You CLAIM a core is <whatever you claimed> but unfortunately what you claimed is not true.
What has always been the meaning of a "core" is the circuit used for the management of a thread and its memory context. This usually includes the datapath, control, and bus. This usually excludes the caches and accelerators (incl. FPU).
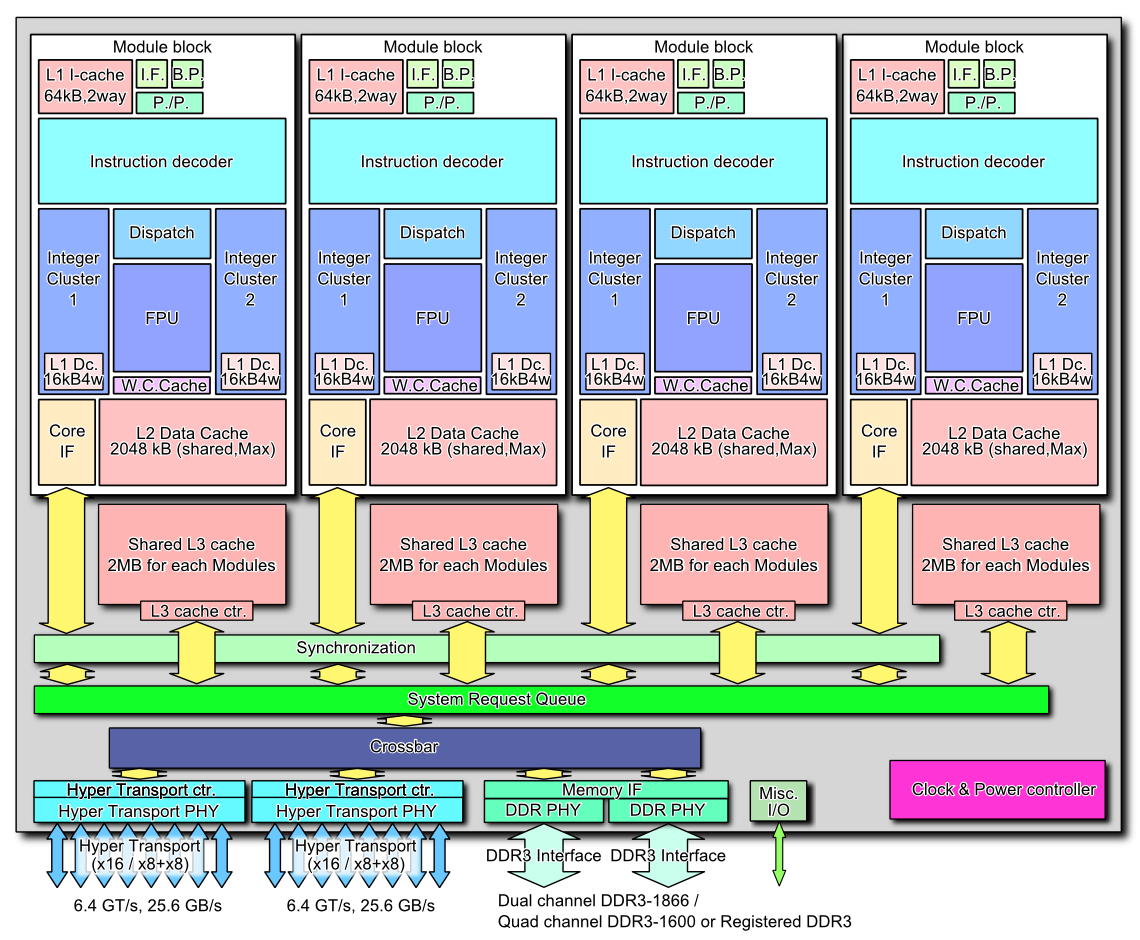
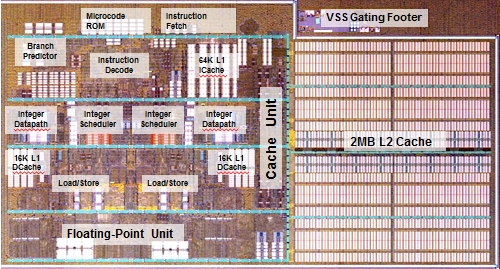
To be more precise, a processor can be partitioned into the following functional units: data cache, instruction data, { control unit, instruction bus, data bus, (integer) datapath } and (floating point) accelerator datapath. Those inside the {} above form a "core". You may ask: why is integer datapath special? Because any process (thread + memory context) is *always* managed by the integer datapath. Any branch instruction, ILP, OOO, speculation, is performed by the integer datapath.
So the question to ask is how many sets of the {} above does a Bulldozer module have? The answer is 2. There are two cores. This has nothing to do with marketing. It's a technical definition.
Now, you don't need to like this definition. You can be bone headed enough to insist on your own definition of core. That is fine. Just like you can insist 1+1=1. Perhaps you are right in an alternative naming convention (if `+' means the logic-or to you), but you should at least understand that a Bulldozer module is said to have "two cores" for very with sound technical reasons.