Arm Launches Next-Generation Neoverse CSS V3 and N3 Designs for Cloud, HPC, and AI Acceleration
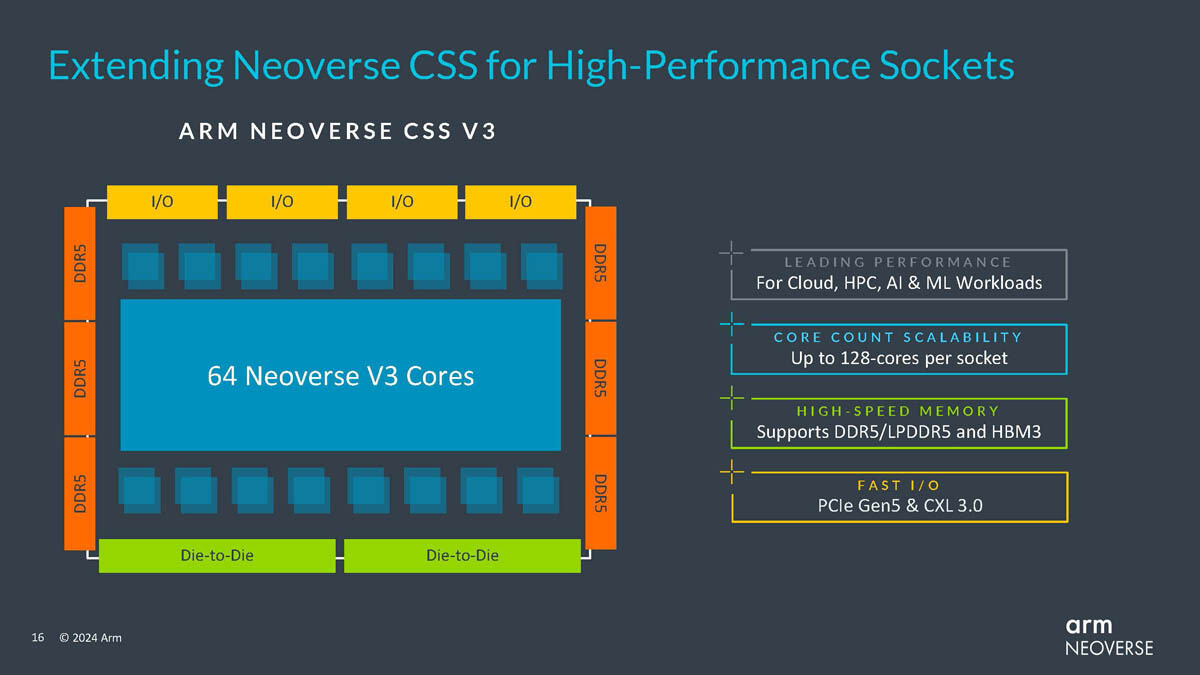
Last year, Arm introduced its Neoverse Compute Subsystem (CSS) for the N2 and V2 series of data center processors, providing a reference platform for the development of efficient Arm-based chips. Major cloud service providers like AWS with Graviton 4 and Trainuium 2, Microsoft with Cobalt 100 and Maia 100, and even NVIDIA with Grace CPU and Bluefield DPUs are already utilizing custom Arm server CPU and accelerator designs based on the CSS foundation in their data centers. The CSS allows hyperscalers to optimize Arm processor designs specifically for their workloads, focusing on efficiency rather than outright performance. Today, Arm has unveiled the next generation CSS N3 and V3 for even greater efficiency and AI inferencing capabilities. The N3 design provides up to 32 high-efficiency cores per die with improved branch prediction and larger caches to boost AI performance by 196%, while the V3 design scales up to 64 cores and is 50% faster overall than previous generations.
Both the N3 and V3 leverage advanced features like DDR5, PCIe 5.0, CXL 3.0, and chiplet architecture, continuing Arm's push to make chiplets the standard for data center and cloud architectures. The chiplet approach enables customers to connect their own accelerators and other chiplets to the Arm cores via UCIe interfaces, reducing costs and time-to-market. Looking ahead, Arm has a clear roadmap for its Neoverse platform. The upcoming CSS V4 "Adonis" and N4 "Dionysus" designs will build on the improvements in the N3 and V3, advancing Arm's goal of greater efficiency and performance using optimized chiplet architectures. As more major data center operators introduce custom Arm-based designs, the Neoverse CSS aims to provide a flexible, efficient foundation to power the next generation of cloud computing.


Both the N3 and V3 leverage advanced features like DDR5, PCIe 5.0, CXL 3.0, and chiplet architecture, continuing Arm's push to make chiplets the standard for data center and cloud architectures. The chiplet approach enables customers to connect their own accelerators and other chiplets to the Arm cores via UCIe interfaces, reducing costs and time-to-market. Looking ahead, Arm has a clear roadmap for its Neoverse platform. The upcoming CSS V4 "Adonis" and N4 "Dionysus" designs will build on the improvements in the N3 and V3, advancing Arm's goal of greater efficiency and performance using optimized chiplet architectures. As more major data center operators introduce custom Arm-based designs, the Neoverse CSS aims to provide a flexible, efficient foundation to power the next generation of cloud computing.