Friday, September 15th 2023

Apple A17 Pro SoC Within Reach of Intel i9-13900K in Single-Core Performance
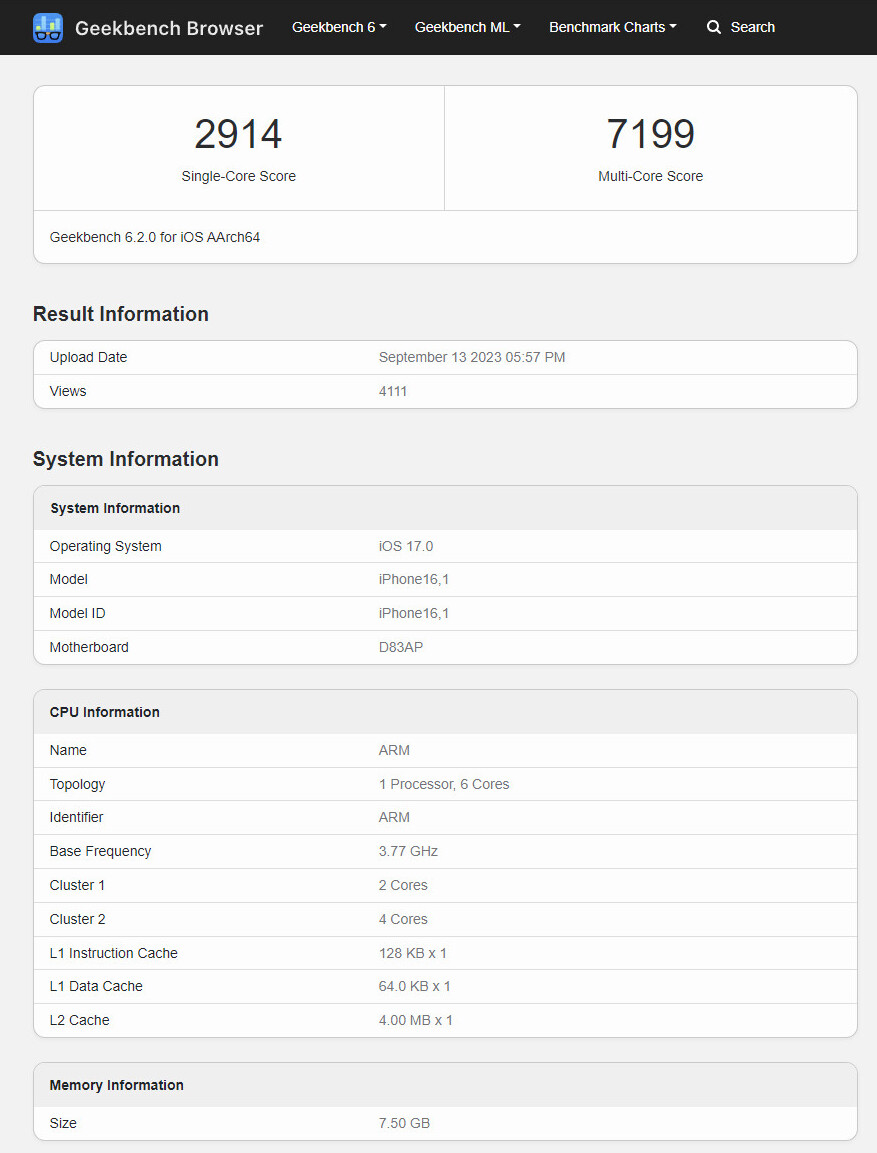
An Apple "iPhone16,1" was put through the Geekbench 6.2 gauntlet earlier this week—according to database info this pre-retail sample was running a build of iOS 17.0 (currently in preview) and its logic board goes under the "D83AP" moniker. It is interesting to see a unit hitting the test phase only a day after the unveiling of Apple's iPhone 15 Pro and Max models—the freshly benched candidate seems to house an A17 Pro system-on-chip. The American tech giant has set lofty goals for said flagship SoC, since it is "the industry's first 3-nanometer chip. Continuing Apple's leadership in smartphone silicon, A17 Pro brings improvements to the entire chip, including the biggest GPU redesign in Apple's history. The new CPU is up to 10 percent faster with microarchitectural and design improvements, and the Neural Engine is now up to 2x faster."
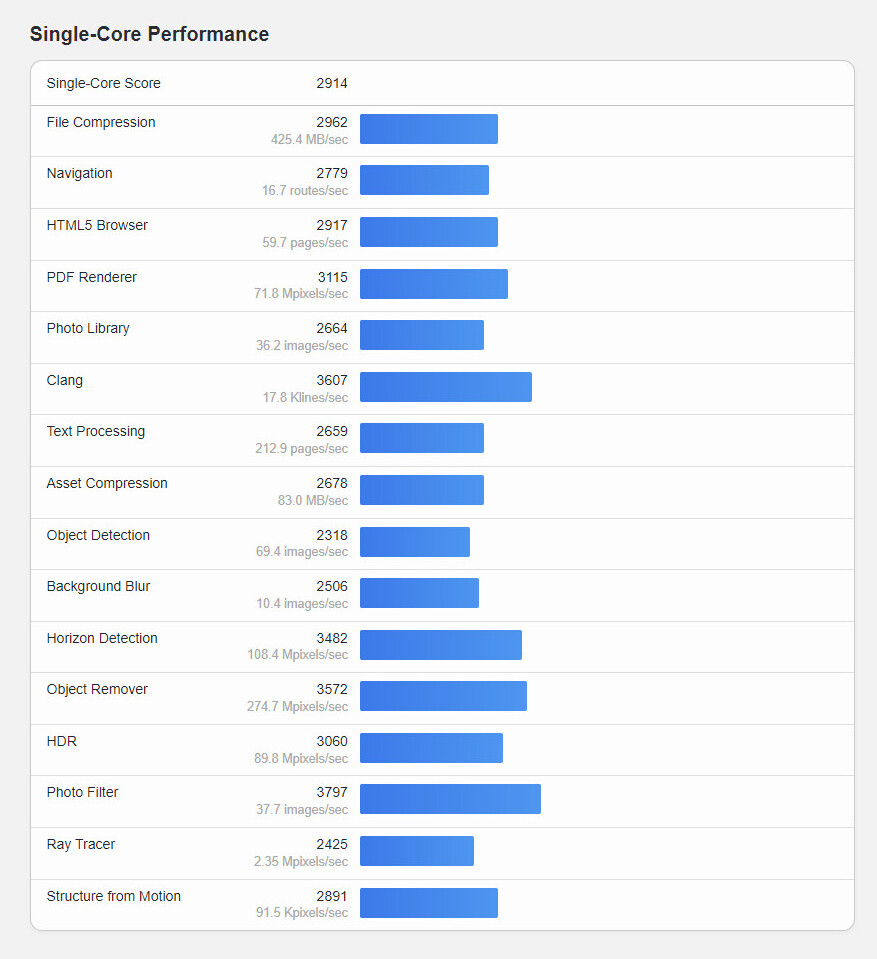
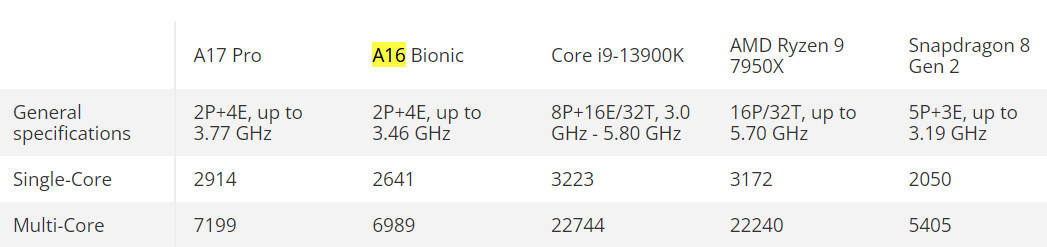
Tech news sites have pored over the leaked unit's Geekbench 6.2 scores—its A17 Pro chipset (TSMC N3) surpasses the previous generation A16 Bionic (TSMC N4) by 10% in single-core stakes. Apple revealed this performance uplift during this week's iPhone "Wonderlust" event, so the result is not at all surprising. The multi-score improvement is a mere ~3%, suggesting that only minor tweaks have been made to the underlying microarchitecture. The A17 Pro beats Qualcomm's Snapdragon 8 Gen 2 in both categories—2914 vs. 2050 (SC) and 7199 vs. 5405 (MC) respectively. Spring time leaks indicated that the "A17 Bionic" was able to keep up with high-end Intel and AMD desktop CPUs in terms of single-core performance—the latest Geekbench 6.2 entry semi-confirms those claims. The A17 Pro's single-threaded performance is within 10% of Intel Core i9-13900K and Ryzen 9 7950X processors. Naturally, Apple's plucky mobile chip cannot put up a fight in the multi-core arena, additionally Tom's Hardware notes another catch: "A17 Pro operates at 3.75 GHz, according to the benchmark, whereas its mighty competitors work at about 5.80 GHz and 6.0 GHz, respectively."



Sources:
Tom's Hardware, Geekbench, Techspot, Wccftech
Tech news sites have pored over the leaked unit's Geekbench 6.2 scores—its A17 Pro chipset (TSMC N3) surpasses the previous generation A16 Bionic (TSMC N4) by 10% in single-core stakes. Apple revealed this performance uplift during this week's iPhone "Wonderlust" event, so the result is not at all surprising. The multi-score improvement is a mere ~3%, suggesting that only minor tweaks have been made to the underlying microarchitecture. The A17 Pro beats Qualcomm's Snapdragon 8 Gen 2 in both categories—2914 vs. 2050 (SC) and 7199 vs. 5405 (MC) respectively. Spring time leaks indicated that the "A17 Bionic" was able to keep up with high-end Intel and AMD desktop CPUs in terms of single-core performance—the latest Geekbench 6.2 entry semi-confirms those claims. The A17 Pro's single-threaded performance is within 10% of Intel Core i9-13900K and Ryzen 9 7950X processors. Naturally, Apple's plucky mobile chip cannot put up a fight in the multi-core arena, additionally Tom's Hardware notes another catch: "A17 Pro operates at 3.75 GHz, according to the benchmark, whereas its mighty competitors work at about 5.80 GHz and 6.0 GHz, respectively."

46 Comments on Apple A17 Pro SoC Within Reach of Intel i9-13900K in Single-Core Performance
We're already in a time where basically 2 sizes of RAM makes sense for DDR5 (32 or 64 GB), at least for consumer desktops.
Now imagine if intel and AMD moved to an "embedded" CPU design where you buy the whole CPU+RAM block to be slotted into the motherboard, kinda like GPUs are made where you have a reference design and board partners make their own version with the chips sourced by AMD/intel.
The RAM slots could be replaced by SSDs, secondary expansion memory or other similar stuff.
Same applies to the workstation CPU's they have. All productivity related software incorporate some sort of computing these days... let it be AI denoise etc... they don't have AMD or NVIDA cards to have compute cores now... they predicted it right to incorporate into the CPU clusters and actually the Neural Engines ain't that bad.
Imagine that backlash that your new shiny macs could do properly Adobe tasks that use compute in timid fashion? It would be a disaster.
Well said.
I'm by no means an Apple fanatic, I will always buy a PC. However, you have to hand it to their engineers... they're world class.
You forget that apple charge a certain tax - and if you buy a phone, it's usually a 100$ more for just 64GB / 128GB of storage extra.
There's equipment already having memory on the same chip, such as the PS3 GPU.
Apple makes CPU's quite efficient - and to be honest, i really was suprised after having to replace the Macbook 13 inch battery - to find a board the size of a shoe:
That is packing everything - from CPU to Memory and Graphics. And fits in between the screen and battery.
It was a tough job to actually accomplish since it was my first mac's battery replacement. But geezus the super tiny screws at the size of avg flees n stuff.
Apple has some very skilled engineers.
Anyway, I would say that this software is at least inadequate... :rolleyes:
Broadly speaking, chip pipelines are either wide and shallow or narrow and deep. Within the same transistor budget, a wider decode with shorter pipelines means lower clocks while a narrower decode with longer pipelines means higher clocks.
Both AMD and Intel and x86 in general use narrow and deep.
AMD and Intel design for higher clocks, they are 4 (Zen) and 1+3 (Intel) wide decode pipelines. Apple was at 7 wide with the A11/A12 and 8 wide back with the A14, not sure where they are now. Samsung was at 6 a couple of years ago and generic ARM Cortex was 6.
This is why clock-for-clock comparisons are meaningless. These are high level design choices the engineers made for their use cases. Apple is designing for lower clocks and higher efficiency, AMD and Intel are mostly going for raw performance hence higher clocks.
Also, since we're talking ARM... your cellphone also packs the CPU, memory and graphics in a much smaller board. ;) :D
Maybe they've added more arithmetic units so the pipeline is more symmetrical, but I can't see how going much wider will trigger that much of performance improvement.