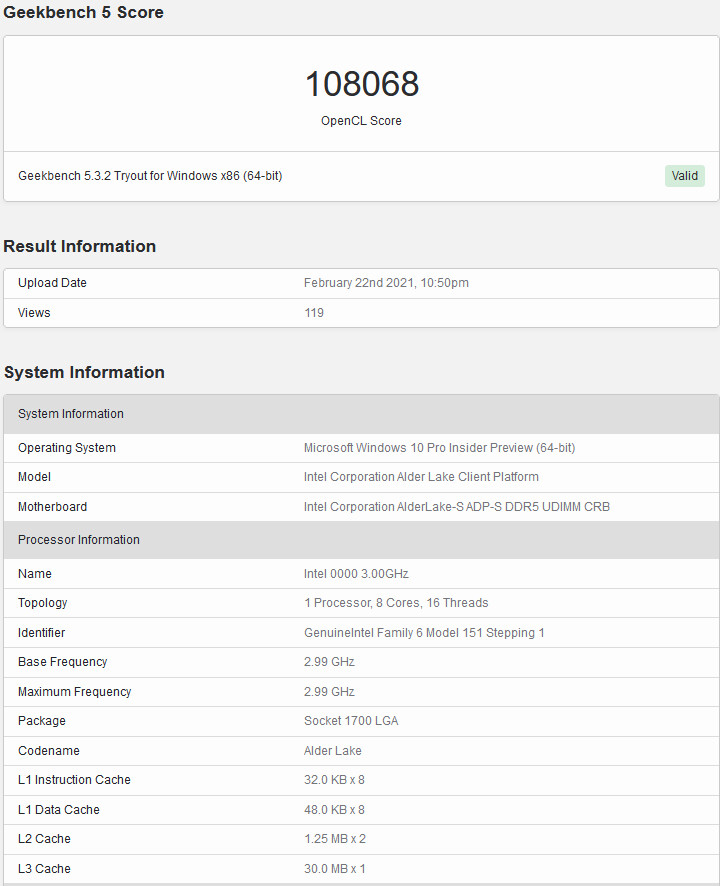
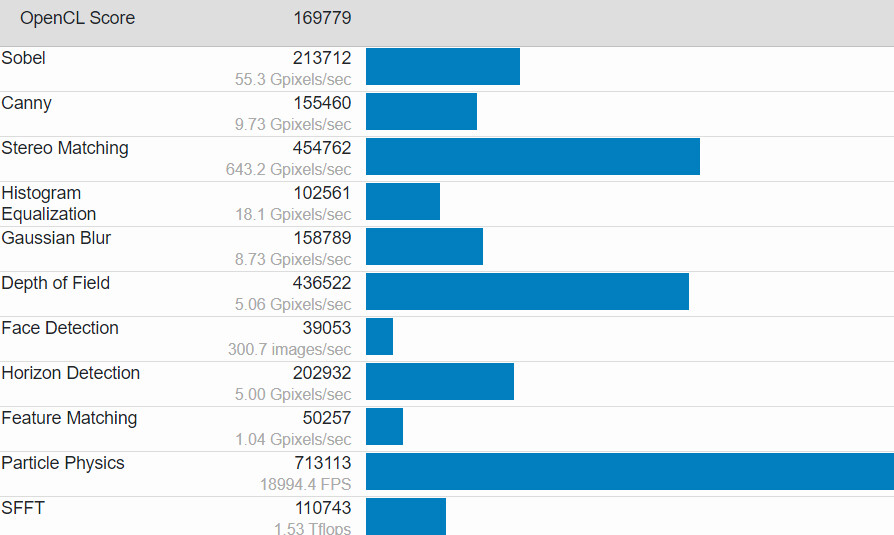
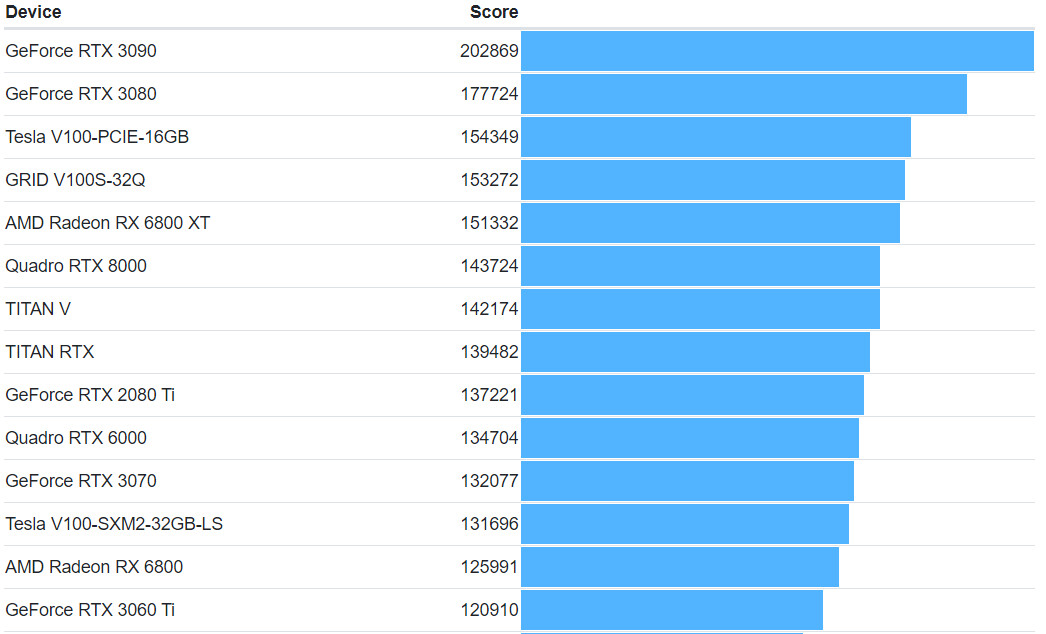
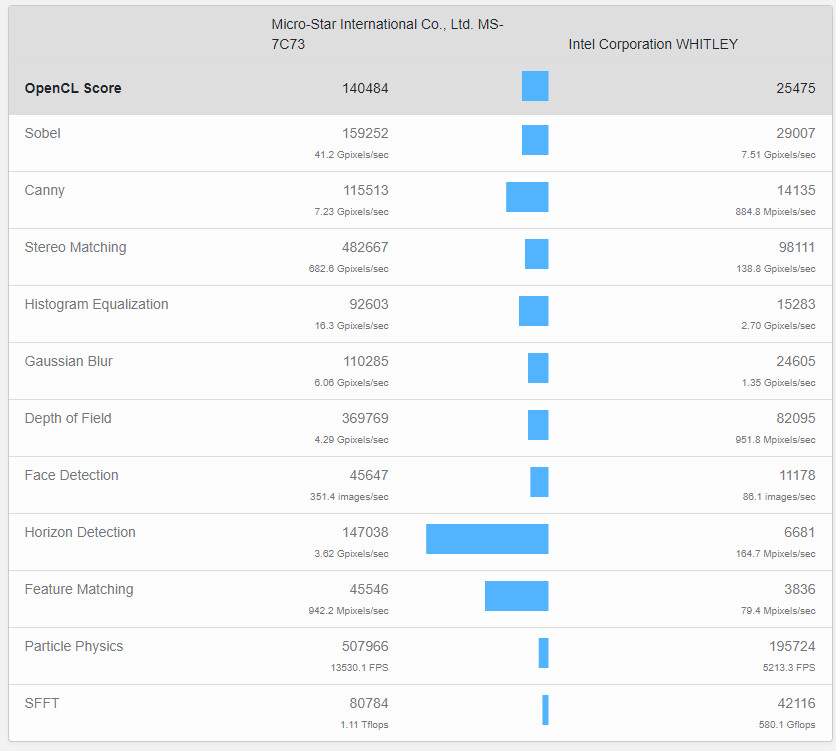
X-Silicon Startup Wants to Combine RISC-V CPU, GPU, and NPU in a Single Processor
While we are all used to having a system with a CPU, GPU, and, recently, NPU—X-Silicon Inc. (XSi), a startup founded by former Silicon Valley veterans—has unveiled an interesting RISC-V processor that can simultaneously handle CPU, GPU, and NPU workloads in a chip. This innovative chip architecture, which will be open-source, aims to provide a flexible and efficient solution for a wide range of applications, including artificial intelligence, virtual reality, automotive systems, and IoT devices. The new microprocessor combines a RISC-V CPU core with vector capabilities and GPU acceleration into a single chip, creating a versatile all-in-one processor. By integrating the functionality of a CPU and GPU into a single core, X-Silicon's design offers several advantages over traditional architectures. The chip utilizes the open-source RISC-V instruction set architecture (ISA) for both CPU and GPU operations, running a single instruction stream. This approach promises lower memory footprint execution and improved efficiency, as there is no need to copy data between separate CPU and GPU memory spaces.
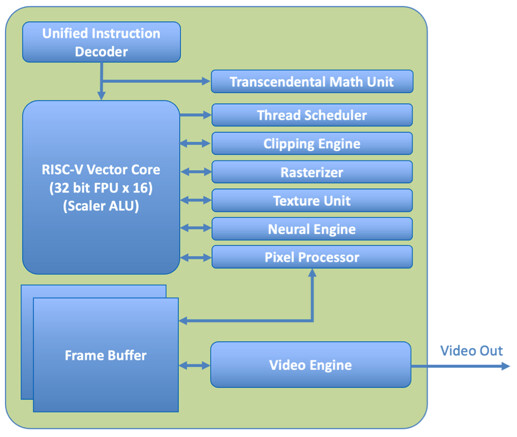
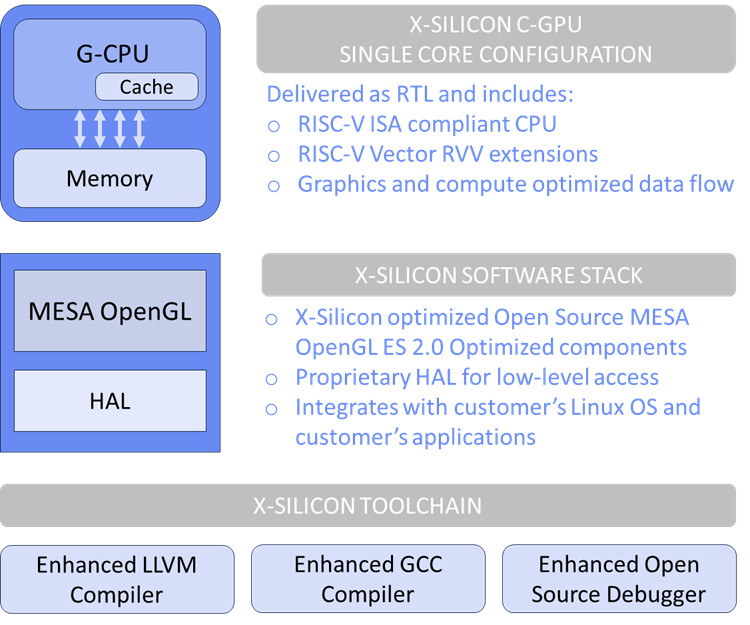
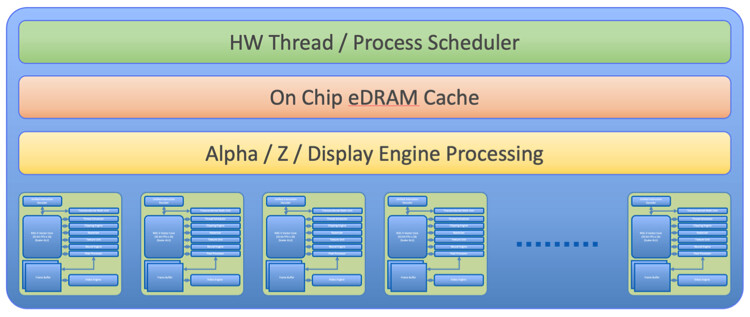
Called the C-GPU architecture, X-Silicon uses RISC-V Vector Core, which has 16 32-bit FPUs and a Scaler ALU for processing regular integers as well as floating point instructions. A unified instruction decoder feeds the cores, which are connected to a thread scheduler, texture unit, rasterizer, clipping engine, neural engine, and pixel processors. All is fed into a frame buffer, which feeds the video engine for video output. The setup of the cores allows the users to program each core individually for HPC, AI, video, or graphics workloads. Without software, there is no usable chip, which prompts X-Silicon to work on OpenGL ES, Vulkan, Mesa, and OpenCL APIs. Additionally, the company plans to release a hardware abstraction layer (HAL) for direct chip programming. According to Jon Peddie Research (JPR), the industry has been seeking an open-standard GPU that is flexible and scalable enough to support various markets. X-Silicon's CPU/GPU hybrid chip aims to address this need by providing manufacturers with a single, open-chip design that can handle any desired workload. The XSi gave no timeline, but it has plans to distribute the IP to OEMs and hyperscalers, so the first silicon is still away.


Called the C-GPU architecture, X-Silicon uses RISC-V Vector Core, which has 16 32-bit FPUs and a Scaler ALU for processing regular integers as well as floating point instructions. A unified instruction decoder feeds the cores, which are connected to a thread scheduler, texture unit, rasterizer, clipping engine, neural engine, and pixel processors. All is fed into a frame buffer, which feeds the video engine for video output. The setup of the cores allows the users to program each core individually for HPC, AI, video, or graphics workloads. Without software, there is no usable chip, which prompts X-Silicon to work on OpenGL ES, Vulkan, Mesa, and OpenCL APIs. Additionally, the company plans to release a hardware abstraction layer (HAL) for direct chip programming. According to Jon Peddie Research (JPR), the industry has been seeking an open-standard GPU that is flexible and scalable enough to support various markets. X-Silicon's CPU/GPU hybrid chip aims to address this need by providing manufacturers with a single, open-chip design that can handle any desired workload. The XSi gave no timeline, but it has plans to distribute the IP to OEMs and hyperscalers, so the first silicon is still away.