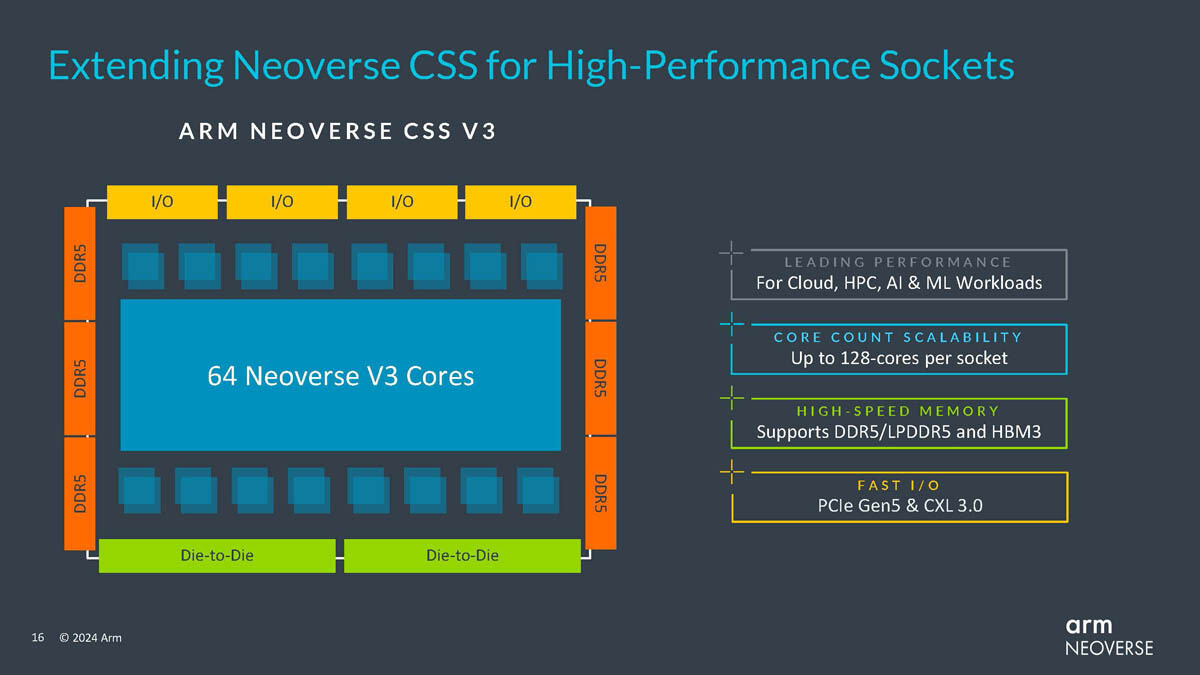
TSMC Celebrates 30th North America Technology Symposium with Innovations Powering AI with Silicon Leadership
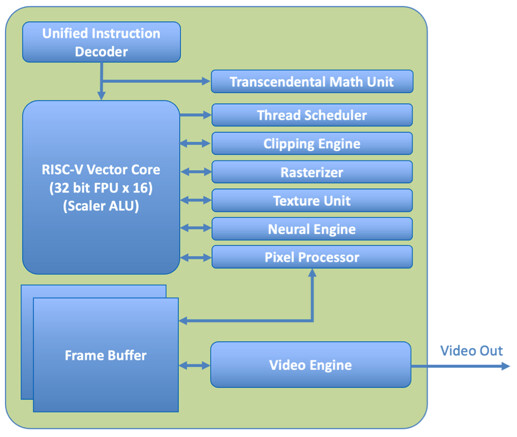
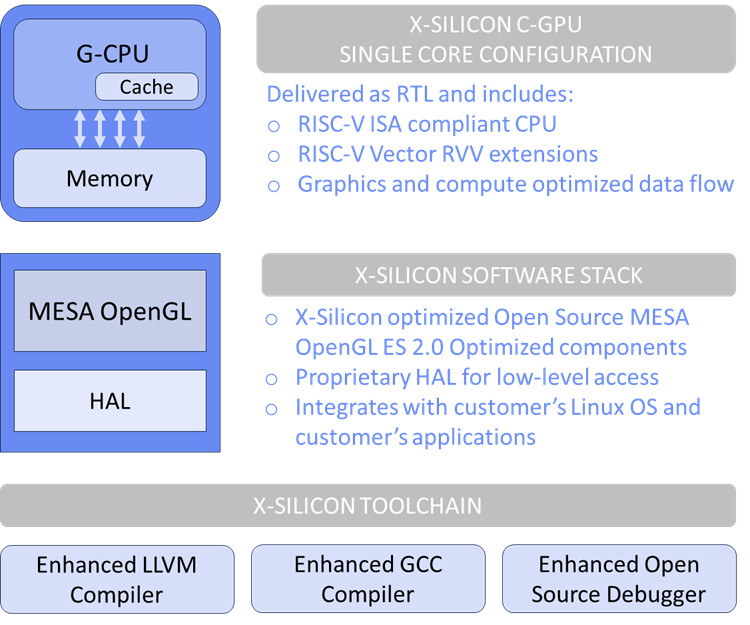
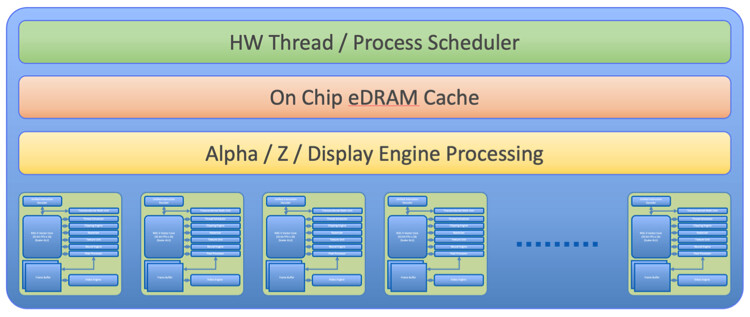
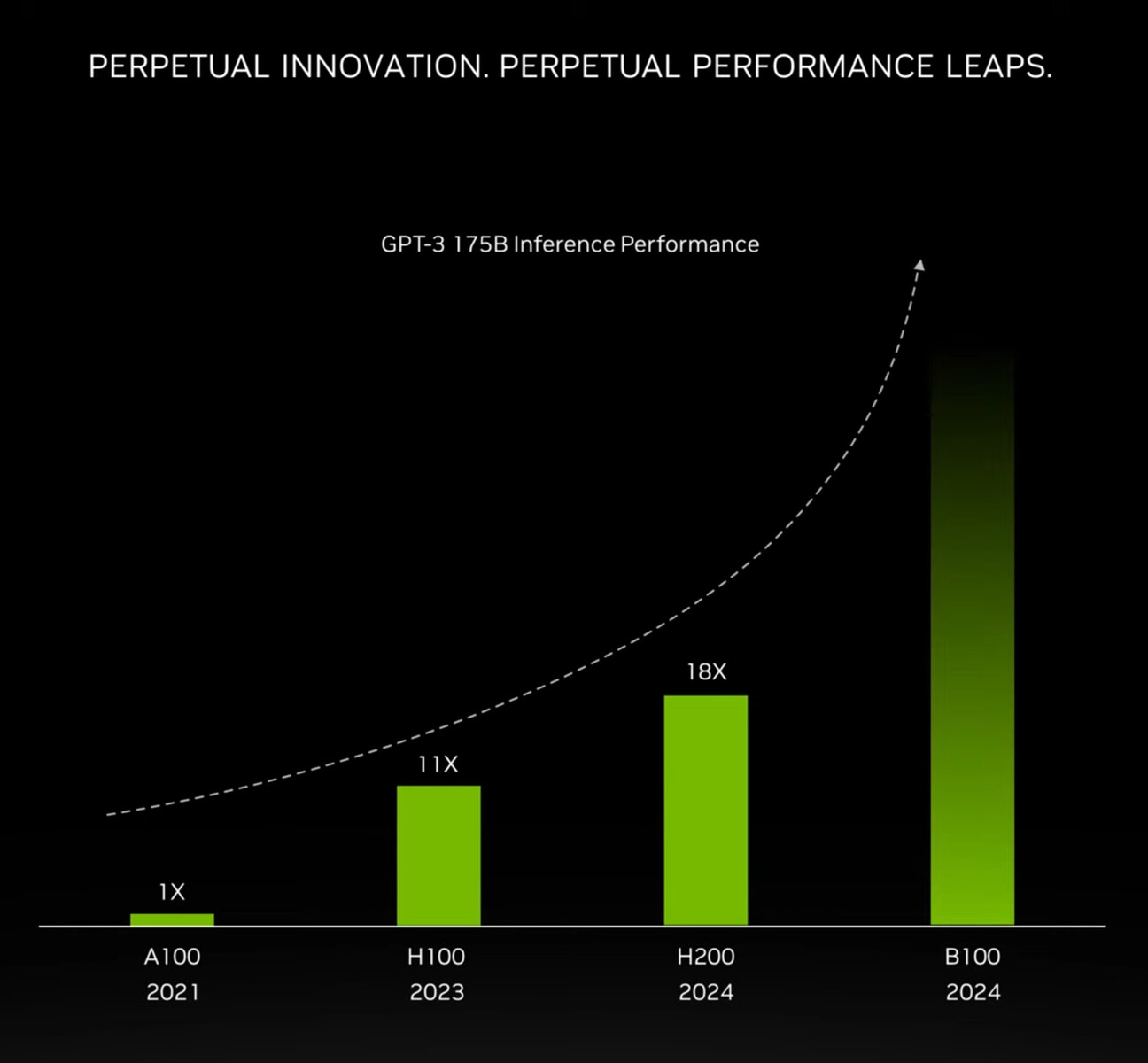
TSMC today unveiled its newest semiconductor process, advanced packaging, and 3D IC technologies for powering the next generation of AI innovations with silicon leadership at the Company's 2024 North America Technology Symposium. TSMC debuted the TSMC A16 technology, featuring leading nanosheet transistors with innovative backside power rail solution for production in 2026, bringing greatly improved logic density and performance. TSMC also introduced its System-on-Wafer (TSMC-SoW) technology, an innovative solution to bring revolutionary performance to the wafer level in addressing the future AI requirements for hyperscaler datacenters.
This year marks the 30th anniversary of TSMC's North America Technology Symposium, and more than 2,000 attended the event, growing from less than 100 attendees 30 years ago. The North America Technology Symposium in Santa Clara, California kicks off TSMC Technology Symposiums around the world in the coming months. The symposium also features an "Innovation Zone," designed to highlight the technology achievements of our emerging start-up customers.
This year marks the 30th anniversary of TSMC's North America Technology Symposium, and more than 2,000 attended the event, growing from less than 100 attendees 30 years ago. The North America Technology Symposium in Santa Clara, California kicks off TSMC Technology Symposiums around the world in the coming months. The symposium also features an "Innovation Zone," designed to highlight the technology achievements of our emerging start-up customers.