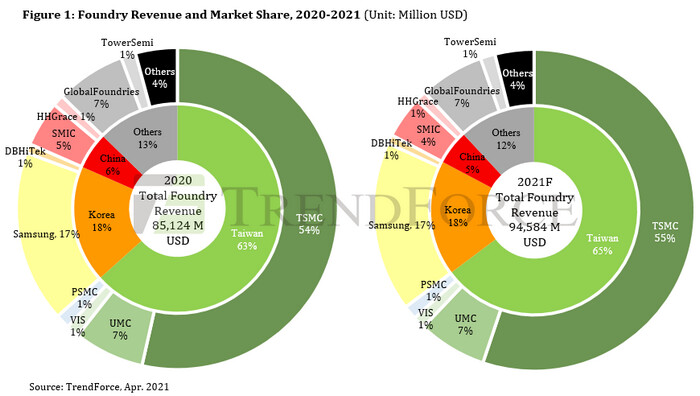
UK Competition Regulator Probes AMD's Buyout of Xilinx
British competition regulator Competition and Markets Authority (CMA) on Monday, launched an enquiry into the ramifications of AMD's buy-out of FPGA maker Xilinx. The agency is soliciting opinions from the public on whether the $35 billion all-stock purchase will make goods and services less competitive for the UK. Unlike NVIDIA's Arm buyout the Xilinx acquisition is seeing no opposition from tech-giants. The Register notes that AMD could combine Xilinx's FPGAs with its x86 CPU and RDNA SIMD to create highly customizable HPC accelerators. AMD president Dr Lisa Su said "By combining our world-class engineering team and deep domain expertise, we will create an industry leader with the vision, talent and scale to define the future of high performance computing."