Tuesday, November 26th 2019

HP Enterprise SSD Firmware Bug Causes them to Fail at 32,768 Hours of Use, Fix Released
HP issued a warning to its customers that some of its SAS SSDs come with a bug that causes them to fail at exactly 32,768 hours of use. For an always-on or high-uptime server, this translates to 3 years, 270 days and 8 hours of usage. The affected models of SSDs are shipped in many of HP's flagship server and storage products, spanning its HPE ProLiant, Synergy, Apollo, JBOD D3xxx, D6xxx, D8xxx, MSA, StoreVirtual 4335 and StoreVirtual 3200 product-lines.
HP has released an SSD firmware update that fixes this bug and cannot stress the importance of deploying the update enough. This is because once a drive hits the 32,768-hour literal deadline and breaks down, both the drive and the data on it become unrecoverable. There is no other mitigation to this bug than the firmware update. HP released easy to use online firmware update tools that let admins update firmware of their drivers from within their OS. The online firmware update tools support Linux, Windows, and VMWare. Below is a list of affected drives. Get the appropriate firmware update from this page.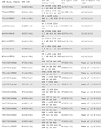
Source:
Bleeping Computer
HP has released an SSD firmware update that fixes this bug and cannot stress the importance of deploying the update enough. This is because once a drive hits the 32,768-hour literal deadline and breaks down, both the drive and the data on it become unrecoverable. There is no other mitigation to this bug than the firmware update. HP released easy to use online firmware update tools that let admins update firmware of their drivers from within their OS. The online firmware update tools support Linux, Windows, and VMWare. Below is a list of affected drives. Get the appropriate firmware update from this page.

27 Comments on HP Enterprise SSD Firmware Bug Causes them to Fail at 32,768 Hours of Use, Fix Released
I would be curious what controller the drives use. It sounds like it triggers a SSD controller reset, judging from the value I can only assume it is a "value wrap" situation which the controller drtects and freaks out about, triggering a drive wide reset including the onboard encryption keys.
If so... Much dumb, very dead, WOW.
There you have your proof, that planned obscolescence on purpose exists.
I am sure they implemented this on purpose, just didnt expect anyone to find out, why the drives die shortly after the warranty period expires...
I hope someone sues HP, and forces all other manufacturers too, to stop this practice.
To further the conspiracies tho, I remember back in the college days(early 2000s) I had Wifi routers from Netgear and D-Link that would die literally days after the 1 year warranty was up. 3 years straight IIRC. I then bought a Linksys WRT54G (model?) and reflashed it to that third party DD-WRT firmware, and it's still running to this day at my in-laws far as I know (~10+ years?).
:eek::eek::eek:
Backup Restore hell awaits...
Not acceptable at all from HP...
Brickity brick...
Those who wants to see what happens can run this:
This will output:
Before: 32767
After: -32768
This is a well known rookie mistake, but there are in fact two mistakes here; 1) the small range for the integer and 2) whatever caused the crash after the overflow, where the second one is the serious one. This kind of bug is inexcusable in critical software like firmware.
So how did this mistake pass code review? Well, either the coder explicitly used a fixed precision integer type like int16_t, which should have made the overflow pretty obvious, or used int and the compiler chose a 16-bit integer for the embedded platform. For native code, I usually recommend using fixed precision integer types over int whenever possible as it makes potential overflows much more obvious, and it forces the coder to consciously choose an appropriate range.
Not comparing the practices by any means, just saying yep, it has.
That’s a pretty good run. But if you want to go the conspiracy route, I’ll step out of your way. I’m not one to limit thiose who have a quest to tilt with windmills.
Never understood how it became a worldwide advisory to use same drives in mirrored arrays.
P.S.
HP and HPE split 4 years ago, just a reminder.