flashfrenzy
New Member
- Joined
- Mar 22, 2021
- Messages
- 19 (0.01/day)
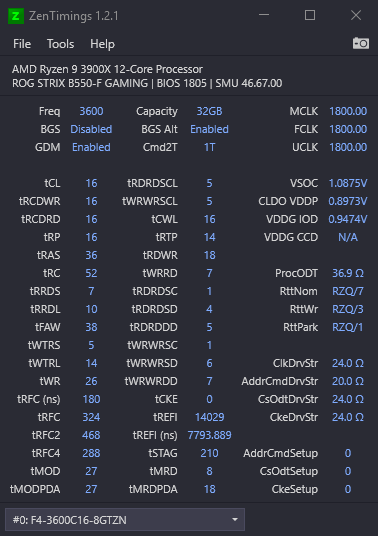
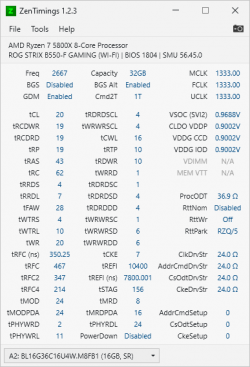
I just finished building a new system this last week and twice now I've had hard resets playing Shadow of the Tomb Raider. In one case it was after an hour or two and the second time it was within ~15 min. The second time I had both hwinfo and gpu-z logging running. Everything seems fine from the logs (links below) but maybe someone can see something I don't. I don't think the restart is thermal related. The CPU was at around 50C at the time of the restart. In games it seems to be around 50-60C and idle in the low 30s. Since the restarts I completely cleared the CMOS and went 100% stock (no XMP). Since then, I haven't seen any restarts but I've been running prime95 tests and always run into errors within 2 hours. The CPU does get very hot in the tests (up to 90C) but I'm not sure if this is typical or not for prime95 since my normal load temps seem fine. I've also run memtest86 with XMP enabled and FCLK at 1800 and 3 passes (3 and half hours) there were no errors so I don't suspect the RAM at this point. My last runs of P95 I had the case open with a giant fan blowing in. It didn't really seem to affect anything. My GPU temps were way down (irrelevant, I know) but CPU was unaffected. I'm kind of at a loss of what to look for or do at this point. Any suggestions/advice would be greatly appreciated.
Component rundown: 5800x, ASUS b550-f mobo, EVGA RTX3060, Arctic Freezer 280 AIO, Super Flower Leadex III 850W, 32 GB Crucial Ballistix CL16 3600
BIOS and drivers are 100% up to date.
hwinfo logs: https://docs.google.com/spreadsheets/d/1ggHi0jCAs5BACIKK_BJT7cCELAP9mVAvYHBBip8FtSk/edit?usp=sharing
gpu-z logs: https://docs.google.com/spreadsheets/d/1Fc2VbCaYCh_FgW8JDO1Q9o771ZlAXU5dhhazVmOR5_Y/edit?usp=sharing
Component rundown: 5800x, ASUS b550-f mobo, EVGA RTX3060, Arctic Freezer 280 AIO, Super Flower Leadex III 850W, 32 GB Crucial Ballistix CL16 3600
BIOS and drivers are 100% up to date.
hwinfo logs: https://docs.google.com/spreadsheets/d/1ggHi0jCAs5BACIKK_BJT7cCELAP9mVAvYHBBip8FtSk/edit?usp=sharing
gpu-z logs: https://docs.google.com/spreadsheets/d/1Fc2VbCaYCh_FgW8JDO1Q9o771ZlAXU5dhhazVmOR5_Y/edit?usp=sharing