry as a coarse mesh of base triangles, which greatly simplifies the BVH data structure. A simpler BVH means less memory consumed and helps to greatly reduce ray tracing CPU load, because the CPU only has to generate a smaller structure. With older "Ampere" and "Turing" RT cores, each triangle on an object had to be sampled at high overhead, so the RT core could precisely calculate ray intersection for each triangle. With Ada, the simpler BVH, plus the displacement maps can be sent to the RT core, which is now able to figure out the exact hit point on its own. NVIDIA has seen 11:1 to 28:1 compression in total triangle counts. This reduces BVH compile speedups by 7.6x to over 15x, in comparison to the older RT core; and reducing its storage footprint by anywhere between 6.5 to 20 times. DMMs could reduce disk- and memory bandwidth utilization, utilization of the PCIe bus, as well as reduce CPU utilization. NVIDIA worked with Simplygon and Adobe to add DMM support for their tool chains. Opacity Micro Meshes (OMM) is a new feature introduced with Ada to improve rasterization performance, particularly with objects that have alpha (transparency data). Most low-priority objects in a 3D scene, such as leaves on a tree, are essentially rectangles with textures on the leaves where the transparency (alpha) creates the shape of the leaf. RT cores have a hard time intersecting rays with such objects, because they're not really in the shape that they appear (they're really just rectangles with textures that give you the illusion of shape. Previous-generation RT cores had to have multiple interactions with the rendering stage to figure out the shape of a transparent object, because they couldn't test for alpha by themselves.
Opacity Micro Meshes (OMM) is a new feature introduced with Ada to improve rasterization performance, particularly with objects that have alpha (transparency data). Most low-priority objects in a 3D scene, such as leaves on a tree, are essentially rectangles with textures on the leaves where the transparency (alpha) creates the shape of the leaf. RT cores have a hard time intersecting rays with such objects, because they're not really in the shape that they appear (they're really just rectangles with textures that give you the illusion of shape. Previous-generation RT cores had to have multiple interactions with the rendering stage to figure out the shape of a transparent object, because they couldn't test for alpha by themselves.
 This has been solved by using OMMs. Just as DMMs simplify geometry by creating meshes of micro-triangles; OMMs create meshes of rectangular textures that align with parts of the texture that aren't alpha, so the RT core has a better understanding of the geometry of the object, and can correctly calculate ray intersections. This has a significant performance impact on shading performance in non-RT applications, too. Practical applications of OMMs aren't just low-priority objects such as vegetation, but also smoke-sprites and localized fog. Traditionally there was a lot of overdraw for such effects, because they layered multiple textures on top of each other, that all had to be fully processed by the shaders. Now only the non-opaque pixels get executed—OMMs provide a 30 percent speedup with graphics buffer fill-rates, and a 10 percent impact on frame-rates.
This has been solved by using OMMs. Just as DMMs simplify geometry by creating meshes of micro-triangles; OMMs create meshes of rectangular textures that align with parts of the texture that aren't alpha, so the RT core has a better understanding of the geometry of the object, and can correctly calculate ray intersections. This has a significant performance impact on shading performance in non-RT applications, too. Practical applications of OMMs aren't just low-priority objects such as vegetation, but also smoke-sprites and localized fog. Traditionally there was a lot of overdraw for such effects, because they layered multiple textures on top of each other, that all had to be fully processed by the shaders. Now only the non-opaque pixels get executed—OMMs provide a 30 percent speedup with graphics buffer fill-rates, and a 10 percent impact on frame-rates.

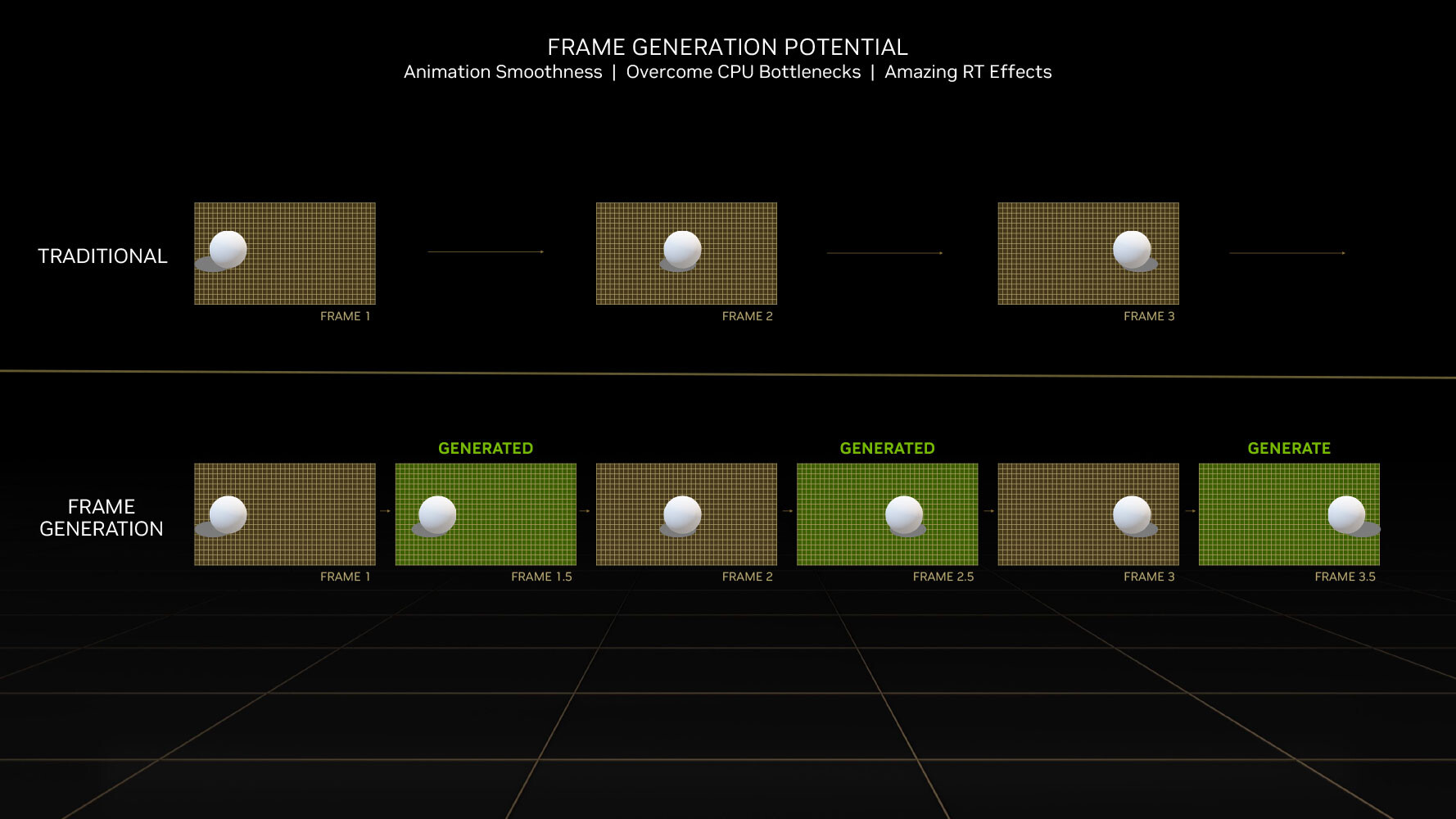
 DLSS 3 introduces a revolutionary new feature that promises a doubling in frame-rate at comparable quality, it's called AI frame-generation. While it has all the features of DLSS 2 and its AI super-resolution (scaling up a lower-resolution frame to native resolution with minimal quality loss); DLSS 3 can generate entire frames simply using AI, without involving the graphics rendering pipeline. Every alternating frame with DLSS 3 is hence AI-generated, without being a replica of the previous rendered frame.
DLSS 3 introduces a revolutionary new feature that promises a doubling in frame-rate at comparable quality, it's called AI frame-generation. While it has all the features of DLSS 2 and its AI super-resolution (scaling up a lower-resolution frame to native resolution with minimal quality loss); DLSS 3 can generate entire frames simply using AI, without involving the graphics rendering pipeline. Every alternating frame with DLSS 3 is hence AI-generated, without being a replica of the previous rendered frame.


 This is possible only on the Ada graphics architecture, because of a hardware component called optical flow accelerator (OFA), which assists in predicting what the next frame could look like, by creating what NVIDIA calls an optical flow-field. OFA ensures that the DLSS 3 algorithm isn't confused by static objects in a rapidly-changing 3D scene (such as a race sim). The process heavily relies on the performance uplift introduced by the FP8 math format of the 4th generation Tensor core.
This is possible only on the Ada graphics architecture, because of a hardware component called optical flow accelerator (OFA), which assists in predicting what the next frame could look like, by creating what NVIDIA calls an optical flow-field. OFA ensures that the DLSS 3 algorithm isn't confused by static objects in a rapidly-changing 3D scene (such as a race sim). The process heavily relies on the performance uplift introduced by the FP8 math format of the 4th generation Tensor core.
 A third key ingredient of DLSS 3 is Reflex. By reducing the rendering queue to zero, Reflex plays a vital role in ensuring the frame-times with DLSS 3 are at an acceptable level, and a render-queue doesn't confuse the upscaler. A combination of OFA and 4th gen Tensor core is why the Ada architecture is required to use DLSS 3, and why it won't work on older architectures.
A third key ingredient of DLSS 3 is Reflex. By reducing the rendering queue to zero, Reflex plays a vital role in ensuring the frame-times with DLSS 3 are at an acceptable level, and a render-queue doesn't confuse the upscaler. A combination of OFA and 4th gen Tensor core is why the Ada architecture is required to use DLSS 3, and why it won't work on older architectures.
The AD102 features a PCI-Express 4.0 x16 host interface, and a 384-bit GDDR6X memory interface. The Gigathread Engine acts as a the main resource allocation component of the silicon. Ada introduces the Optical Flow Accelerator, a component crucial for DLSS 3 to generate entire frames without involving the graphics rendering machinery. The chip features double the number of media-encoding hardware engines as "Ampere," including hardware-accelerated AV1 encode/decode. Multiple accelerators mean that multiple streams of videos can be transcoded (helpful in a media production environment), or transcoding is performed at twice the FPS rate (each encoder takes turns at encoding a single frame).
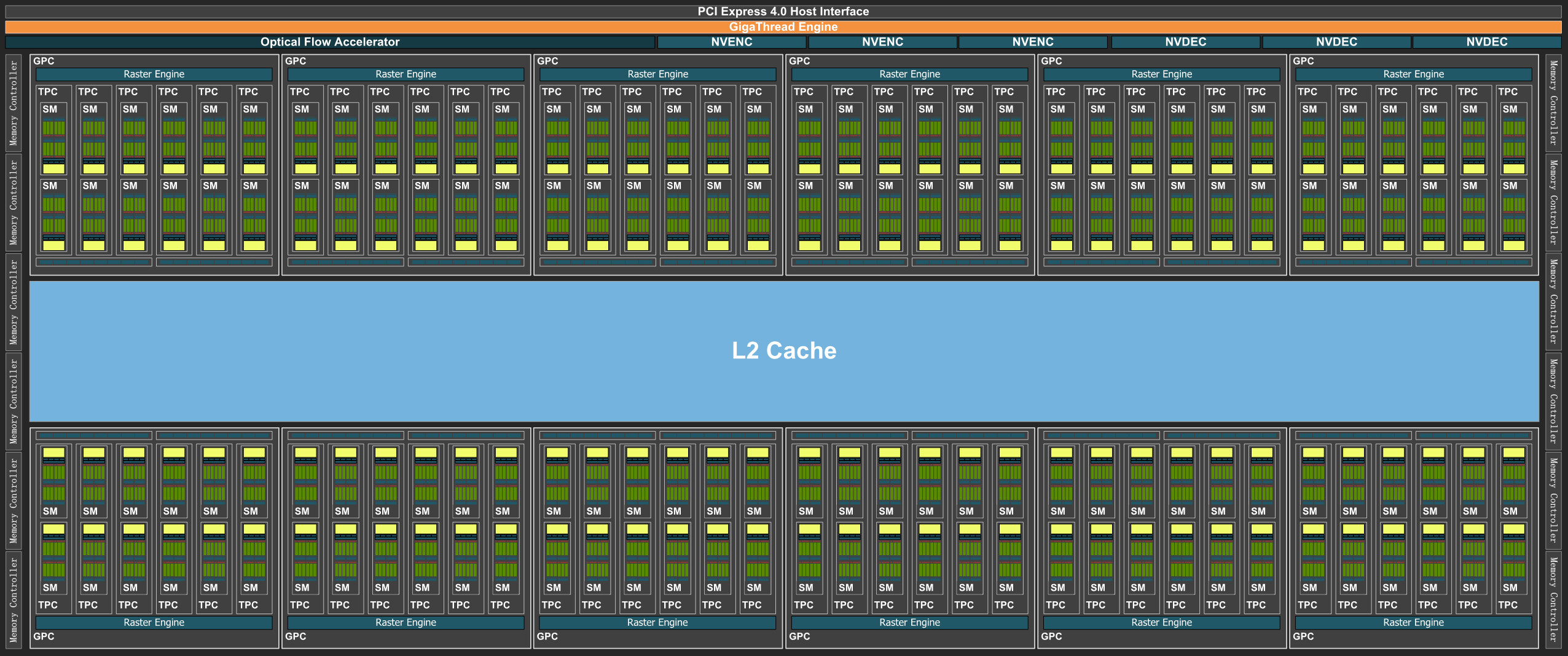
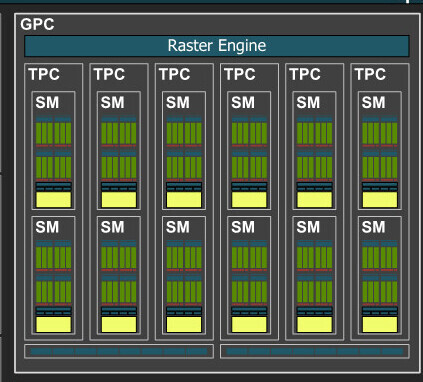


Each SM hence packs a total of 128 CUDA cores, 4 Tensor cores, and an RT core. There are 12 SM per GPC, so 1,536 CUDA cores, 48 Tensor cores, and 12 RT cores; per GPC. Twelve GPCs hence add up to 18,432 CUDA cores, 576 Tensor cores, and 144 RT cores. Each GPC contributes 16 ROPs, so there are a mammoth 192 ROPs on the silicon. An L2 cache serves as town-square for the various GPCs, memory controllers, and the PCIe host interface, to exchange data. NVIDIA didn't mention the size of this L2 cache, but it is said to be significantly larger than the previous generation, and is playing a major role in lubricating the memory sub-system enough that NVIDIA can retain the same 21 Gbps @ 384-bit data-rate of the previous-generation.















21 Comments on NVIDIA Ada AD102 Block Diagram and New Architectural Features Detailed
The technological innovations are cool, though. I hope at least the RT-related ones won't be Nvidia exclusive.
Will we see the push in reviews and benchmarks to include as much of these new games and architecture as possible, to really skew the results against the Ampere and AMD cards?
The way I see it, 2x and 3x claims from Nvidia keynote presentation are all achieved by using such architecture and game changes, not by actually be 2x, 3x faster...
"NVIDIA is introducing shader execution reordering, (SER), a new technology that reorganizes math workloads to be relevant to each worker thread, so it is more efficiently processed by the SIMD components. This is expected to have a particularly big impact on rendering games with ray tracing."
;)
Nvidia already picked all the low hanging fruit on raster
How about waiting for benchmarks before declaring IPC has/hasn't improved? Does that work for you?
Poll: Would you buy a RTX 4xxx, without RT, but 15-20% cheaper ?
and as you said, all the RT-DLSS3 stuff is just a gimmick until every game will support it from day 1 (or be automatically backward compatible - which will not happen of course).
I just want every game with DLSS2-FSR2 with no RTX at all. I live happily with 'baked scenes' just as I know the every game is fictional.
I actually would want to pay just for more RT performance. And I absolutely do not want to give up tensor cores. DLSS is one of the best things ever invented for games.
GPUs have gotten too big when manufacturing them was still cheap. If high-end cards had stayed below 400 mm2, we would not be having this problem. Currently new processes are very expensive, and GPUs still have to be big to get any performance gains. I will just wait out this transition period until mid-range cards can offer a performance increase for me.
Realistic reflections do not make a game realistic when everything else is not.
Why? Because they feature RTGI on top of other effects. And lighting is the primary factor affecting visual realism (and do not confuse realistic light behavior with artistic design, two completely different things).
But both games are difficult to run on a 3080 even with DLSS Performance when you turn RT on.
I usually do not bother with RT in games that only use it for shadows or reflections, unless I do not have to sacrifice anything to turn those on.
RTGI is incredible. Just look at Lumen in UE5, the Matrix demo for example.
The worst thing about devs implementing RTGI is that the non-RT lighting model suffers greatly. Without RTGI, both Metro and DL2 look much worse compared to beautiful games like Horizon Forbidden West or even Far Cry 6. The Matrix demo without Lumen also looked bad.
You can fake really good GI with rasterization, but they do not bother doing both if they can use RT. Crysis 3 had some impressive voxel-based GI, but that is difficult to do and has a high performance cost as well, and it is nowhere near as accurate as path tracing.
RTGI is very uncommon right now, because of performance reasons. Ada GPUs can change that, but if nobody can afford those cards, nobody will play with RTGI anyway.
As for DLSS, you could run it without tensor cores, but performance would be lower. Could that be balanced by adding more CUDA cores instead? Possibly. Did they lock it to tensor cores only to sell more RTX cards? Possibly, but they could have locked it to RTX cards even without tensor cores, so why do it this way? We will probably never know.