Ayar Labs Partners with NVIDIA to Deliver Light-Based Interconnect for AI Architectures
Ayar Labs, the leader in chip-to-chip optical connectivity, is developing with NVIDIA groundbreaking artificial intelligence (AI) infrastructure based on optical I/O technology to meet future demands of AI and high performance computing (HPC) workloads. The collaboration will focus on integrating Ayar Labs' technology to develop scale-out architectures enabled by high-bandwidth, low-latency and ultra-low-power optical-based interconnects for future NVIDIA products. Together, the companies plan to accelerate the development and adoption of optical I/O technology to support the explosive growth of AI and machine learning (ML) applications and data volumes.
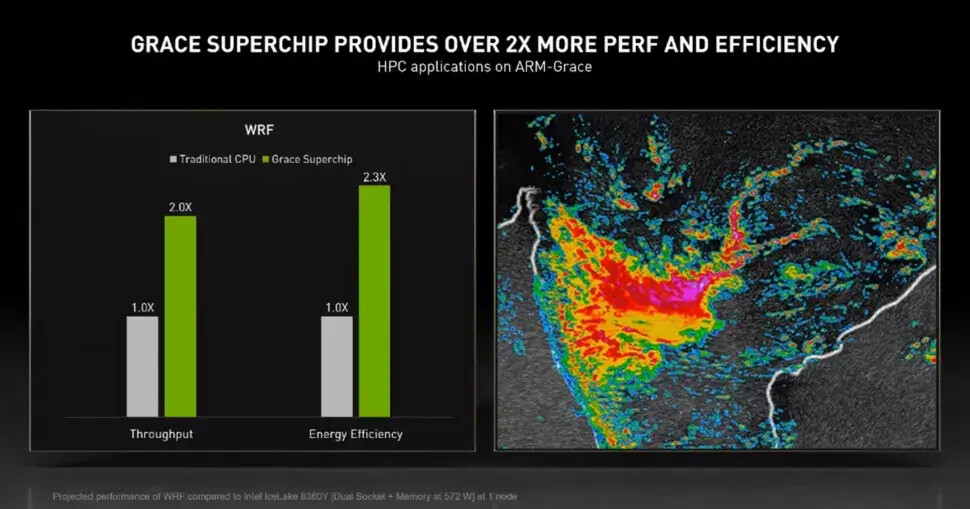
Optical I/O uniquely changes the performance and power trajectories of system designs by enabling compute, memory and networking ASICs to communicate with dramatically increased bandwidth, at lower latency, over longer distances and at a fraction of the power of existing electrical I/O solutions. The technology is also foundational to enabling emerging heterogeneous compute systems, disaggregated/pooled designs, and unified memory architectures that are critical to accelerating future data center innovation.
Optical I/O uniquely changes the performance and power trajectories of system designs by enabling compute, memory and networking ASICs to communicate with dramatically increased bandwidth, at lower latency, over longer distances and at a fraction of the power of existing electrical I/O solutions. The technology is also foundational to enabling emerging heterogeneous compute systems, disaggregated/pooled designs, and unified memory architectures that are critical to accelerating future data center innovation.